

关于如何使用MATLAB 深度学习进行语义分割的方法详解
描述
这篇文章展示了一个具体的文档示例,演示如何使用深度学习和 Computer Vision System Toolbox 训练语义分割网络。
语义分割网络对图像中的每个像素进行分类,从而生成按类分割的图像。语义分割的应用包括用于自动驾驶的道路分割和医学诊断中的癌细胞分割。
如需了解更多文档示例和详细信息,建议查阅技术文档:https://cn.mathworks.com/help
为了说明训练过程,本示例将训练 SegNet,一种用于图像语义分割的卷积神经网络 (CNN)。用于语义分割的其他类型网络包括全卷积网络 (FCN) 和 U-Net。以下所示训练过程也可应用于这些网络。
本示例使用来自剑桥大学的 CamVid 数据集展开训练。此数据集是包含驾驶时所获得的街道级视图的图像集合。该数据集为 32 种语义类提供了像素级标签,包括车辆、行人和道路。
建立
本示例创建了 SegNet 网络,其权重从 VGG-16 网络初始化。要获取 VGG-16,请安装Neural Network Toolbox Model for VGG-16 Network:
安装完成后,运行以下代码以验证是否安装正确。
vgg16();
此外,请下载预训练版 SegNet。预训练模型可支持您运行整个示例,而无需等待训练完成。
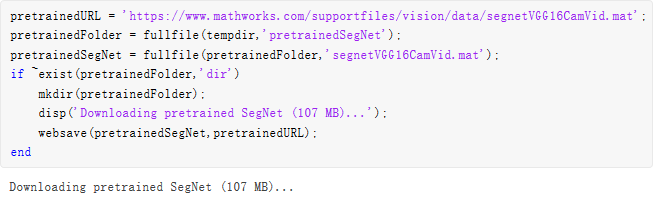
强烈建议采用计算能力为 3.0 或更高级别,支持 CUDA 的 NVIDIA GPU 来运行本示例。使用 GPU 需要 Parallel Computing Toolbox。
下载 CamVid 数据集
从以下 URL 中下载 CamVid 数据集。
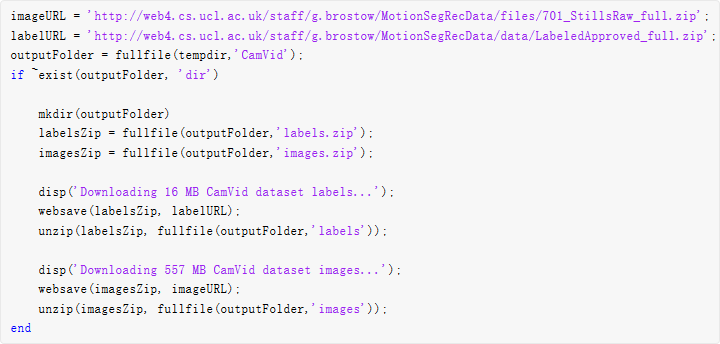
注意:数据下载时间取决于您的 Internet 连接情况。在下载完成之前,上面使用的命令会阻止访问 MATLAB。或者,您可以使用 Web 浏览器先将数据集下载到本地磁盘。要使用从 Web 中下载的文件,请将上述 outputFolder 变量更改为下载文件的位置。
加载 CamVid 图像
用于加载 CamVid 图像。借助 imageDatastore,可以高效地加载磁盘上的大量图像数据。
imgDir = fullfile(outputFolder,'images','701_StillsRaw_full');imds = imageDatastore(imgDir);
显示其中一个图像。
I = readimage(imds,1);I = histeq(I);imshow(I)
加载 CamVid 像素标签图像
使用 imageDatastore 加载 CamVid 像素标签图像。pixelLabelDatastore 将像素标签数据和标签 ID 封装到类名映射中。
按照 SegNet 原创论文(Badrinarayanan、Vijay、Alex Kendall 和 Roberto Cipolla:《SegNet:用于图像分割的一种深度卷积编码器-解码器架构》(SegNet: A Deep Convolutional Encoder-Decoder Architecture for ImageSegmentation)。arXiv 预印本:1511.00561,201)中采用的步骤进行操作,将 CamVid 中的 32 个原始类分组为 11 个类。指定这些类。
classes = [ "Sky" "Building" "Pole" "Road" "Pavement" "Tree" "SignSymbol" "Fence" "Car" "Pedestrian" "Bicyclist" ];
要将 32 个类减少为 11 个,请将原始数据集中的多个类组合在一起。例如,“Car” 是 “Car” 、 “SUVPickupTruck” 、 “Truck_Bus” 、 “Train” 和 “OtherMoving” 的组合。使用支持函数 camvidPixelLabelIDs 返回已分组的标签 ID,该函数会在本示例的末尾列出。
labelIDs = camvidPixelLabelIDs();
使用这些类和标签 ID 创建 pixelLabelDatastore。
labelDir = fullfile(outputFolder,'labels');pxds = pixelLabelDatastore(labelDir,classes,labelIDs);
读取并在一幅图像上叠加显示像素标签图像。
C = readimage(pxds,1);cmap = camvidColorMap;B = labeloverlay(I,C,'ColorMap',cmap);imshow(B)pixelLabelColorbar(cmap,classes);
没有颜色叠加的区域没有像素标签,在训练期间不会使用这些区域。
分析数据集统计信息
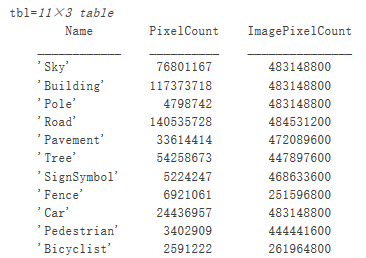
要查看 CamVid 数据集中类标签的分布情况,请使用 countEachLabel。此函数会按类标签计算像素数。
tbl = countEachLabel(pxds)
按类可视化像素计数。
frequency = tbl.PixelCount/sum(tbl.PixelCount);bar(1:numel(classes),frequency)xticks(1:numel(classes)) xticklabels(tbl.Name)xtickangle(45)ylabel('Frequency')
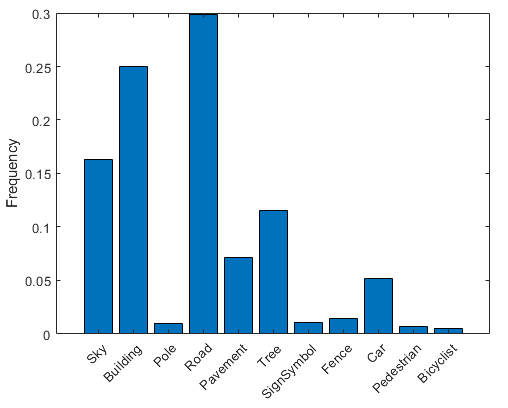
理想情况下,所有类都有相同数量的观察结果。但是,CamVid 中的这些类比例失衡,这是街道场景汽车数据集中的常见问题。由于天空、建筑物和道路覆盖了图像中的更多区域,因此相比行人和骑自行车者像素,这些场景拥有更多的天空、建筑物和道路像素。如果处理不当,这种失衡可能影响学习过程,因为学习过程偏向主导类。在本示例中,您稍后将使用类权重来处理此问题。
调整 CamVid 数据的大小
CamVid 数据集中的图像大小为 720 x 960。要减少训练时间和内存使用量,请将图像和像素标记图像的大小调整为 360 x 480。resizeCamVidImages 和 resizeCamVidPixelLabels 是本示例末尾所列出的支持函数。

准备训练集和测试集
使用数据集中 60% 的图像训练 SegNet。其余图像用于测试。以下代码会将图像和像素标记数据随机分成训练集和测试集。
[imdsTrain,imdsTest,pxdsTrain,pxdsTest] = partitionCamVidData(imds,pxds);
60/40 拆分会生产以下数量的训练图像和测试图像:
numTrainingImages = numel(imdsTrain.Files)
numTrainingImages = 421
numTestingImages = numel(imdsTest.Files)
numTestingImages = 280
创建网络
使用 segnetLayers 创建利用 VGG-16 权重初始化的 SegNet 网络。segnetLayers 会自动执行传输 VGG-16 中的权重所需的网络操作,并添加语义分割所需其他网络层。
imageSize = [360 480 3];numClasses = numel(classes);lgraph = segnetLayers(imageSize,numClasses,'vgg16');
根据数据集中图像的大小选择图像大小。根据 CamVid 中的类选择类的数量。
使用类权重平衡类
如前所示,CamVid 中的这些类比例失衡。要改进训练情况,可以使用类权重来平衡这些类。使用之前通过 countEachLayer 计算的像素标签计数,并计算中值频率类权重。
imageFreq = tbl.PixelCount ./ tbl.ImagePixelCount;classWeights = median(imageFreq) ./ imageFreq

使用 pixelClassificationLayer 指定类权重。
pxLayer = pixelClassificationLayer('Name','labels','ClassNames',tbl.Name,'ClassWeights',classWeights)

通过删除当前 pixelClassificationLayer 并添加新层,使用新的 pixelClassificationLayer 更新 SegNet 网络。当前 pixelClassificationLayer 名为“pixelLabels”。使用 removeLayers 删除该层,使用 addLayers 添加新层,然后使用 connectLayers 将新层连接到网络的其余部分。

选择训练选项
用于训练的优化算法是引入动量的随机梯度下降 (SGDM) 算法。使用 trainingOptions 指定用于 SGDM 的超参数。

大小为 4 的 minimatch 用于减少训练时的内存使用量。您可以根据系统中的 GPU 内存量增加或减少此值。
数据扩充
在训练期间使用数据扩充向网络提供更多示例,以便提高网络的准确性。此处,随机左/右反射以及 +/- 10 像素的随机 X/Y 平移用于数据扩充。用于指定这些数据扩充参数。

imageDataAugmenter 支持其他几种类型的数据扩充。选择它们需要经验分析,并且这是另一个层次的超参数调整。
开始训练
使用 pixelLabelImageDatastore 组合训练数据和数据扩充选择。pixelLabelImageDatastore 会读取批量训练数据,应用数据扩充,并将已扩充的数据发送至训练算法。

如果 doTraining 标志为 true,则会开始训练。否则,会加载预训练网络。注意:NVIDIA Titan X 上的训练大约需要 5 个小时,根据您的 GPU 硬件具体情况,可能会需要更长的时间。

在图像上测试网络
作为快速完整性检查,将在测试图像上运行已训练的网络。
I = read(imdsTest);C = semanticseg(I, net);
显示结果。

将 C 中的结果与 pxdsTest 中的预期真值进行比较。绿色和洋红色区域突出显示了分割结果与预期真值不同的区域。
expectedResult = read(pxdsTest);actual = uint8(C);expected = uint8(expectedResult);imshowpair(actual, expected)
从视觉上看,道路、天空、建筑物等类的语义分割结果重叠情况良好。然而,行人和车辆等较小的对象则不那么准确。可以使用交叉联合 (IoU) 指标(又称 Jaccard 系数)来测量每个类的重叠量。使用 jaccard 函数测量 IoU。
iou = jaccard(C, expectedResult);table(classes,iou)
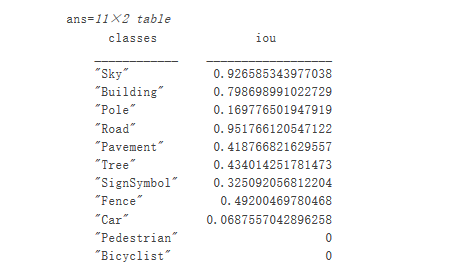
IoU 指标可确认视觉效果。道路、天空和建筑物类具有较高的 IoU 分数,而行人和车辆等类的分数较低。其他常见的分割指标包括 Dice 系数 和 Boundary-F1 轮廓匹配分数。
评估已训练的网络
要测量多个测试图像的准确性,请在整个测试集中运行 semanticseg。
pxdsResults = semanticseg(imdsTest,net,'MiniBatchSize',4,'WriteLocation',tempdir,'Verbose',false);
semanticseg 会将测试集的结果作为 pixelLabelDatastore 对象返回。imdsTest 中每个测试图像的实际像素标签数据会在“WriteLocation”参数指定的位置写入磁盘。使用 evaluateSemanticSegmentation 测量测试集结果的语义分割指标。
metrics = evaluateSemanticSegmentation(pxdsResults,pxdsTest,'Verbose',false);
evaluateSemanticSegmentation返回整个数据集、各个类以及每个测试图像的各种指标。要查看数据集级别指标,请检查 metrics.DataSetMetrics。
metrics.DataSetMetrics

数据集指标可提供网络性能的高级概述。要查看每个类对整体性能的影响,请使用 metrics.ClassMetrics 检查每个类的指标。
metrics.ClassMetrics
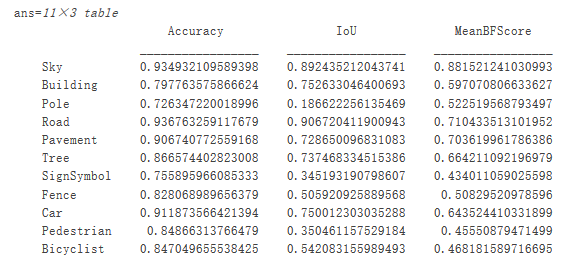
尽管数据集整体性能非常高,但类指标显示,诸如 Pedestrian、Bicyclist 和 Car 等代表性不足的类分割效果不如Road、Sky 和 Building 等类。附加数据多一些代表性不足类样本可能会提升分割效果。
-
图像语义分割的实用性是什么2024-07-17 1724
-
图像分割与语义分割中的CNN模型综述2024-07-09 3479
-
深度学习图像语义分割指标介绍2023-10-09 1053
-
基于深度学习的点云分割的方法介绍2023-07-20 793
-
自动驾驶深度多模态目标检测和语义分割:数据集、方法和挑战2023-06-06 820
-
图像语义分割的概念与原理以及常用的方法2023-04-20 7322
-
van-自然和医学图像的深度语义分割:网络结构2021-12-28 2555
-
基于深度神经网络的图像语义分割方法2021-04-02 1652
-
基于深度学习的三维点云语义分割研究分析2021-04-01 1505
-
分析总结基于深度神经网络的图像语义分割方法2021-03-19 1481
-
深度学习中图像分割的方法和应用2020-11-27 4529
-
语义分割算法系统介绍2020-11-05 8024
-
DeepLab进行语义分割的研究分析2019-10-24 1188
全部0条评论

快来发表一下你的评论吧 !
