

思必驰的“人工智能技术”即“人工智能交互系统”
描述
回忆近年语音技术的发展历程,早年主要谈的是“合成”,再过些年开始着重谈“识别”,那时所谓语音技术的含义就是“识别+合成”。直到我们真正要把语音技术运用到智能硬件上的时候才发现,很多情景下光靠“识别+合成”已经彻底不够用了,我们开始需要的是“人性化的”拥有交互智能的语音技术。
讲到“人工智能”,所有的公司都在讲一个字“脑”, 那么同样都在说“脑”,思必驰的智能语音和别人做的有什么不同呢?
大家都知道IBM的超级计算机“深蓝”,它下棋可以赢国际象棋大师,但它只能算是一个计算机而不是一个机器人。因为对一个机器人来说,单独模块的优秀不是它的全部,它还要具备一个完整的从局部智能到整体智能的一整个人工智能系统,才算是一个机器人。这也就是为什么我们做的东西叫“对话系统”,不叫“语音识别”。
思必驰的“人工智能技术”,不只拥有以上依“脑”而生的技术模块,更重要的是,我们将这些模块协调整合和联合运用,使其成为一整个“系统”,即“人工智能交互系统”。
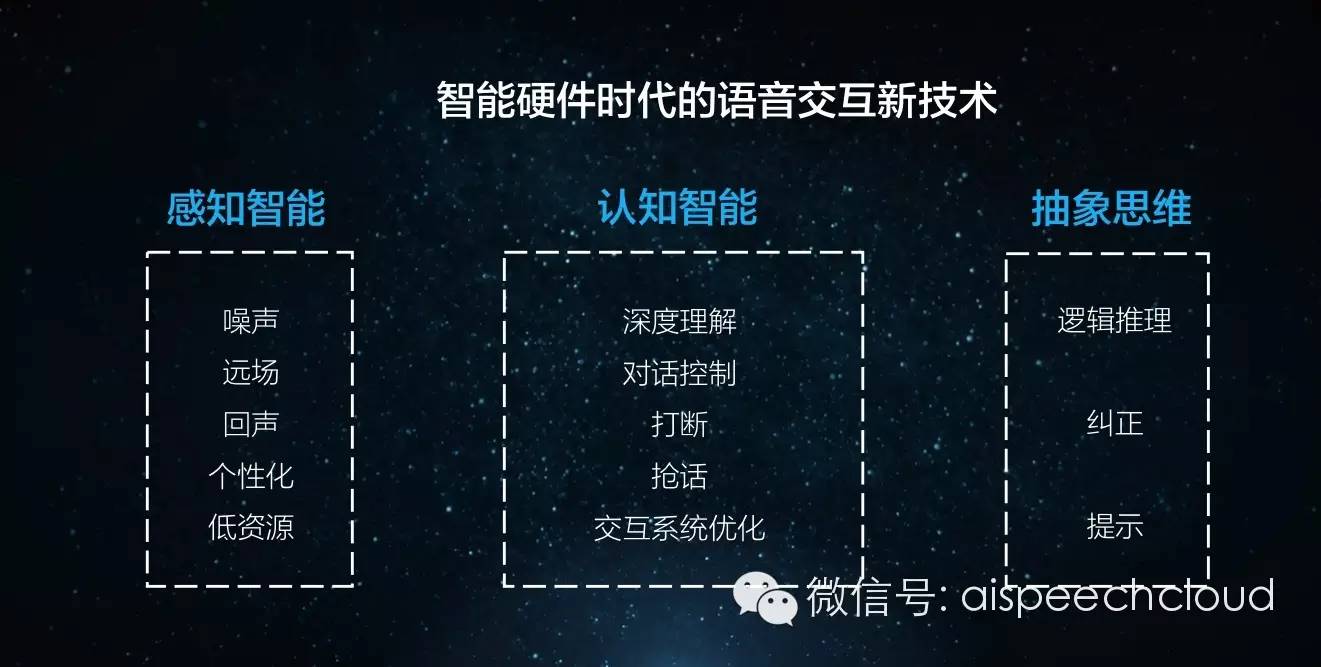
我们面临的技术挑战,大体上就这三类;首先要感知准确,就是识别率要高;其次准确理解用户的意图,给出正确的反馈;而后当反馈发生错误时,可以纠正。
先从“感知”即语音识别率入手。在移动互联时代,我们有两个非常重要的点,可以极大的优化我们的语音识别率。一块是“大数据”,另一块就是“深度学习”。
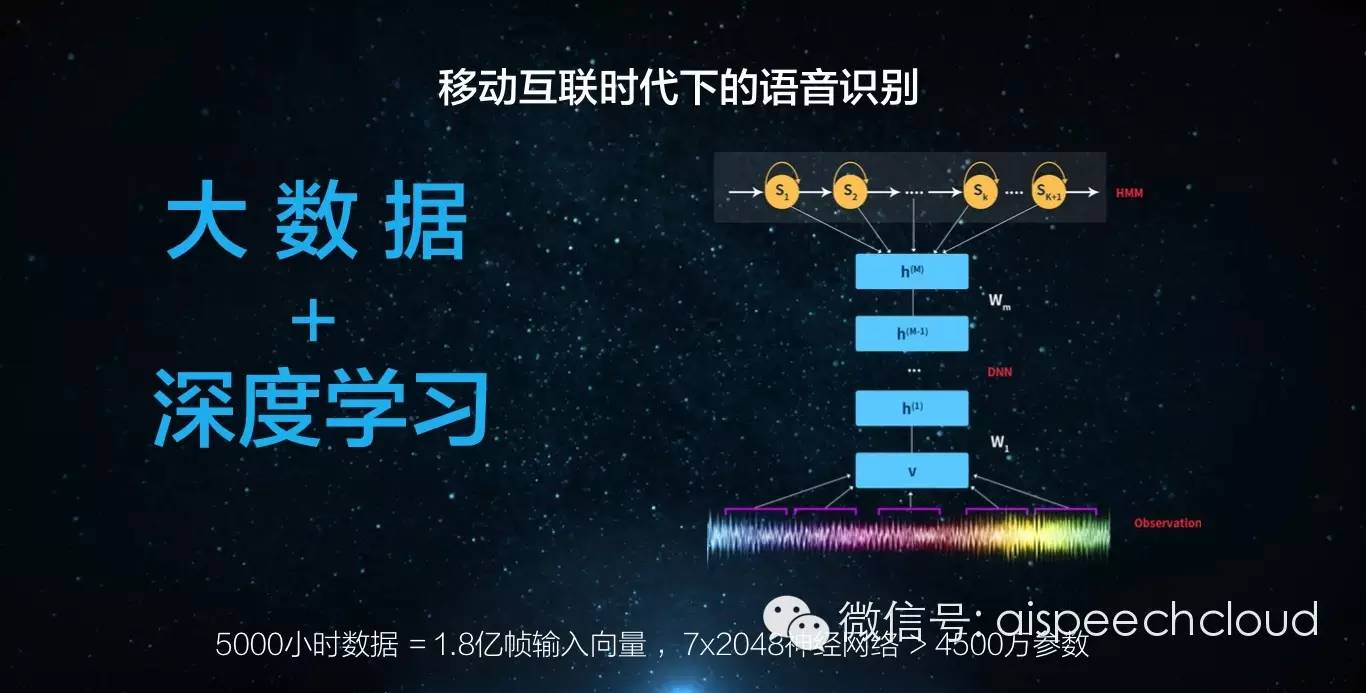
思必驰的人工智能语音系统经过自优化的“深度学习”和大数据计算之后已经被调教成国际上最好的语音识别技术之一,识别率已经到了95%以上。其语音技术仅靠在单麦,和后台算法支持情况下就可以做到国际一流的识别准确率。在抗噪技术领域,思必驰的最新结构化抗噪语音识别技术刷新了国际噪声标准测试库记录,取得目前世界最好成绩。模型算法的优化突破,使思必驰仅用软件就可以达到以往采用语音降噪芯片才能达到的效果,大幅提升了识别率,降低了成本。
在交互的大前提“感知”做好之后,个性化语音合成输出也是近年来的一个“渐痛点”。思必驰抛弃了传统语音采用的笨拙拼接合成技术,而采用最新的基于统计的参数化语音合成方法,不仅实现了模型规模的大幅压缩,缩小了语音文件的体积,语音连贯性的大幅提升,同时也允许更自由的个性化的语音训练。(目前思必驰已经完成一些名人的声音合成,基本能够保证与真人语音相差无几。)

“等周二许春来到苏州后约他一点钟在九寨沟喝茶”,究竟说的是许春来到苏州后请许春去喝茶,还是这个人来了许春约他去喝茶。这对机器来讲是一个不小的挑战。语义的解析不等于语义的理解。我们怎么解决这个事?一次性的交互是很难的,我们认为从键盘、鼠标到麦克风是不够的,必须要有脑子去思考去判断。很多情况下,由于识别一点点不准确,后面的整个任务变得没办法完成。语音识别在硬件里面想要用,必须和后端某些东西结合在一起,就是我们说的认知技能。

达成认知智能需要解决几个方面的问题,一个是静态认知,这一项我们已经通过深度学习和大数据的运算做的很好了。但是在现实场景下,即便拥有高识别度的静态认知也是不够的,还需要会动态认知,即交互过程中,智能硬件能通过用户不断反馈来学习,甚至主动询问,并最终完成任务。不仅如此,在动态认知的交互过程中,我们还要让系统可打断,在打断时还可以做回声消除,可以做部分理解,然后还可以在部分理解的基础上多轮交互,并对信息进行筛选理解。动态认知之后是进化认知,是让系统能够做到用得人越多,学得越好。
(发布会中演示的“语音纠正”功能,实录)
思必驰已完成了一个真正可使用的系统级对话技术框架,一个真正具有认知能力的人机交互界面,不只提升识别率,更实现了深度理解和智能反馈,以及支持任性语音输入的对话交互架构,做到了真正的智能交互。我们相信,智能硬件时代已经到来,而感知层面的适配技术与认知层面的对话技术,则是人机交互的未来。
思必驰的目标是希望能够专注于智能语音交互技术的研发,我们自己不做硬件,但是我们会支持,我们特别希望做的事情就是所谓的用户体验的深度优化和深度结合。我们希望通过用户体验深度优化,支持产业创新,最后希望和各位开发者一起共同成长。
-
人工智能是什么?2015-09-16 0
-
人工智能技术—AI2015-10-21 0
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 0
-
人工智能就业前景2018-03-29 0
-
解读人工智能的未来2018-11-14 0
-
人工智能技术及算法设计指南2019-02-12 0
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 0
-
2019年人工智能技术峰会落幕,大咖演讲PPT火热出炉!2019-07-02 0
-
路径规划用到的人工智能技术2021-07-20 0
-
目前人工智能教育研究最深入最经典的白皮书:德勤《全球人工智能发展白皮书2019》精选资料分享2021-07-27 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
物联网人工智能是什么?2021-09-09 0
-
嵌入式人工智能技术是什么?2021-12-27 0
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 0
-
《移动终端人工智能技术与应用开发》+快速入门AI的捷径+书中案例实操2023-02-19 0
全部0条评论

快来发表一下你的评论吧 !
