

关于语音识别类产品细分及其应用场景分析
描述
你的童年是否也曾这样对着大门发出命令?
当然,大门用静止表示对你的“忽视”。乐此不疲的孩子还是会时不时对着门喊上几句,我们的潜意识是希望得到门有所回应,比如:门开了。
命令失效的原因是什么?因为大门本身不具备听到声音的能力,如果我们能让大门可以听到你说的话、发出的命令,进一步才可以启动语义和执行系统控制它的开关。
这就引申到本次重点介绍的技术——语音识别。本次干货分享由语音识别产品经理:@ 焦糖玛奇朵 进行提供。希望能为大家打开语音识别的大门。
语音识别是一项将人类的声音信号转化为文字的过程。本文将从产品的角度对业界的语音识别产品进行归类和说明。不同的产品类型具有不同的算法或者接口特性,对应不同的需求场景。
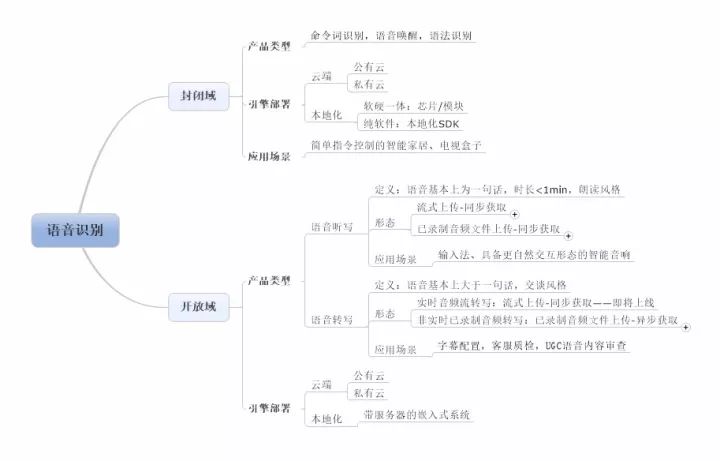
根据识别内容的范围,语音识别的大类分列如下
1、封闭域识别:
识别范围为预先指定的字/词集合,即算法只在开发者预先设定的封闭域识别词的集合内进行语音识别,对范围之外的语音会进行拒识。因此,可以将其声学模型和语言模型进行裁剪,使得识别引擎的运算量也较小。并且可将引擎封到嵌入式芯片或者本地化的SDK中,从而使识别过程完全脱离云端,摆脱对网络的依赖,并且不会影响识别率。业界厂商提供的引擎部署方式包括云端和本地化(如:芯片,模块和纯软件SDK)。
产品类型:命令字/词识别,语音唤醒,语法识别
产品形态:流式传输-同步获取
典型的应用场景:不涉及到多轮交互和多种语义说法的场景,如简单指令交互的智能家居和电视盒子,语音控制指令一般只有:“打开窗帘”,“打开中央台”等,但是一旦涉及到程序猿大大们在后台配置识别词集合之外的命令,如“给小编这篇文章来个打赏”,识别系统将拒识这段语音,不会返回相应的文字结果,更不会做相应的回复或者指令动作。
2、开放域识别:
无需预先指定识别词集合,算法将在整个语言大集合范围中进行识别。为适应此类场景,声学模型和语音模型一般都比较大,引擎运算量也较大。将其封装到嵌入式芯片或者本地化的SDK中,耗能较高并且影响识别效果。业界厂商基本上都以云端形式提供,云端包括公有云形式和私有云形式。本地化形式只有带服务器级别计算能力的嵌入式系统,如会议字幕系统。
产品类型按照说话风格的特点,分为:
(1)语音听写:语音时长较短(<1min),一般情况下均为一句话。训练语料为朗读风格,语速较为平均。一般为人机对话场景,录音质量较好。
按照音频录入和结果获取方式定义产品形态:
(a)流式上传-同步获取,应用/软件会对说话人的语音进行自动录制并将其连续上传至云端,说话人在说完话的同时能实时地看到返回的文字。语音云服务厂商的产品接口中会提供音频录制接口和格式编码算法,供客户端进行边录制边上传,并与云端建立长连接,同步监听并获取识别结果。
(b)已录制音频文件上传-同步获取,用户需自行预先录制好规定格式的音频,并使用语音云服务厂商提供的接口进行音频上传,客户端与云端的连接和结果获取方式与上述音频流类似。
典型应用场景:应用发展已经比较成熟:主要在输入场景,如输入法;与麦克风阵列和语义结合的人机交互场景,如具备更自然交互形态的智能音响,如“叮咚叮咚,转发小编这篇文章。”,在无配置的情况下,识别系统也能够识别这段语音,返回相应的文字结果。
(2)语音转写:语音时长一般较长(五小时内),句子较多。训练语料为交谈风格,即说话人说话无组织性比较强,因此语速较不平均,吞字&连字现象较多。录音大多为远场或带噪的。
除了模型不同之外,按照音频录入和结果获取方式定义产品形态:
(a)音频流转写:流式上传-同步获取,与上述语音听写类似,唯一不同的是,识别的时长不会有一句话的限制。
(b)非实时已录制音频转写:已录制音频文件上传-异步获取,用户需自行调用软件接口或者是硬件平台预先录制好规定格式的音频,并使用语音云服务厂商提供的接口进行音频上传,上传完成之后便可以断掉连接。用户通过轮询语音云服务器或者使用回调接口进行结果获取。
由于长语音的计算量较大,计算时间较长,因此采取异步获取的方式可以避免由于网络问题带来的结果丢失。也因为语音转写系统通常是非实时处理的,这种工程形态也给了识别算法更多的时间进行多遍解码。而长时的语料,也给了算法使用更长时的信息进行长短期记忆网络建模。在同样的输入音频下,此类型产品形态牺牲了一部分实时率,花费了更高的资源消耗,但是却可以得到最高的识别率。在时间允许的使用场景下,非实时已录制音频转写无疑是最推荐的产品形态!
典型应用场景:如字幕配置,客服语音质检,UGC语音内容审查
概念厘清
1、离线VS在线
在讯飞开放平台的产品定义和较多的客户认知中,离/在线的区别在于识别过程是否需要通过云端请求,即识别引擎是在云端还是本地。而云计算中的离/在线产品的引擎都处在云端,区别在于在计算过程中,客户端是否需要与云端进行实时数据交互,即上述所述的音频流和非实时已录制音频转写。两者的定义有冲突,因此并不建议使用离/在线概念进行相关产品定义。
2、8K VS 16Khz采样率语音模型
在众多语音云服务厂商中,会根据音频采样率进行分类,从而训练出更适合各类采样率的语音模型,最典型的为8K和16K模型。原始音频信息保留越多越有利于识别率的提升,因此,16K音频采用16K语音模型,其识别率会普遍高于8K音频采用8K模型。
3、语音识别VS语义识别
语音识别是语义识别的前提基础。语音识别将声音转化成文字,语义识别提取文字中的相关信息和相应意图,通过执行模块进行相应的问题回复或者反馈动作。
结语:
最后举一个栗子作为收尾:“叮咚叮咚,给小编这篇文章点个赞呗。”,在无后台配置的情况下,封闭域的语音识别系统会拒识这段语音,开放域的识别系统却能够识别这段语音,返回相应的文字结果。而现阶段的开放域语义系统在大概率情况下,还是会回复得比较生硬,并且也不会自动识别出相应的意图并做出指令。按照现有的比较通用的方法,这个功能需要使用封闭域的语义识别在后台预先配置相关答案,并且根据预先配置的信息抽取意图,再根据意图类别和槽位信息执行相应的动作——即调用微信的点赞接口(假设可以)进行相应的点赞操作。
听起来好绕呀,是不是觉得还是自己手动点个赞简单粗暴省事得多了呢?然而,一切现代人类做起来自然而然&毫不费力的动作,却都是建构在经过了亿万年的学习进化,兆亿次闭环重复练习的智人基因!而任何的人工智能技术也是需要一个巨量的数据训练和一定的演变周期。并且在所有的科技发展进程中,率先取得突破并且在应用领域产品成熟化往往都是在封闭域,亦如现在正处封闭域产品化的语义识别(如:AIUI,echo等),而语音识别的产品成熟化已经走过了封闭域到达了开放域,正在向各行各业输送人工智能的力量!
附图:语音识别产品类别图
-
NFC协议分析仪的技术原理和应用场景2024-09-25 4438
-
射频分析仪的技术原理和应用场景2024-11-26 4520
-
信号分析仪的原理和应用场景2025-01-17 914
-
混合信号分析仪的原理和应用场景2025-01-21 541
-
脉冲信号分析仪的原理和应用场景2025-01-23 1585
-
车联网语音识别技术发展与应用2013-07-26 3486
-
不接地气的机器人终将消失,垂直应用场景的切入才能促进消费升级2018-05-23 2554
-
小容量OLT应用场景分析2020-12-03 4271
-
离线语音Snowboy热词唤醒语音识别2021-07-30 3271
-
离线语音识别和控制的工作原理及应用2023-11-07 1385
-
方言离线语音控制场景解决方案2023-11-17 628
-
离线语音识别及控制是怎样的技术?2023-11-24 2215
-
语音识别的应用场景2019-03-27 23031
-
语音识别芯片的潜在应用场景分析2021-10-29 1843
-
广州唯创电子语音识别芯片选型指南:场景化设计与技术适配策略2025-03-27 1244
全部0条评论

快来发表一下你的评论吧 !
