

关于通过深度学习车辆检测的相关研究
描述
目标检测是指在图像和视频中对目标进行定位和分类。
在本节中,我将通过一个车辆检测示例,介绍如何使用深度学习创建目标检测器。相同步骤可用于创建任何目标检测器。
下图显示了一个三类车辆检测器的输出结果,检测器对每一种类型的车辆进行了定位和分类。
对不同类型车辆进行定位和分类的车辆检测器显示的输出结果。
在创建车辆检测器之前,我需要一组标注的训练数据,这是一组用感兴趣目标的位置和标签标注的图像。更具体地说,是需要有人对每幅图像或视频帧进行筛选,并对所有感兴趣目标的位置进行标注。这个过程称为“真值标注”。
真值标注通常是创建目标检测器过程中最耗时的部分。下图左侧显示的是原始训练图像,右侧显示的是经过真值标注的相同图像。
原始输入图象(左)和经过地面实况标注的输入图象(右)。
可以想见,标注一组数量足够大的训练图像数据集是一项极费人力的处理过程。为了减少数据标注时间,我使用了 Ground Truth Labeler 自动驾驶系统工具箱,它可使地面实况标注过程实现部分自动化。
用于标注视频和图像数据的 Ground Truth Labeler 屏幕截图。
实现标注过程部分自动化的一种方法是使用跟踪算法。我使用的 KanadeLucas Tomasi 算法(KLT)是在实际应用中使用的第一种计算机视觉算法。KLT 算法将目标表示为一组特征点,然后逐帧跟踪它们的移动位置。我们可以在第一帧中手动标注一个或多个目标,然后使用跟踪算法标注视频的其余部分。
Ground Truth Labeler 还允许用户导入自己的算法进行自动化标注。
我见过的最常用的方法是,用户导入自己现有的检测器,再进行新数据标注,这可以帮助他们创建出更精确的检测器。下图演示了使用 Ground Truth Labeler 标注一系列图像或视频的工作流程。
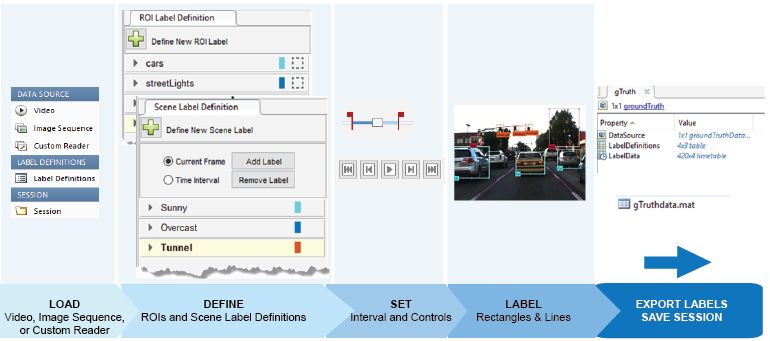
使用MATLAB进行自动真值标注的流程。
标注数据最终以 table 格式存储,table 中列出了训练集视频中车辆在每个时间点的位置。真值标注完成后,我可以开始训练车辆检测器。
本例中,我估计真值标注过程最高可加速 119 倍。我们以每秒 30 帧的速度捕捉训练视频数据,每 4 秒对目标进行一次标注。这意味着我们将节省中间 119 帧的标注时间。当然这是最好的情况,因为我们有时还得花时间更正自动标注的输出结果。
我们的车辆检测器使用的是 FasterR-CNN 网络。首先,定义一个网络架构,如下面的 MATLAB 代码片段所示。Faster R-CNN 算法主要分析图像的区域,因此输入层比输入图像的预期尺寸要小。本例中,我选择了一个 32x32 像素的窗口。输入尺寸需要根据执行时间和希望检测器解析的空间细节进行衡量。

中间层是网络的核心构造块,具有重复的卷积层、ReLU 层和池化层。
本例中,我只会使用几个层。若要提高准确性,或者如果想要将更多的类并入检测器中,可以重复这些使用层,创建一个更深的网络。

CNN 的最后一层通常是一组全连接层和一个 softmax loss 层。
在本例中,我在全连接层之间添加了一个 ReLU 非线性层,用以提高检测器的性能,因为我们这个检测器的训练集并没有我想要的那么大。

为训练目标检测器,我将 layers 网络结构输入 trainFasterRCNNObjectDetector 函数。如果您安装了 GPU,算法会默认使用 GPU。如果不想使用 GPU 或者想使用多个 GPU,您可以在 trainingOptions(训练选项)中调整 ExecutionEnvironment 参数。

完成训练之后,可以在测试图像上试一试,看看检测器是否正常工作。我使用下面的代码在单一图像上测试检测器。

Faster R-CNN车辆检测器检测到的边界框和得分。
若确信自己的检测器正常工作,我强烈建议您使用统计指标(例如,平均精度)在更大的一组验证图像集上进行测试。平均精度提供的单一分数可衡量检测器进行正确分类的能力(准确率)以及检测到所有相关对象的能力(召回率)。
-
穿孔机顶头检测仪 机器视觉深度学习2025-12-22 158
-
基于深度学习的小目标检测2024-07-04 3138
-
详解深度学习、神经网络与卷积神经网络的应用2024-01-11 4049
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2179
-
深度学习介绍2022-11-11 864
-
通过深度学习提高和发展车辆感知2022-11-10 954
-
汽车背后的故事 通过深度学习提高和发展车辆感知2022-11-01 526
-
基于深度学习的目标检测研究综述2022-01-06 2902
-
贝壳/皮革大理石深度学习检测案例2021-09-29 659
-
基于深度学习的异常检测的研究方法2021-07-12 1765
-
深度主动学习的相关工作全面概述2021-02-17 4519
-
通过深度学习提高ADAS系统的检测速度2020-06-04 3937
-
汽车背后的故事,通过深度学习提高和发展车辆感知2019-03-25 3791
-
Xilinx FPGA如何通过深度学习图像分类加速机器学习2018-11-28 4677
全部0条评论

快来发表一下你的评论吧 !
