

研究人员提出了一种多尺度高效率的新模型FAMED-Net
电子说
描述
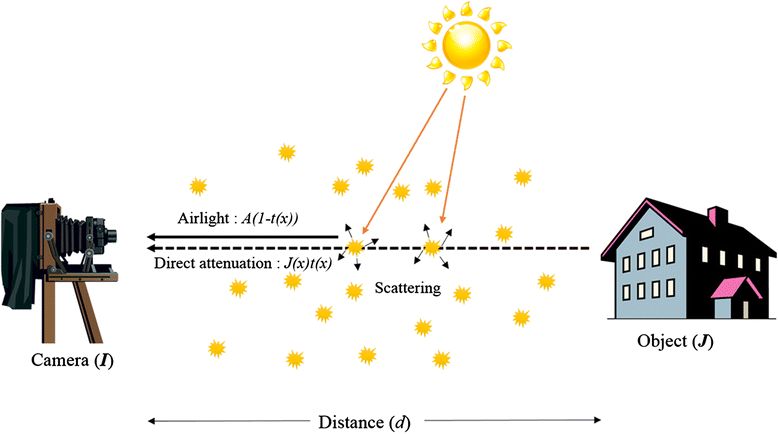
空气质量对于照片的图像质量有着很大的影响,不仅是北方的雾霾让相机无法看清世界,高山海边的浓雾也会遮挡相机探索世界的好奇眼睛。这些天气状况会造成图像对比对下降、模糊和噪声,不仅大大削弱了图像的观感,同时也为高级机器视觉任务造成了很大的困难。
如果能将图像中的浓雾或雾霾去除,对于物体识别、目标跟踪检测等任务都有极大的提升。先前基于机器学习的方法在模型复杂度、计算效率和表达能力上都有着各自的缺点。
为了提高模型的表达能力和效率,来自悉尼大学的研究人员提出了一种多尺度高效率的新模型FAMED-Net,实现了轻量化高精度的单张图像去雾。
图像去雾
雾霾对于成像的影响主要来自于空气中的悬浮颗粒对于光线的吸收和散射,这些颗粒包括了微小液滴、灰尘和悬浮颗粒等,它们对于光线的影响造成了图像质量的退化。为了削减或去除这些影响,研究人员们开发出了一系列图像去雾算法,从单张或者多张雾霾图像中恢复出清晰的图像。
目前主流的方法分为三类:
一类是利用深度图等信息来辅助清晰图像的重建;
另一类方法是利用图像序列来重建某一场景的清晰图像;
最后一种方法是直接从单张RGB图像中重建出清晰的图像,而这也是最具实用性和应用前景的方法,更适合在多样性的条件下实时使用。
但由于从退化图像中恢复是一个ill-posed问题,图像去雾依旧面临着诸多挑战。为了同时考虑吸收引起的衰减和散射引起的散射效应,人们发现通过透射率图来间接实现清晰图像的估计,只要通过图像估计出了环境的透射率图、就可以根据图像退化的逆过程计算出清晰的图像。
人们从成像过程和基于学习的方式出发,分别提出了多种估计估算透射率和图像去雾的方法。其中有著名的暗通道去雾方法、色彩衰减先验方法、非局域先验假设等。虽然这些方法简单且有效,但它们都是基于某些统计特征的描述,对于某些比较特殊的图像就会失效。

清晰图像与雾图的暗通道,以及典型的暗通道去雾算法
而基于学习的方法采用了数据驱动的方法来学习出图像特征和透射率之间的关系,克服了手工选取先验特征的不足。随着深度学习的方法,这种方法朝着更强大的模型、更有效的合成方法与数据以及端到端的训练发展。
其中著名的方法包括从雾图中直接学习透射率的DehazeNet,多尺度架构的MSCNN,用于在不同的尺度上进行由粗糙到精细的回归过程。为了顾及大气光的影响,研究人员还提出了可以同时学习透射率图、大气光照和去雾图像的DCPDN网络。此外还包括了AOD-Net,GFN等方法使用了编码器解码器架构和对抗方法得到了很好的结果。
但这些方法却需要较大的内存和计算开销,使其在资源受限系统上应用受到了限制。为了解决这些问题实现快速高效的图像去雾,研究人员提出了一种适用于任意尺寸的单图像去雾方法FAMED-Net,其中包含了三个不同尺度的解码器以及融合模块用于直接学习除去雾后的图像。每个解码器由级联的逐点卷积和池化层构成并通过稠密链接复用特征信息。由于没有大型卷积的加入使得整个网络十分轻量和高效。
FAMED-Net
这一模型的主要思想是通过顾及雾图的透射率来计算去雾后的图像的,在了解网络架构之前我们需要先复习下图像在雾中的成像模型:
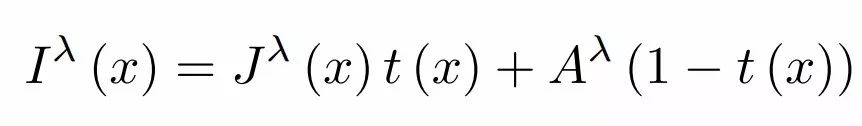
其中I是相机接受到的雾图,而J是场景原始信号,t代表环境的透射率,A则代表了大气光线。所有的lamda表示这些项都与波长相关,在图像中与RGB三个通道相关。研究人员将上面的模型进行了改进融合了大气光照影响和透射率图,并用统一的参数K表示,只要得到了K我们就可以通过观测到的雾图重建出清晰的图像:

于是FMAMED-Net的主要工作变成了从雾图中估计出场景对应的K map。
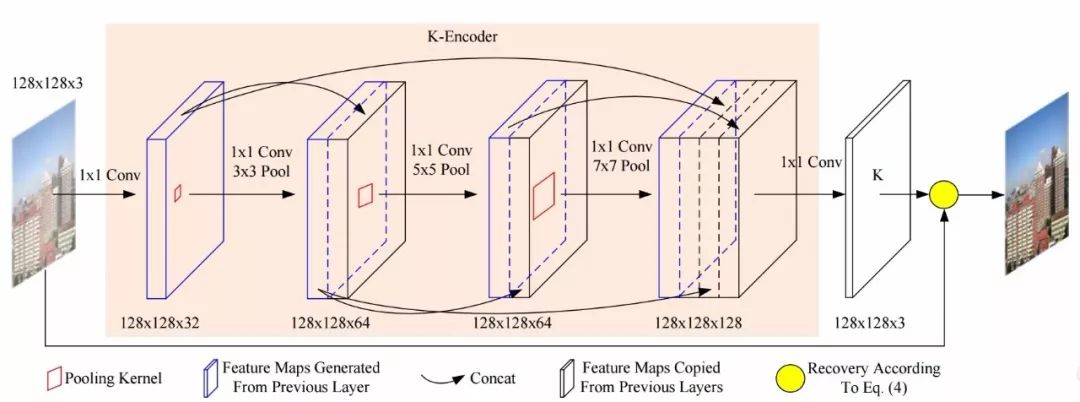
研究人员首先探索了从单尺度雾图中恢复清晰图像的过程。这一架构中,研究人员基于概率统计分析验证了基于统计学理论恢复清晰图像的过程,利用网络模型学习出不同层级的特征恢复场景中的K,随后基于上面的公式到场景的清晰图像。模型主要分为K编码器和K融合及解码器模块。在编码器部分通过稠密连接将不同层级的特征衔接在了一起,基于逐点卷积和池化操作在保持模型容量的同时代替了操作更为复杂的卷积操作,实现了更为紧致的结构。
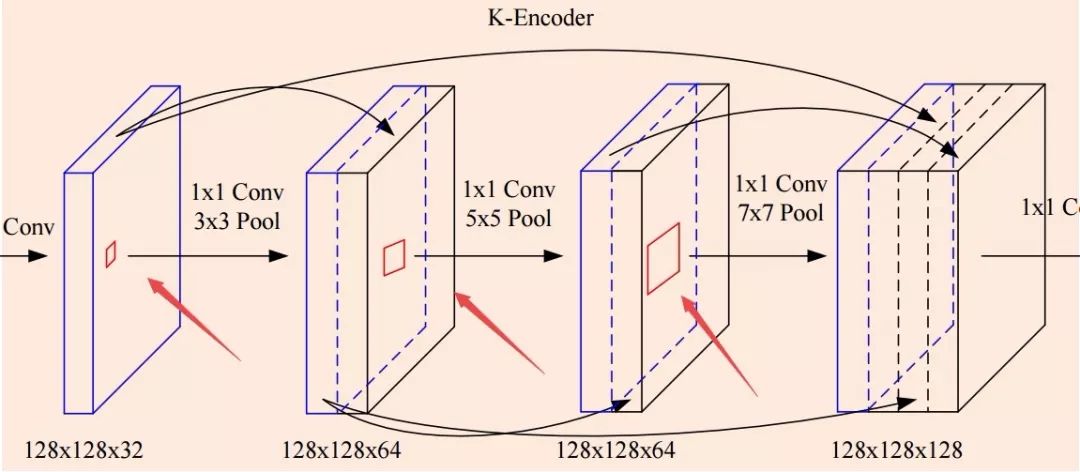
为了处理不同尺度带来的距离效应,研究人员还引入了高斯金字塔和拉普拉斯金字塔架构来得到更好的性能。在原图1/2,1/4高斯金字塔尺度上对K进行估计,并根据融合后的多尺度特征估计出更为可靠的K map。

如上图所示,不同尺度的图像分别估计自身尺度的K并与对应尺度的清晰图像计算L2损失。最后不同尺度下估计的K叠加并融合的到最终的Kfusion。拉普拉斯金字塔也基于相同的原理,与高斯金字塔唯一不同的是它的目标在于学习K的残差。这种多尺度的架构将为模型提供较大的感受野,在GP,LP模式下达到了52*52的大小。
结果
随后研究人员在RESIDE数据上进行了训练和测试,得到了很好的结果。
在真实世界图像上与不同算法的比较:
我们可以看到环境中估计出的透射率图,与直观感觉十分相近:
在实验中研究人员还发现,使用批归一化将有效提高模型的表现。同时更多的通道会为模型带来更强的表达能力。为了克服逐点卷积对于结构特征学习的劣势,研究人员在最开始加入了3*3的卷积层有效提升了模型的恢复能力。


这种基于多尺度编解码器的架构可以直接得到清晰的图像,通过逐点卷积和池化以及全连接的组合实现了高效运行和信息共享,能高速、准确地从雾图中得到清晰的图像。
-
无刷直流电机双闭环串级控制系统仿真研究2025-07-07 576
-
超分子聚集体的高效率RTP模型和思路2022-08-08 2827
-
MIT研究人员提出了一种制造软气动执行器的新方法2022-05-06 2782
-
请问怎样去设计一种高效率音频功率放大器?2021-06-02 2456
-
一种脱离预训练的多尺度目标检测网络模型2021-04-02 1754
-
研究人员们提出了一系列新的点云处理模块2019-08-02 3872
-
以色列研究人员开发出了一种能够识别不同刺激的新型传感系统2019-05-21 1356
-
研究人员共同提出了一种面向目标检测任务的新模块Res2Net2019-04-08 4752
-
一种新的基于电穿孔的皮肤高效核酸递送方法2018-05-10 6571
-
研究人员提出了一种柔性可拉伸扩展的多功能集成传感器阵列2018-01-24 8508
-
一种多尺度多视点特性视图生成方法的研究和应用_谢冰2017-03-15 840
-
一种高效率RFID手持机电源设计方案2011-08-18 3311
-
一种提高效率和减小电压纹波的电荷泵2009-12-14 895
全部0条评论

快来发表一下你的评论吧 !
