

研究人员们提出了PBA的方法来获取更为有效的数据增强策略
电子说
描述
近年来深度学习模型的飞速发展离不开庞大的数据体量和多样化的数据收集。收集大量的、丰富的数据是十分耗时耗力的工作,而数据增强则为研究人员们提供了另一种增加数据多样性的可能,无需真正收集数据即可得到较为丰富多样的训练数据。来自伯克利的研究人员们提出了PBA(Population Based Augmentation)的方法来获取更为有效的数据增强策略,并在实现同样效果下实现了1000x的加速。
数据增强
数据增强策略通常包括剪切、填充、翻转和旋转等,但这些基本策略对于深度网络的训练还是太简单,在对于数据增强策略和种类的研究相较于神经网络的研究还是太少了。
一些常见的数据增强方法
最近谷歌针对这方面进行了深入的探索性的研究,提出了AutoAugment方法并在CIFAR-10数据集上取得了很好的成果。
这篇论文利用了强化学习等方法来搜索更好的数据增强策略,基于RNN的控制器从搜索空间中预测增强策略,而一个固定架构的子网络则用于在增强的数据上进行训练收敛到精度R,最后利用精度R来作为奖励使得控制器寻求更好的数据增强策略。
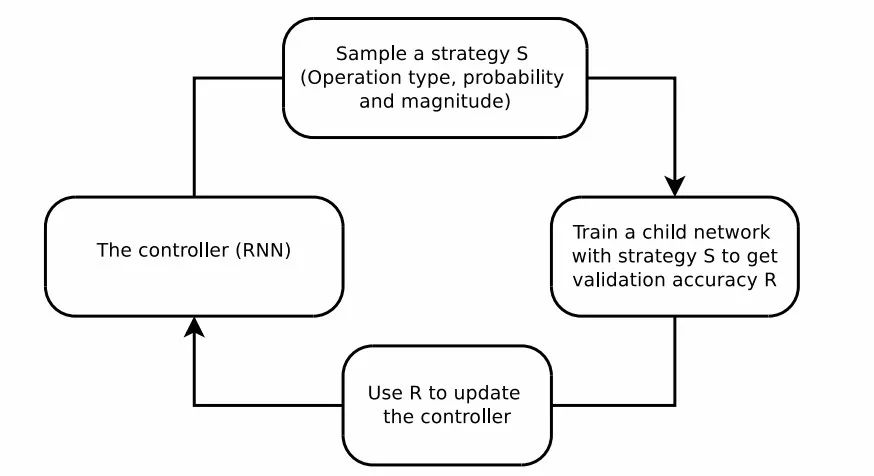
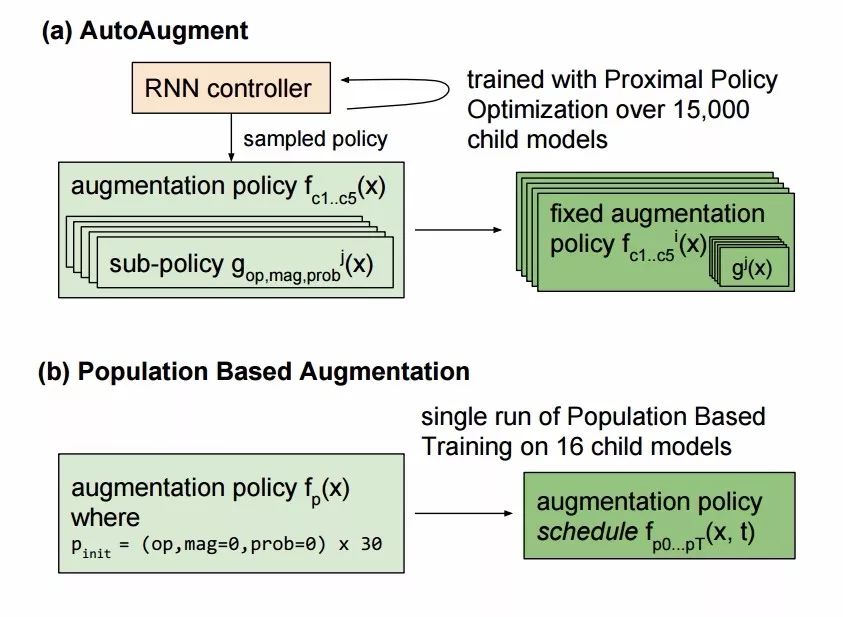
AutoAugment引入了16种几何、色彩变换并从中选择两种以固定的幅度来对每一批数据进行增强,所以高性能的增强方法可以通过强化学习直接由模型从数据中学习到。但这种方法的弊端在于它需要训练一万五千个模型到收敛,以便为强化学习模型收集足够的样本来学习数据增强策略。在样本间的计算不能共享,使得它要耗费15000个P100计算时来在ImageNet上实现较好的效果,即使在较小的CIFAR-10上也要消耗5000个GPU时(这意味着需要7500-37500美元的训练费用才能得到较好的数据增强策略)。如果可以将先前训练的策略迁移或共享到新的训练中去,就能更高效地实现数据增强策略的搜索与获取。
PBA算法
为了提高算法的效率,来自伯克利的研究人员提出了PBA算法,可以在比原算法少三个数量级的计算上获得相同的测试精度。
与AutoAugment不同,这种方法在多个小模型的副本上训练CIFAR-10数据集,只需要在Titan XP上训练5小时即可得到较好的数据增强策略,这一策略应用到CIFAR-100,并重新训练一个较大的网络可以获得十分有效的效果。与先前需要很多天的训练相比,这种方法耗时更短且得到的效果更好。
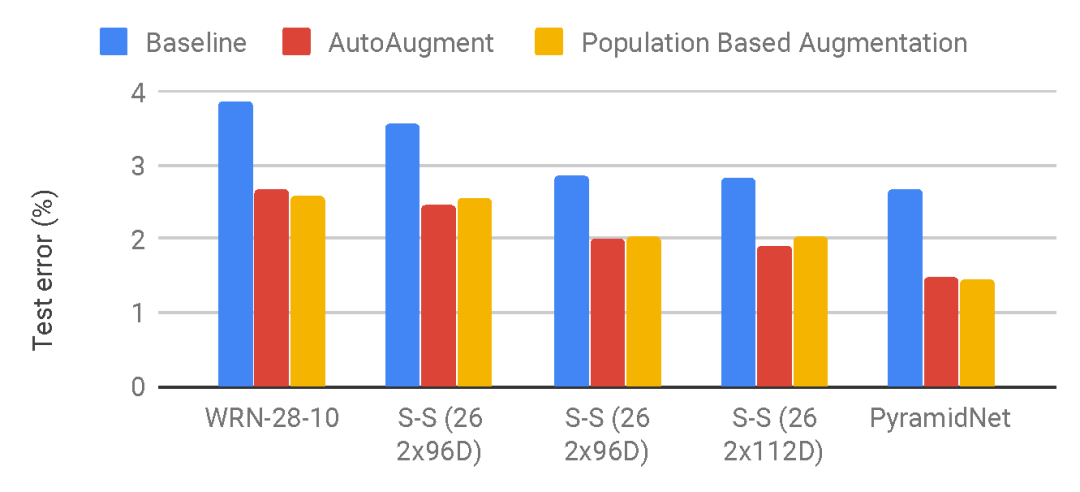
与AutoAugment相比,新方法给出的数据增强策略在不同模型上的表现。
研究人员从DeepMind的Population Based Training算法中借鉴了一些思想,并将其应用在了数据增强策略的生成上,将训练中当前的结果作为生成策略的基础,使得训练的结果可以在不同子模型中共享,避免耗时的重复训练。
这一改进使得通常的工作站也可以训练大型的数据增强策略算法。与AutoAugment不同,这一方法生成了一个策略调度方法而不是一个固定的策略。这意味着,在某个训练周期,PBA生成的数据增强策略是法f(x,t),其中x是输入图像,t 为当前的训练周期。而AutoAugment则会在不同的子模型上生成固定的策略fi(x)。
研究人员利用了16个小的WideResNet,每一个会学习出不同的超参数计划,而其中表现最好的调度将会被用于训练大型的模型,并从中得出最后的测试错误率。
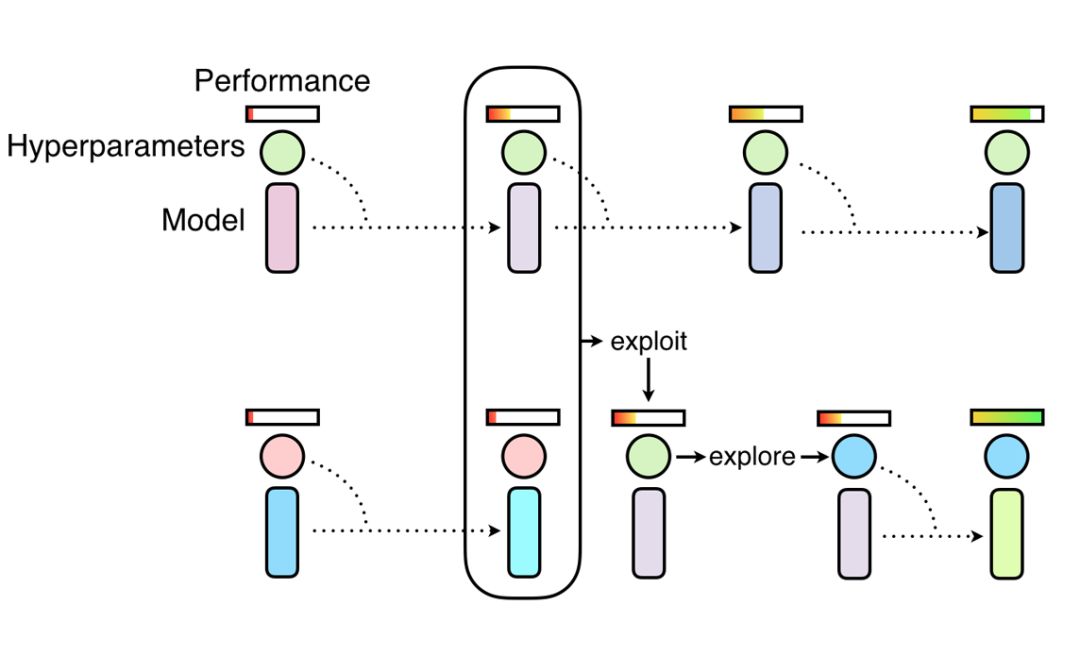
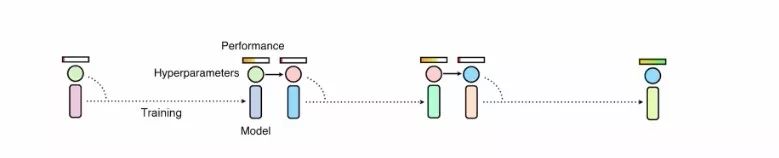
Population Based Training方法,首先将一系列小模型用于发现超参数,而后将表现最好的模型权重(exploit)与随机搜索结合起来(explore)。这些小模型首先在目标数据集上从零开始训练,随后通过将高性能的超参数复制到表现欠佳的模型上实现训练过程的复用,而后利用超参数的扰动来实现随机探索,以获取更好的表现。
通过这样的方法,研究人员得以共享不同模型间的计算,并共享不同训练阶段得到的不同的目标超参数。PBA算法通过这一手段避免了需要训练上千个模型才能获得高性能数据增强策略的冗长过程。下图显示了研究人员获取的数据增强策略:
研究人员还提供了源码和使用实例,如果想要给自己的数据集学习出合适的数据增强策略,可以在TUNE框架下进行,只需要简单的定义新的数据加载器即可使用。详情请参考代码:
https://github.com/arcelien/pba
-
研究人员找到了一种更好的方法来冷却 GaN 器件2022-08-17 949
-
马来西亚研究人员提出一种评估光伏模块不同冷却系统有效性的新方法2020-04-17 1234
-
研究人员推出了一种新的基于深度学习的策略2020-03-26 3383
-
研究人员使用声音技术来进行药物的传递2020-03-11 740
-
研究人员们提出了一系列新的点云处理模块2019-08-02 3861
-
一种新型获取太阳能以及如氢气类的清洁燃料的方法2019-06-07 2844
-
一种新方法来检测这些被操纵的换脸视频的“迹象”2018-07-03 6713
-
斯坦福提出基于目标的策略强化学习方法——SOORL2018-06-06 6168
-
Google研究人员开发增强现实显微镜检测癌细胞2018-04-23 2635
-
研究人员提出了一种柔性可拉伸扩展的多功能集成传感器阵列2018-01-24 8493
-
研究人员提出了“Skim-RNN”的概念,用很少的时间进行快速阅读2018-01-10 4755
-
安全研究人员用短信遥控开车门2011-07-29 1172
全部0条评论

快来发表一下你的评论吧 !
