

关于语音助手的“重大安全漏洞”的介绍和解决方法
描述
几篇名为“语音助手存在重大漏洞,黑客可以这样攻击你的手机”以及“海豚攻击,攻破你的语音助手”等类似文章广泛传播,文章中提到已攻陷了包括Siri、Alexa、Cortana、Google Assistant等知名语音助手,让大家对语音交互的安全性不免又增添疑虑。
今天,我们特意邀请了了科大讯飞资深科学家、研究院副院长王海坤来给大家解析一下什么是“海豚攻击”,它的产生原因和潜在威胁,以及如何化解这个所谓的“重大安全漏洞”。
1什么是“海豚攻击”
这个名词源于论文“DolphinAttack: Inaudible Voice Commands”,该文章已经被网络安全领域四大学术会议之一的ACM CCS(Conference on Computer and Communications Security)接收,目前已经可以在arxiv上下载到。
这里面的关键词“DolphinAttack”,即“海豚攻击”源于一种现象,即海豚能发出超声波来攻击目标鱼群进行觅食,而这种攻击也正是借助了超声波。
提到超声,这里先科普一下声音信号的频带分布、相应的名称和性质。
当物体振动时会发出声音。每秒钟振动的次数称为声音的频率,它的单位是Hz。我们人类耳朵能听到的声波频率为20Hz~20KHz。当声波的振动频率大于20KHz小于20Hz时,我们就听不见了。
我们把频率高于20kHz的声波称为“超声波”。超声波具有方向性好,穿透能力强,易于获得较集中的声能,在水中传播距离远等特点,通常用于医学诊断的超声波频率为1MHz~5MHz。
频率低于20Hz的声音称为次声。次声特点是来源广、传播远、穿透力强,不容易衰减,不易被水和空气吸收。某些频率的次声波由于和人体器官的振动频率相近,容易和人体器官产生共振,对人体有很强的伤害性,危险时可致人死亡。
这篇文章里提到的“海豚攻击”就是用到了超声的基本原理,其技术实现思路是:
步骤1:把正常的频率范围的语音信号(用于语音识别的语音一般是16KHz采样,由奈奎斯特率可知其信号的最高频率是8KHz,这里称为Baseband信号),利用幅度调制的方法把Baseband信号调制到超声范围,该超声信号称为载波(Carrier)。
这么做主要目的是把信号调制到被攻击的用户无法听到的超声波范围。下面就是幅度调制的原理图。
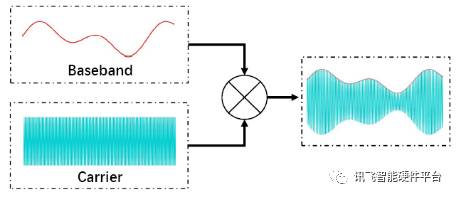
步骤2:利用超声发射器来发射调制后的超声信号,冲击被测设备。通过设备端自身的录音系统实现对Baseband信号的解调,从而实现对设备的控制。
搭建一套这样的超声冲击测试系统,需要以下几个设备:

信号源:用来产生Baseband测试信号,用普通手机就可以。
信号发生器:用来产生超声信号,并把Baseband信号调制相应的中心频率。
功率放大器:用来对超声载波信号进行功率放大。
超声扬声器:用来播放超声载波信号。
文章中还提到可以做成一个简化装置,成本在3美元以下:
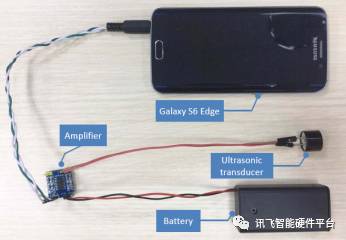
根据文章作者的介绍,该系统成功实现了对于Siri、Alexa、Cortana、Google Assistant的控制,甚至奥迪Q3的语音功能也能操控,进行了打开飞行模式,拨打特定号码等操作。
基于此,文中观点认为“基于该漏洞,黑客可以实现利用它上一些恶意网站,利用它打一些乱七八糟的电话。甚至,如果有些系统里的语音购物、支付功能够便捷,分分钟你的钱就没了”。
2“海豚攻击”为什么能实现
这里我们来分析一下我们常见支持语音控制的系统,包括手机、汽车、智能硬件有什么缺陷,导致让黑客可以有机可乘。
首先看一下我们的语音控制系统的录音(Voice Capture)有哪些环节:
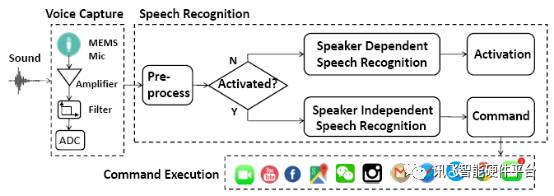
从上图种可以看到,录音系统包括了:
a) 麦克风:Microphone,用于把声压信号转换为模拟电信号。
b) 放大器:Amplifier,用于模拟信号的增益放大。
c) 低通滤波器:Low pass Filter,用于过滤高频无用的信号。
d) 模数转换器:ADC,用于把模拟信号采样为数字信号。
在录音系统的各个环节中,“海豚攻击”有几处风险可以利用:
a) 该文章作者的观点是,麦克风本身的非线性会对载波信号实现部分解调。
b) 实际上更为重要的原因在于目前主流的设备的录音系统一般采用的是一阶低通滤波器,过渡带太宽,从而导致高频信号不能有效的过滤;再加上市面上大部分的录音设备的ADC的抗混叠滤波效果有限,导致带外信号被混叠到Baseband里面,从而客观上实现了信号的解调。
3“海豚攻击”的局限性分析
上面谈到了“海豚攻击”实现的基本原理。但是经过我们的分析,这种“漏洞”虽然理论上存在风险,但是实现代价较大,且整体可行性较低,大家不必过于恐惧。下面我们再来分析一下它能实现的效果的局限性:
局限性1: 测试设备发射要求高,不易隐藏作案。
首先,该系统需要一个大功率且大尺寸的信号发生器来生成高质量的超声信号;同时,目前的普通麦克风对20KHz以上的信号频响衰减非常大,这就要求超声信号的发射功率有相当大的发射功率。
这篇文章中使用的超声发射器可以支持到300MHz的频率范围,超声播放的声压级达到了125dBL,这种情况下普通的简化装置的放大器和喇叭是实现不了的。
局限性2: 攻击距离很短,智能家居产品不受影响。
同样是由于目前普通麦克风对20KHz以上的信号频响衰减非常大,在声压级是125dBL的播放的超声信号下(这个音量已经需要非常专业播放设备了),实验的最远冲击距离只有1.75m,对于大部分设备超过0.5m就没有响应了,再加上超声信号没有穿墙能力,因此对于放在家中的智能硬件设备是没有任何影响的。对于携带到公共场所的手机和可穿戴设备则有一定的“风险”。
局限性3: 攻击语音质量很低,效果和单个硬件相关。
如前面我们的分析,由于解调后的信号毕竟是经过低通滤波器,导致各频带都是有不同程度衰减的,且大部分ADC都有抗混叠滤波,因此最终设备端解调进来的Baseband信号失真很严重,信噪比也不会很高。
攻击效果也跟硬件本身相关,比如麦克风型号、低通滤波器的实现方式和效果、ADC抗混叠效果和采样频率都是相关的。想要达到好的效果必须根据实际的硬件来调节载波频率,信号强度等参数,这对于公共场所游走作案,且不知道被攻击者使用的什么设备的情况下是比较难以实现的。
4声纹+语音唤醒,完美解决“海豚攻击”
通过上面的分析,我们知道“海豚攻击”只是在理论上存在风险,但是有没有办法来从根本上解决该问题,做到万无一失呢?这里就从硬件设计和软件实现上谈一下解决方案。
硬件解决方案:
a) 再增加一个低通滤波器,进一步减少高频成分的泄露。
b) 采用抗混叠更好的ADC,进行更严格的抗混叠测试。
c) 采用更高的采样频率,比如采样率是16K的话,16~24K的信号就能混叠进来。如果采样率是48Khz的话,要24Khz以上的信号才有可能混叠进来。实际上24Khz信号要发射和采集都要困难很多。
d) 采用动态的采样频率,让攻击者无法及时调整。
声纹+唤醒解决方案
从硬件解决方案上可以看出来需要对整体硬件进行重新的设计开发,难度相对较大,且周期长,对于存量用户无法保证绝对安全。我们这里引入一种思路——通过声纹+唤醒的思路来保证个人或家用设备不被陌生的语音攻击。
声纹识别是一种通过语音信号提取代表说话人身份的相关特征(如反映声门开合频率的基频特征、反映口腔大小形状及声道长度的频谱特征等),进而识别出说话人身份等方面的技术。它广泛应用于信息安全、电话银行、智能门禁以及娱乐等领域。
声纹识别所提供的安全性可与其他生物识别技术(指纹、掌形和虹膜)相媲美,且只需或麦克风即可,无需特殊的设备,数据采集极为方便,造价低廉,是最为经济、可靠、简便和安全的身份识别方式,并且是唯一可用于远程控制的非接触式生物识别技术。
科大讯飞在声纹识别方面一直处于技术领先的地位。 在2008年6月,讯飞参加NIST(美国标准技术研究院)举办的说话人识别声纹识别大赛(SRE)中,在3项关键指标中,获得两项第一,一项第三,综合评比第一的好成绩。
目前科大讯飞推出的声纹+唤醒的方案用户只需要对着自己的硬件设备说出3~4遍唤醒词即可完成声纹注册。使用的时候,用户也只需要对设备说出语音唤醒词即可,和目前的语音唤醒方式保持一致,不会带来用户的使用成本。
声纹识别正确率达到98%,目前基于讯飞的数字密码声纹引擎,已经成功用于中国移动飞云业务。
目前我们的远场声纹唤醒技术已经成熟,相关产品方案也在研发之中,将唤醒词作为声纹识别的文本,实现唤醒后对唤醒人身份的鉴别。
-
开发人员和嵌入式系统设计人员如何使用JWT关闭物联网设备的安全漏洞?2021-06-16 1697
-
软件安全漏洞的静态检测技术2009-04-20 910
-
Linux发现更多安全漏洞LHA 与imlib受到波及2009-06-12 712
-
关于开关电源的电磁干扰问题研究和解决方法2009-06-30 1582
-
Intel发布补丁 修复vPro安全漏洞2009-12-24 843
-
速升!苹果iOS10.3.1修复重大WiFi安全漏洞2017-04-06 3332
-
Windows、macOS、Linux正被一处重大安全漏洞威胁2018-05-13 1180
-
Intel处理器曝新安全漏洞 官方回应并非英特尔平台独有2018-11-04 792
-
商用Apple设备存在着重大的安全漏洞2019-09-27 1129
-
Windows10曝重大安全漏洞 微软官方已紧急推送补丁2020-01-15 2743
-
微软开发出一种新系统 区分安全漏洞和非安全漏洞准确率高达99%2020-04-17 4208
-
苹果再现安全漏洞,iOS 6以上版本存在危险2020-05-04 1924
-
苹果iOS14.5修复重大漏洞,避免信息被盗2021-02-23 2741
-
如何消除内存安全漏洞2023-12-12 2389
-
iOS 17.4.1修复两安全漏洞,涉及多款iPhone和iPad2024-03-26 1553
全部0条评论

快来发表一下你的评论吧 !
