

分布式SFU/MCU媒体服务器的架构设计原则及问题解决思路
描述
本文来自英特尔实时通信解决方案架构师 段先德在LiveVideoStackCon2019上海大会的分享,详细介绍了英特尔在进行分布式SFU/MCU媒体服务器的架构设计中秉持的一些设计原则以及关键问题的解决思路。
大家好,我是来自英特尔上海研发中心的段先德。从2014年开始主要做基于WebRTC的实时通信和统一通信解决方案。对于实时通讯来说WebRTC技术是一个革命性的存在。2014年4月英特尔发布了Intel® Collaboration Suite for WebRTC,这是一款可免费使用的包含服务器侧程序和客户端SDK的完整解决方案。经过多年的迭代更新,当前最新发布的是4.2版本。
1. Requirements and Design Principles

本次分享的内容主要分为三个部分,首先介绍英特尔ICS for WebRTC项目中要解决的问题;其次介绍我们在解决这些问题的时候的指导思想和整体设计原则;最后介绍我们的解决方案目前的状态以及当下和近期要做的一些事情。
1.1 Functional Requirements

我们项目团队最初的出发点是希望能做一套够达到一般功能性要求的基于互联网的视频会议解决方案。譬如可以支持WebRTC和SIP终端,实现接入到同一个会议中。SIP主要针对的是存量设备,重点是对WebRTC终端的支持。WebRTC接入相比于很多以前存量的企业视频会议解决方案有很多的突破,从2011年以后Chrome在端多媒体系统,弱网对抗方面以及音视频处理这方面一直在持续的改进。
英特尔很早就注意到在WebRTC时代,亟需一个统一的终端和服务器侧的解决方案。我们需要把企业内外的一些移动终端、桌面应用、浏览器、传统的SIP终端设备都支持起来,需要支持NAT穿越和屏幕共享,需要支持服务器侧音视频录制,等等。这里面很多功能性需求通过传统SIP的解决方案做起来很不方便或者成本很高,但是在WebRTC时代,在基于互联网应用的技术思路下,可以很便捷、很优雅地解决这些问题,于是我们在2014年做了ICS for WebRTC v1.0。之后在2016年和2017年之间直播类的应用大爆发使得有些客户希望我们的解决方案里面能够支持直播类场景,把实时互动场景下的音视频流通过RTMP/RTSP/HLS/Dash推送到现有的CDN网络里面去。基于这类需求,我们在功能性方面增加了互动Streaming的能力。
2018年到现在,直播的用户体验要求越来越高,客户希望主播和粉丝或者观众之间的互动能够非常平滑的切换,同时端到端的时延也能够做得更好,也就是希望做到保证端到端的实时性的前提下,在单个呼叫里支持海量的用户连接。这就要求服务器侧系统既要有非常大的“扇出”能力,要支持终端连接在“发布者”和“订阅者”之间非常平滑地进行切换。我们目前正在做的就是把目前的解决方案扩展到这种能够支持大规模并发的“实时互动广播”,初步目标是单个呼叫里达到百万以上的并发连接,而且端到端的时延能够全球控制在300毫秒以内。关于端到端时延,我们在国内互联网上做过一些小规模的测试,测试结果的时延是150毫秒以内。我们还希望这个解决方案能够很方便封装成类似于CDN的服务访问接口或者形式,以便集成到客户现有的直播解决方案中去。
我们当前的解决方案已经具备了非常灵活的服务器侧媒体处理,服务器端可以做音视频的混音混流,比如说当前的一个呼叫里面有十几个参与方,有的参与方希望订阅呼叫中其他参与方发布的原始流,有的参与方希望订阅所有或部分参与方的mix流,有的参与方希望订阅符合自己对codec、分辨率、帧率、码率等定制化要求的转发流,我们当前的解决方案已经可以很好地支持这些需求。
1.2 Nonfunctional Requirements

如果仅仅是为了达到前面所讲的各种功能性需求,随便选择一个现有的开源框架去改改,再自己从头写一些功能模块拼凑一下,总可以整出一个PoC的版本或可以初步走向产品的东西。如果是要严肃地做一个打算把它放到生产环境去运营的产品级别的东西,真正考验这个解决方案的生命力的其实是它在非功能性需求方面的取舍和功力。即使是选择现有的开源框架去做产品,这个框架对非功能性方面的考量也是最重要的决定因素。
在非功能性方面主要关注的点有三个方面。
一是系统的可扩展性,它的服务部署规模可大可小,可以小到在一台英特尔®️ 酷睿™️i7的PC上部署使用,大到一个集群几百台甚至上千台机器组成一个大的cluster上部署使用。另外呼叫的参与方式可以是两三个人的讨论会,或者十几个人一般视频会议,又或者是几十人的在线课堂。部署时可以在当前的系统容量不足时在不中断业务的前提下增加或者删减当前部署的规模,达到很灵活的Scale in/Scale out。
二是容错性,容错能力大多描述都比较抽象,但是落实到系统在做设计的时候要考虑的东西就是非常具体的设计决策,在系统设计里面我们会强调甚至固执的坚持每一个部件都可能会出错,运行时都会发生crash,这就需要在流程设计或者一般逻辑里面handle这些问题,在系统发生部分失效的时候,要能够做到自动恢复或服务优雅降级。
三是分布式部署,单台机器上单实例的部署是不可能做容错的,只有分布式的部署才能够做到。我们要求允许把任何部件部署在数据中心的多台机器上面。我们现在进一步的要求是要能够把任何部件部署在多个数据中心,进行跨数据中心的分布式部署。
2.Unified Media Spread Model UMSM)
2.1 Modularization at Runtime
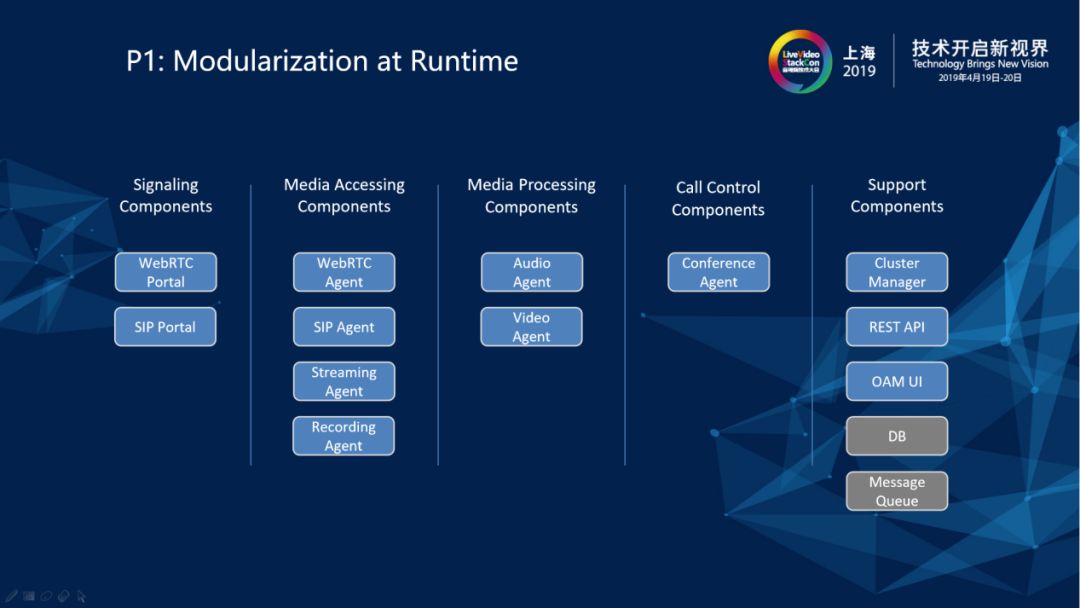
要满足上述的各种功能性和非功能性需求,就需要在概念模型上对系统的各个部件进行足够的抽象,将逻辑上独立的部件封装到运行时独立的模块里面——即模块化。不管是从单一职责的角度来说,还是从系统的可组合性来说,模块化是自始至终不能打破的一个原则,是我们当前系统——也是很多复杂系统进行架构的第一原则。在我们的系统设计中,对于跟客户端交互的部件来说,要把信令和媒体分开。对于媒体部分来说,媒体的接入部分和处理部分一定是分开的,直接和用户打交道的部分和后台内部的一些处理部件,不管是从单一职责角度来讲还是从面向接口的健壮性要求来讲都必须把它们分开。
我们的服务器侧系统在运行时可以分成五大块。
第一块就是跟客户端进行信令交互的部件,即图中的WebRTC Portal和SIP Portal。他们跟WebRTC客户端和SIP终端进行信令交互。值得注意的一点是WebRTC标准对信令交互的格式和通道没有规定,我们采用的是一种承载在socket.io通道中的私有协议。
第二块是跟客户端进行音视频媒体交互的部件,即图中的WebRTC Agent、Streaming Agent、SIP Agent和Recording Agent。其中WebRTC Agent负责跟客户端之间建立PeerConnection连接,SIP Agent跟SIP终端RTP流进行传输,Streaming Agent是针对RTSP/RTMP/HLS/Dash流,我们可以把IPCamera的RTSP流作为输入直接拉到系统里面来,也可以把系统里面任何一个输入流/合成流/转码后的流作为输出推送到RTMP Server上去,Recording虽然是完全发生在服务器侧的行为,但实际上在概念层次上面是更接近于流的输出。所以在概念模型里我们也把Recording Agent当做媒体接出部件,以达到概念模型的一致性。
第三块是媒体处理的部件,即图中的Audio Agent和Video Agent。Audio Agent是进行音频混音转码工作的部件,Video Agent是视频的合屏和转码的部件,这些所有的部件都是单独部署独立进程在运行。
第四块是呼叫控制的部件,即图中的Conference Agent。我们的系统还是将多方实时音视频通信作为场景基础,Conference Agent就是一通呼叫的总控制部件,它负责room中的参与者、流、订阅关系的控制和管理。对于像远程教育、远程医疗、远程协助之类的其他场景,我们主要是通过对Conference Agent来进行拓展和增强去支持。
第五块就是一些支持部件。整个服务器系统在运行和单机运行时都是cluster形式,Cluster Manager就是一个简单的cluster管理器。视频会议场景中会有一些room的预配置和管理,room的配置数据存放在MongoDB中,管理员都是通过OAM UI通过RESTful API访问Management API部件实现数据访问并受理REST请求。另外各个部件之间的rpc是架设在RabbitMQ消息队列上的。
2.2 Strong Isolation
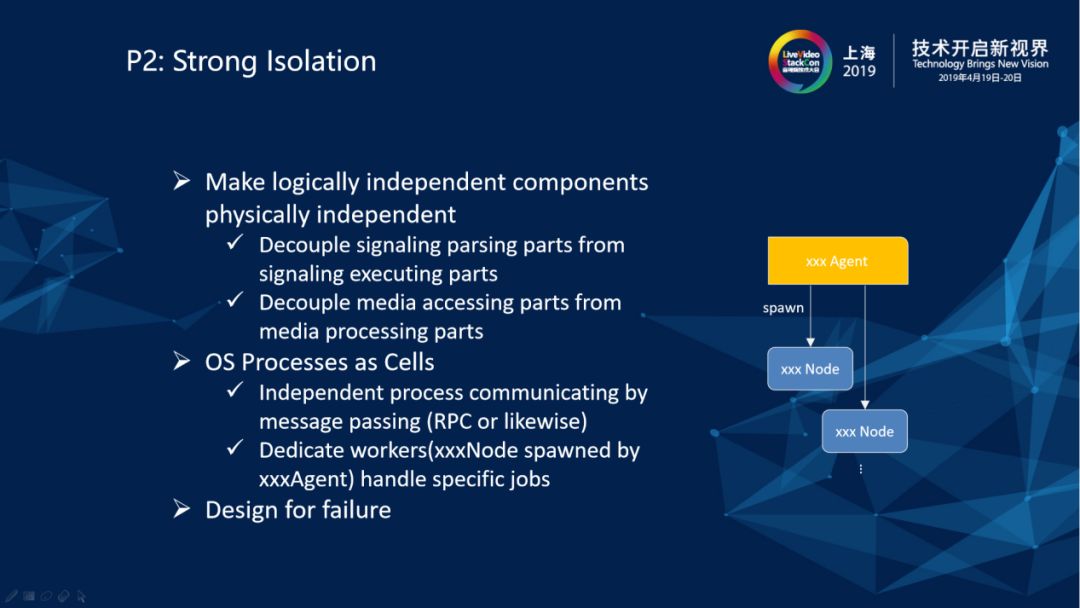
第二个原则就是要做强隔离。在系统里面坚持执行的原则就是要做强隔离,运行时一定是把看到的逻辑上面独立部件,把它在物理上也做成完全独立的运行时进程。比如像信令受理部件和信令执行部件就是分别独立的进程。这样做使得信令受理部件可以独立于呼叫控制里面的业务逻辑而存在。同理媒体接入部件和媒体处理部件也是分别独立进程。这里的进程就是OS语义上面进程,是我们服务器侧系统构建的基本元素,是生命体的细胞,不同的部件之间进行通讯唯一的方式就是message passing(消息传递)。在概念模型里面看的得到部件都是用单独的Worker进程来处理一个独立的Job。比方说一个Video Agent生成出来的Video Node,它的职责要么是做一个视频混流器,要么是做一个视频转码器,单独运行,独立工作。这样做一方面是进行错误隔离一个部件中产生的异常不会传染影响其他部件,一方面是各个运行时部件可以进行运行时单独进行升级替换。
2.3 Hierarchy in Media Accessing/Processing
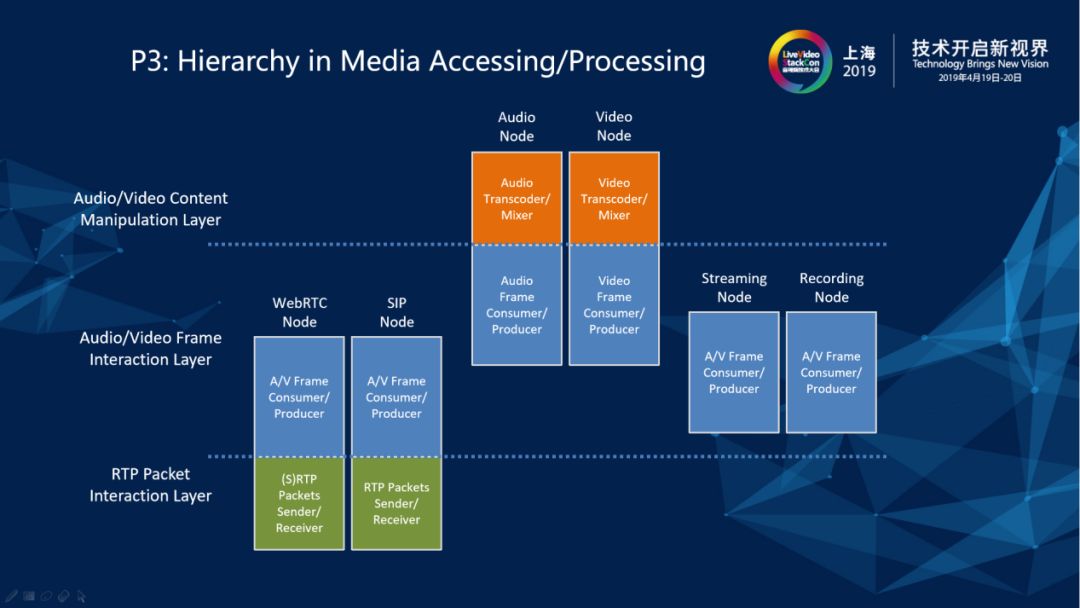
第三个原则就是层次化。具体体现在在媒体接入和媒体处理的一些部件的设计和实现上,这些部件在南北(纵)向上面有明确的层次划分,自下而上分为包交互层、帧交互层和内容操作层。以媒体接入部件为例,我们服务器侧系统需要跟各种外围系统和终端进行媒体交互,有的媒体是通过RTP/SRTP包的形式输入、输出,有的媒体是直接以AVStream的行书输出、输出。当媒体进入到我们服务器侧系统内部以后,我们希望有一个统一的格式让它在所有的媒体相关部件之间自由流转,所以我们就定义了统一的MediaFrame格式,所有输入的媒体在媒体接入部件上被组装成MediaFrame。处理MediaFrame的逻辑我们把它放在帧交互层,与客户端进行RTP/SRTP交互的逻辑我们放在包交互层。另外,MediaFrame进入媒体处理部件后,如果涉及到raw格式的操作——譬如合屏、色彩调整、添加水印、替换背景等——我们就把相关逻辑放在内容操作层。
2.4 Media Pipeline in WebRTC Node
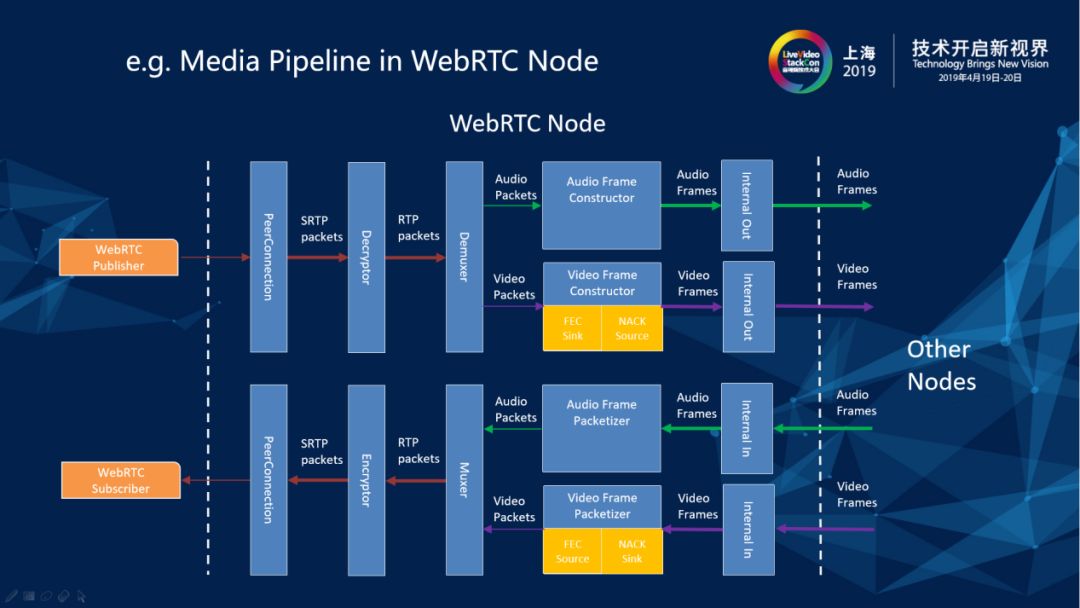
设计原则讲起来太枯燥,举两个例子。
第一个是WebRTC Node中的Pipeline结构。在WebRTCNode上面有一个明确的一个界限,广为人知的一些开源的框架里面有一些SFU框架是直接做RTP包的高级转发,而在我们的解决方案里于所有的外部媒体进入到系统里面会先将它们整理成统一的媒体(帧集的封装)之后在各个结点之间进行传输。除了使得层次分明便于系统横向扩展以外,另外一大好处就是把RTP传输相关的事务都终结在媒体接入部件(节点)上,RTP传输中的丢包、乱序等问题的处理不会扩散到系统其它部件。
2.5 Media Pipeline in Video Node (Video Mixer)
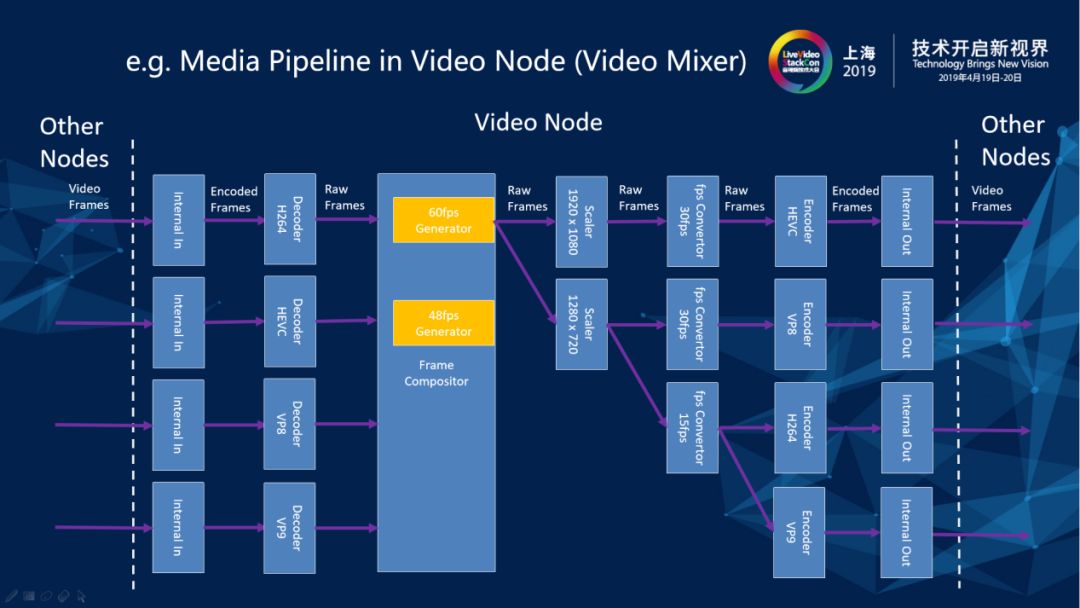
第二个例子是视频混流器内部的Pipeline结构。视频混流的部件在Pipeline上面进出都是视频帧,图上紫颜色的模块进出的都是视频已编码的帧,在视频处理部件的内部可以是一些已编码的帧,也可以是一些Scaler和Convertor。使得各个层次的处理器接口非常清楚,便于做成plugable。
2.6 Unified Media Spread Model (UMSM)
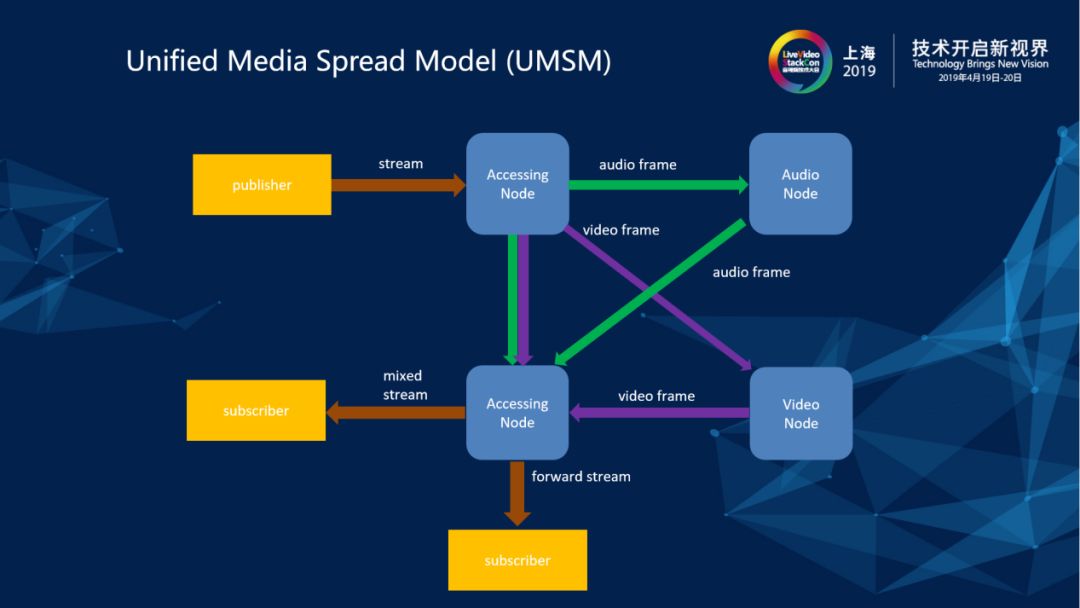
前面我们根据系统的功能性和非功能性需求,把系统拆成了一个个松散的部件。那么,怎么把这些部件捏合到一起成为一个有机的系统呢?特别是针对各个媒体接入部件和媒体处理部件之间的媒体交互,我们需要定义一个统一的内部媒体交互模型——我们称之为UMSM。
音视频媒体在系统内部流动,我们采用的是一个“发布-订阅”结构的流基本拓扑。如图所示,系统有一个发布者发布一个流进入到系统里,此时有两个订阅者,其中一个订阅者希望订阅发布的原始流的直接转发流,另外一个订阅者希望订阅房间里面所有的原始流合成流合屏以后的mix流,流的发布者和订阅者的PeerConnection连接建立在不同的WebRTC Node上面,通过PeerConnection进入WebRTC Node的SRTP包流,经过解密,被整理封装成MediaFrame(Audioframe/Videoframe),之后再在不同的部件之间进行传递,如果有订阅者需要的是直接转发流,就把它封装好的音频和视频的帧直接扩散到订阅者所连接的WebRTC Node上面来,如果有订阅者需要合成的流(合屏和混音的流),那么就把混流和混音以后的MediaFrame从AudioNode(Audio Mixer)和VideoNode(Video Mixer)扩散到订阅者所连接的WebRTC Node上。
有了这样一个足够松散的系统内部流扩散结构,无论这些媒体接入部件和媒体处理部件是运行在同一台机器上还是运行在一个数据中心内的不同机器上——甚至运行在位于不同数据中心的不同机器上,都有统一的、一致的流拓扑结构。
2.7 Media Spread Protocol

要实现这样一个流扩散模型,重点要解决两个方面的问题,一个是媒体节点间的传输,另一个是媒体节点的控制。
媒体节点间的传输是面向连接的,因为扩散链路都可能持续比较长的时间,且一般服务器侧部件的部署环境的网络条件是可控的,有利于保障传输质量。另外每一个连接结点间的扩散链路的连接是双向的,因为有可能两个媒体流的接入结点之间存在双向的扩散,以及与媒体流相关的一些feedback信息需要被反向传递,我们希望它能够复用在同一个扩散链路上面。另外我们需要它是可靠的,在以前跟合作伙伴做技术交流的时候他们对于要求流扩散链路必须是可靠的这一点有疑惑。实际上这是一个实时性和可靠性的取舍问题,我们选择在这个环节保证可靠性,而把实时性推给底层去解决,因为如果要在流扩散链路的所有环节处理信号损失,将给上层逻辑带来巨大的复杂性。
2.8 MSP - Transport Control Primitives(WIP)

传输控制就是对于节点间扩散传输链路的控制,目前为了方便在采用的是TCP,在同一数据中心内进行流扩散问题不大,在应用到跨数据中心的部署场景中时,特别是tts和delay比较大的情况下,实际可用的throughput会受比较大的影响,目前仍有一些改进的工作还在进行当中,我们也在调研SCTP和QUIC。
2.9 MSP - Underlying Transport Protocols(TCP vs.QUIC under weak network)
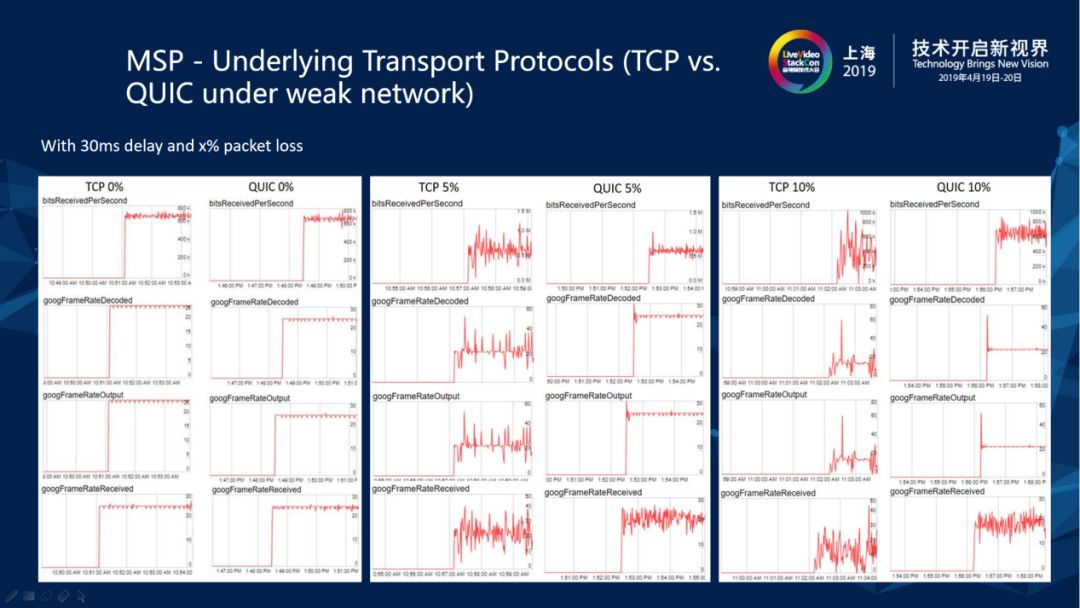
我们在节点间扩散时加一些网损的情况下用TCP和QUIC有做过一些对比测试。QUIC和TCP都是可靠传输,在有网损的时候都会产生一些重传或者是冗余,但是他们不同的拥塞控制策略会对端到端的媒体传递的质量产生不同的影响。我们的对比测试中,发送端是以恒定的码率和帧率(24fps)向服务器侧发送视频流,服务器侧在节点间分别采用TCP和QUIC进行节点间媒体流扩散,图中截取的是相同的网损条件下接收端收到的实际帧率,在5%的丢包和30ms delay时, TCP的帧率就会抖动的非常厉害,在接收端体验就会看到点不流畅,能明显地看到它的卡顿。当加上10%的丢包时波动就跟家剧烈,有时甚至降低到0fps,接收端的用户体验就是非常明的卡顿。相比而言,在QUIC上面还能够看到,接收端的帧率能够更好地坚持在24fps上下,接收端的流畅度更好。总体来看,QUIC是在弱网环境下进行节点间流扩散的一个不错的备选传输。
2.10 MSP - Media Control Primitives

媒体控制的操作对于媒体节点来说,一个publish就是往媒体结点上面发布一路流,给它增加一个input,一个subscribe就是在它上面去增添一个output,linkup就是把一个input和output接续起来,cutoff就把一个input和一个output拆开。对于媒体处理的结点有一些内生的流,generate就是让它产生一路流指定规格(codec、分辨率、帧率、码率、关键帧间隔等),degenerate就是让它取消正在生成中的一个流。
3.Cross DC Media Spread
3.1 Cross DC Media Spread:Relay Node (WIP)
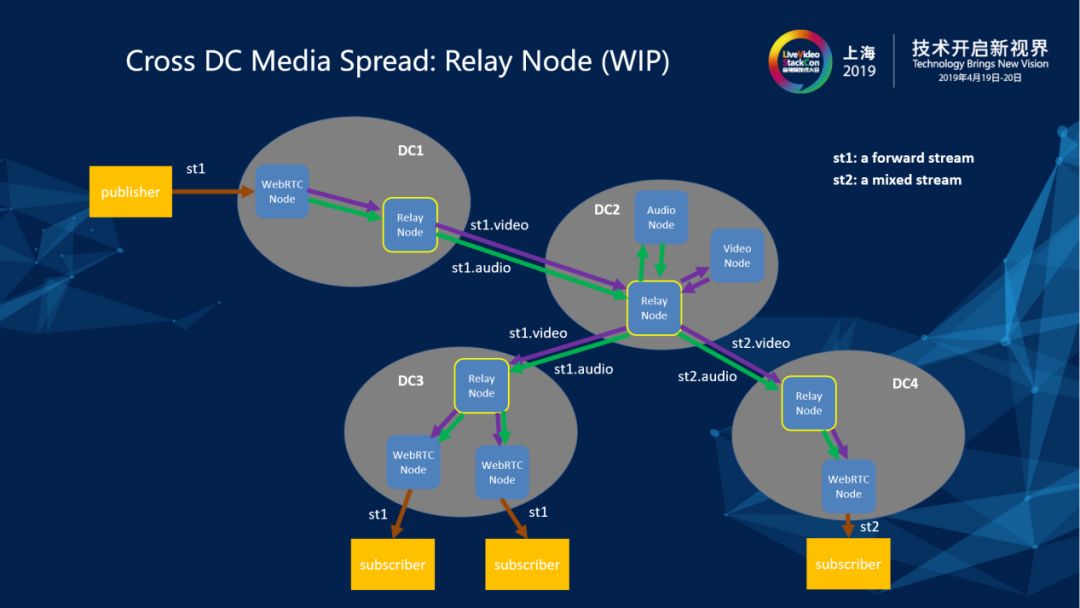
做TCP和QUIC的对比调研目的就是解决跨数据中心通过Internet进行节点间媒体流扩散的实时性(本质是throughput)问题。由于在跨数据中心媒体扩散的时候需要在Internet上面做流扩散,Internet在传输质量上讲没有在数据中心里的效果那么满意,需要找一些基于UDP改进的可靠传输协议去尝试,我们调研过SCTP和QUIC,总体来看QUIC的表现是相当不错的。
同时为了减少同一条流在两个数据中心的多个节点间传输,我们增加了一个Relay Agent(Node)的部件,使得同一条流在两个数据中心之间只需要扩散一次。Relay Agent的另一个作用是进行流扩散的时候的路由控制,譬如一个集团公司的很多分支机房并不是BGP的,需要将流汇聚到指定的BGP机房才能更好地向其他地区数据中心扩散。
3.2 Access Node(Agent) Scheduling

在部署了多个接入节点以后,除了通过增加接入节点来扩充系统的scalability,我们还希望能够利用接入节点的不同地理位置给靠近它的终端用户做就近接入。以WebRTC Agent为例,在部署WebRTC Agent的时候可以指定它的capacity(能力),capacity上面有两个标签,一个是isp,一个是region。用户在进行通信连接请求的时候,它带上isp和region的preference(喜好),系统在进行WebRTC Agent调度的时候会对所有可用的WebRTC Agent的capacity与用户指定的preference进行匹配,找到最满意的接入结点,最后达到就近接入的目的。
在符合preference的候选不止一个时,系统还提供基于work load和历史使用记录进行last-used、least-used、round-robin、random等调度策略,选取符合指定策略的接入节点。
3.3 CDN alike Service

解决了跨数据中心部署的媒体流扩散和调度问题后,我们的解决方案就可以提供更广阔的实时多方音视频通信服务。特别是有了Relay Agent的级联能力后,我们服务器侧系统就可以得到极大的提升,譬如假设单个媒体接入节点的扇出能力是1:1000的话,经过一级级联后就能达到1:100万,经过两级级联后就能达到1:10亿,已经堪比一般CDN的扇出能力了。而CDN的就是本质是一个分布式的cache系统,cache是实时应用的天敌。许多既要求海量扇出比,又要求实时性,并且要随时平滑进行流拓扑切换的场景下,CDN就显得无能为力了,而我们的解决方案将覆盖这些场景,特别是在5G和IoT的时代。
-
2022全新版!Java分布式架构设计与开发实战(完结)2026-03-30 597
-
怎么实现一种分布式视频服务器的设计?2021-06-08 1625
-
什么是流媒体服务器?2021-06-30 6485
-
分布式SFU/MCU媒体服务器该怎样去构建呢2021-11-01 1877
-
【学习打卡】OpenHarmony的分布式任务调度2022-07-18 4358
-
EAST分布式服务器集群系统的设计与实现_杨玉娇2017-03-19 940
-
微服务和分布式的区别2018-02-09 82195
-
什么是分布式系统 分布式架构有哪些2021-07-31 8502
-
【流媒体】Mesh|MCU|SFU三种流媒体服务器的比较2021-10-25 1153
-
如何构建分布式SFU/MCU媒体服务器?2021-10-26 649
-
指挥中心双引擎分布式坐席系统应用2021-11-19 1398
-
服务端高并发分布式架构最基础的概念2022-05-13 1609
-
怎么区分分布式服务器和集群式服务器?2023-11-29 1804
-
分布式节点服务器是什么?2024-01-12 1790
-
京准电钟:NTP网络授时服务器在分布式网络内的应用2024-11-27 1029
全部0条评论

快来发表一下你的评论吧 !
