

关于自动生成高效的代码的方法分析和分享
描述
代码生成作为一个普遍存在的成熟技术,已经被国内外很多知名企业采用,并将生成的代码直接部署在产品中。这些客户普遍反应,代码生成的确很大幅度地提高产品开发的效率,缩短产品开发周期。
虽然已有很多代码生成技术的成功案例,产生的代码效率仍是新用户普遍关心的问题(可能是最关心的问题)。
在 2018 MATLAB EXPO 用户大会上,三位资深的 MathWorks 技术专家受邀跟大家聊聊代码生成那些事,通过多个具体实例,详细解释用户在使用 MATLAB/Simulink 代码生成技术中遇到的问题和困惑。
产生出来的代码效率能行吗?
首先,好的模型能产生出好的代码。
根据很多用户反馈,在大部分情况下,生成的代码的运行速度和手写代码差不多,使用的资源要比手写明显的小。然而,如果直接采用默认的选项直接进行代码生成而不对模型进行任何准备工作,生成的代码效率将无法满足预期。
产生出来的代码的效率是和搭建的 Simulink 模型与 MATLAB 代码直接相关。这句话不难理解——好的模型能产生出好的代码。可是什么是好的模型呢?
以 HDL 代码生成为例:用户在 Simulink 里很快的搭建好算法模型,确认数值结果正确就开始产生 HDL 代码,却发现效率并不理想。这是因为在算法模型里没有任何架构的优化,也没有时序的信息(比如节拍寄存器)。其实只要在模型里正确的地方加入几个寄存器,产生出来的代码效率就会提高了。
其次,提高生成代码的效率还需要利用产品提供的优化功能,按照自己的需求设置优化参数。
默认参数设置是为了让大家能够最快、最容易的产生代码,而不是适用于所有场景下的最优设置,最优的设计一定是结合具体的问题的设置。
例如,有些硬件工程师使用默认设置产生出的 HDL 代码占用的资源很的要求很高,不能满足要求。问题关键在于没有使用 HDL Coder 中提供的优化功能,比如资源复用流处理等。这些功能可以帮用户找到模型中可复用的资源,根据用户的设置,自动优化使用的资源。
此外,生成代码的时候不仅要对使用资源进行优化,建议用户使用 HDL Coder 对主频进行优化并对代码定制。要对具体的要求采用不同的优化手段,才能产生出最优的代码。
第三,混合使用手写代码和自动产生的代码。
很多用户有一些误解,认为代码生成必须全部采用自动的方法,其实,代码生成手段并没有这些限制,反而会带来不必要的负担。
如果在算法中的某个模块已经有很成熟的代码,用户可以结合自动产生的代码和手写代码的好处,通过设置参数直接使用指定的已有代码,提高整体效率。
通过调整算法模型、正确使用优化功能,或适当混用手写和自动产生的代码来提高总体效率,用户将体会到基于模型的设计方法的好处。
拿正确的模型去生成代码
代码生成工具是没有纠错功能的,它只能忠实于你的模型去产生代码。如果模型不经过充分验证,或者说不能确保模型是正确的,那么代码也就没法保证正确。在基于模型的设计开发流程中,做到“拿正确的模型去生成代码”,你的流程就比别人强很多了。
但是,什么样的模型算是正确的模型?能跑出预期的结果的模型就一定是“正确的模型”吗?
正确的模型应该是在现有的工具水平下,经过充分验证的模型。由于在产品化中,所有验证工作最终都会被算到开发成本里面。所以要应该根据项目的要求,选择合适的验证手段。
从是否要运行模型来看,模型验证可以划分为“静态验证”和“动态验证”。
静态验证
在模型建立之后,首先需要做的是自动化的“静态检查”。建模规范检查(比如目前行业普遍采用的MAAB),是很多公司都在做的事情。除了规范检查之外,建议使用 Simulink Design Verifier 检查是否有数据溢出和死逻辑,这两种错误比违反一些建模规则更严重,可能会导致系统失效。
除了自动化的静态检查之外,“评审”是经常被大家忽略的静态验证方式。自动化静态验证和人工静态验证之间的顺序很重要,直接关系到开发效率问题。在评审之前完成自动化静态检查,可以帮助开发者发现问题,提高开发效率。
动态验证
动态,也就是让模型的功能跑起来。从效率上考虑,建议先做单元测试,再做集成测试。
单元测试应该是整个验证环节里工作量最大的环节,要重点关注结构覆盖率问题。具体多少的覆盖率算是合格,还有不少的争论。想要达到比较好的覆盖率,需要对模型的复杂度进行控制,复杂度一定不能太高,否则没法提升覆盖率。
集成测试可以一定程度的验证接口问题、调度问题、模块间的需求问题等,是非常有必要的。对于庞大系统,集成测试需要分阶段进行:先做组件级的集成,再做系统级的集成,让验证工作可实现。
完成以上提到的各种验证,基本上可以认为这是正确的模型了。使用验证过的正确模型配置数据,才可以生成的成熟的代码。当然,生成的代码还需要做一个对比测试,验证代码和模型之间功能上是否一致,也就是我们常说的 SIL 和 PIL 测试。
使用 MATLAB 算法自动生成代码
基于模型的设计流程和自动代码生成在汽车等行业基本上已经是标准手段,然而在大多使用 MATLAB 语言的通信和数据分析领域,代码生成的接受度还不是那么地高。用户大多选择留在 MATLAB 中,享受 MATLAB 语言的弹性。
如何在保持 MATLAB 的条件下,提升代码生成的效率呢?
用户普遍关注以下两点:
如何充分使用MATLAB算法开发的"设计模式"
如何重用已有的 C 或者 C++ 代码。
MATLAB 算法开发的“设计模式”借鉴于软件的设计模式这个概念,具体可以理解为一些 MATLAB 的编码规则。一个简单的“设计模式”用例:要想让 MATLAB 运行效率够高,应该尽量采用矩阵运算替代 for 循环。
在代码生成中也存在很多类似的模式。这些设计模式能够针对具体的硬件结构,产生出更加有效的代码,并且提升算法的抽象度。不仅可以提升代码运行效率,对于长期维护算法代码也很帮助。
以深度学习为例:
在 MATLAB R2017b 中发布的 GPU Coder 可以把通用的 MATLAB 代码转化为 CUDA C 代码。
在 GPU Coder 中,我们也总结了一些能够提升对 GPU 这种架构运行效率的模式。很多人不了解 GPU 架构,可以把它理解成多核处理器构成的集群。例如stencilKernel 这个高阶函数就总结了一种类似于二维滤波的计算模式。
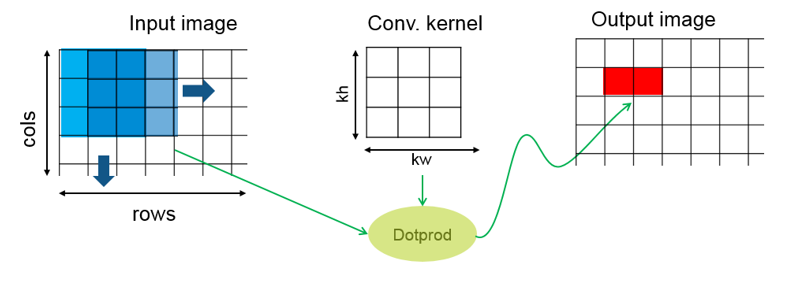
* 高阶函数就是那些输入参数为函数的函数。MATLAB 代码生成中汇集了很多类似的高阶函数,理论上用通用的 MATLAB 代码都能实现相应的功能。
充分使用这些算法模式(或设计模式),能够提高算法的抽象程度,同时有利于产生更加高效的代码。
那么如何混用现有的 C 或者 C++ 代码?
首先,非常不推荐用户为了提升效率而手写 C 代码生成 MEX 嵌入到 MATLAB 中。这不仅无法实现提速,反而可能比 MATLAB 更慢。另外手写 MEX 非常繁琐,并且容易出错。同时通过 MEX 接口引入的函数很难应用到生成的代码之中。
对于项目中遗留的 C 代码,高效的做法是在 MATLAB 中直接调用 C 代码,通过代码生成的方法自动产生可以被 MATLAB 调用的 MEX 函数。
double foo(double in1, double in2);
function y =callfoo %#codegen
y = coder.ceval('foo', 10, 20);
上面这段代码在生成 MEX 函数的时候,自动会做好调用包装的工作,而在 C 代码生成的时候,自动会直接调用已有代码,而不会有任何的额外调用封装,一举两得。
同理,在 Simulink 中,最简单便捷的方式是在 Stateflow 中直接调用手工 C 代码,让 Simulink 自行完成编译链接的工作,同时方便算法调整和更改。在 MATLAB 和 Simulink 中混合已有代码的方法很多,建议用户选择灵活性够高,同时还能兼顾开发效率和执行的方法实现。
-
探索设计稿自动生成Flutter代码的技术方案2024-11-08 2450
-
如何自动生成verilog代码2024-11-05 2457
-
基于 TouchGFX 生成的代码中添加触摸功能的方法2023-10-27 1861
-
什么是代码自动生成工具2021-11-03 1840
-
c语言代码自动生成工具,MCU代码自动生成工具介绍2021-10-28 1540
-
基于模型设计的HDL代码自动生成技术综述2021-06-08 4509
-
开源代码仓库的高效增量分析方法2021-05-12 1114
-
V模式的设计方法及自动代码生成资料下载2021-04-16 1158
-
关于为FPGA和ASIC生成Verilog和VHDL代码分析和应用介绍2019-09-18 7446
-
关于自动生成高效的代码的分析和介绍2019-09-11 1977
-
基于普适服务的代码自动生成研究_黄凯2017-03-16 760
-
编写高效Lua代码的方法2017-02-07 831
-
STM32库函数代码自动生成器正式版2016-07-13 1022
-
CRC校验代码自动生成工具2008-05-20 3907
全部0条评论

快来发表一下你的评论吧 !
