

云知声详解AI计算用途和未来的发展趋势
描述
计算任务容器化
Docker 是目前业内主流的容器技术,在各个领域得到广泛的应用。容器的概念具有新颖的设计思想,非常方便开发、测试以及发布产品,并能保证在这几个环节中软件运行环境的一致性。Docker 和虚拟机是不一样的,两者差异很大,虚拟机需要大量的资源来模拟硬件,运行操作系统,而 Docker 几乎不会有计算性能的损失,轻量级是其显著特点,所以得到广泛的应用。
容器本质上是宿主机上的一个进程,一般来说,容器技术主要包括 cgroups (control groups) 和 namespace 这两个内核特性,namespace 实现资源隔离,cgroups 实现资源限制。除此之外,在容器镜像制作时,利用UnionFS 实现 Copy on Write 的 Volume 文件系统。
Namespace 的作用就是隔离,是 Linux 在内核级别的隔离技术,从内核 2.4.19 开始逐渐引入并完善。它可以让进程拥有自己独立的进程号,网络,文件系统(类似 chroot )等,不同 namespace 下的进程之间相互不可见。主要包括以下六类 namespace:
Mount namespace系统内核版本 >2.4.19
实现文件系统挂载
每个容器内有独立的文件系统层次结构
UTS namespace
系统内核版本 >2.6.19
每个容器有独立的 hostname 和 domain
name
IPC namespace
系统内核版本 >2.6.19
每个容器内有独立的 System V IPC 和
POSIX 消息队列系统
PID namespace
系统内核版本 >2.6.24
每个 PID namespace 中的进程有独立的 PID,容器中的每个进程有两个PID:容器中的 PID 和 host 上的 PID
Network namespace
系统内核版本 >2.6.29
每个容器用有独立的网络设备,IP 地址、
IP 路由表、端口号等
User namespace
系统内核版本 >3.8
容器中进程的用户和组 ID 和 host 上不
同,每个容器有不同的用户和组 、ID;
host 上的非 root 可以成为
user namespace 中的root
容器通过 namespace 实现资源的隔离,每个容器可以有上述六种独立的 namespace,有了资源隔离之后,如果不能对各个 namespace 下进程的资源使用做限制的话,那么 namespace 隔离也没有意义了,所以在容器中,我们利用 cgroups 实现对进程以及其子进程的资源限制。
Cgroups 顾名思义就是把进程放到一个组里统一加以控制。根据官方的定义:
cgroups 是 Linux 内核提供的一种机制,这种机制可以根据特定的行为,把一系列系统任务及其子任务整合(或分隔)到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。
通俗的来说,cgroups 可以限制、记录、隔离进程组所使用的物理资源(包括:CPU、memory、IO 等)。需要说明是,我们可以通过本地的文件系统来管理 cgroups 配置,就像修改 /sys 目录下的文件内容一样,来类似修改cgroups配置。而且,在 docker引擎这一层已经帮我们屏蔽了底层的细节,我们可以通过 docker 命令很方便的配置 cgroups 相关的参数。
针对CPU资源,cgroups 提供了三种限制CPU资源的方式:cpuset、cpuquota 和 cpushares。针对内存资源,提供包括物理内存和swap两块的限制。另外,blkio子系统的功能提供对块设备读写的速率限制。由于篇幅限制,关于cgroups 的介绍不详细展开。
除了上述 namespace 和 cgroups 实现资源隔离和限制之外,容器利用 UnionFS 提供容器镜像 (images) 的基础文件系统。UnionFS 文件系统是分层的,当我们需要修改一个文件的内容的时候,会将这个文件拷贝一份新的放到最上层的目录上然后修改文件,实际上,下层的目录并没有改动。这也是容器镜像文件系统的一个核心特性,基于此特性:
实现容器镜像的分层复用和共享,在基础镜像的基础上构建新镜像,而不需要从零开始构建,容器镜像也有自己的标准规范(https://github.com/opencontainers/image-spec),多镜像之间可以复用共享,还可以通过 DockerHub 等网站共享与分发镜像。
由于 Copy on Write 特性,在使用时需要注意避免不当的构建方式,导致镜像的 size 过大。
容器镜像中只包含必要的运行环境(依赖的库等),,同一节点上的各个容器共享 kernel,相比与虚拟机的重量级封装,镜像的 size 可以做的很小。
容器的核心特点是轻量级的资源隔离、限制和封装,极大的简化了程序运行时的环境依赖,同时还能解决多版本共存运行的问题,计算程序和运行节点之间独立,为进一步的多节点间的自动调度奠定了基础。下图展示的是容器中计算程序封装的逻辑图。其最大好处是整体运行环境的封装,在此逻辑下,用户也会逐步从传统的 make build 生成可执行文件过渡到利用 docker build 制作应用镜像,容器的使用也会越来越广泛。
总结一下,使用容器技术作为计算程序运行环境封装,带来诸多优势:
一致的运行环境,解决计算框架环境依赖、安装配置繁琐的问题;
多个计算框架可以共存运行,同一个计算框架的多版本也可以共存运行;
计算节点与运行环境独立,这是实现多节点计算自动调度的基础;
一次构建,随时随地多次运行;
基于上述容器技术带来的优势,目前主流的 AI 计算框架都支持以容器的方式运行,也逐渐成为社区的标准运行方式,TensorFlow 官方也在 Dockerhub 上直接提供 TensorFlow 各个版本的相关镜像下载。其他 AI 计算框架也以提供 Dockerfile 的形式或者直接提供 Docker images 供用户使用。同时,用户也可以根据自己的计算需求或者以自己的应用算法为基础,创建和维护专用镜像文件。
GPU计算任务容器化
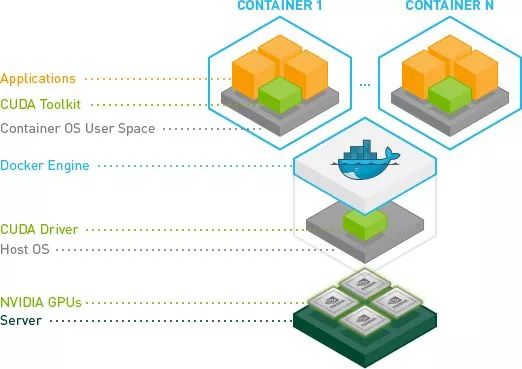
AI 算法目前使用 GPU 提供计算加速,所以,容器方式运行的 AI 计算框架需要同时支持 CPU 和 GPU 两种运行方式。CPU 版的运行和常规容器运行方式无异,GPU 版的运行方式略微复杂,为此 Nvidia 官方推出 Nvidia-docker(https://github.com/NVIDIA/nvidia-docker )工具简化 GPU 版的运行方式和流程。在介绍 nvidia-docker 工具之前,我们先看下 GPU 容器的架构逻辑图,如下所示,从下往上分为:
硬件层:在每个 GPU 计算节点上配置一个或者多个 GPU 硬件资源。
软件层:每个计算节点安装操作系统和相应的 GPU drivers。
Docker:每个计算节点安装 Docker engine 服务。
容器:容器中包含计算相关的运行环境和 CUDA 库,并且将 host 上的 GPU 设备和驱动动态库映射到容器中。
用户可以通过 docker 命令 --device 和 --volume 等参数实现 GPU 设备和动态库映射,但是,使用起来不方便,而 nvidia-docker 的功能就是简化 GPU 容器创建和运行,其是一个 wrapper 的 Bash 脚本,封装了 docker 的命令参数。从下面脚本中可以看出,当用户使用 nvidia-docker 执行 run 和 create 这两个子命令时,nvidia-docker 做了两个改变:
切换runtime 为 nvidia runtime
如果用户定义了 NV_GPU 环境变量,则将 NV_GPU 环境变量的信息传给环境变量 NVIDIA_VISIBLE_DEVICES

基于以上分析,我们可以得到两个结论:
nvidia-docker 在除 run 和 create 之外的其他子命令,和普通的 docker 并无太大区别。所以,我们没法在使用其他 docker 子命令时(比如 docker build),执行需要使用 GPU 资源的相关代码。
nvidia-docker 实现简化 GPU container 运行,实际上是通过 nvidia runtime 实现,并利用 runtime 的环境变量 NVIDIA_VISIBLE_DEVICES 控制容器中能够使用的 GPU 数量。
NVIDIA_VISIBLE_DEVICES 默认值是 all,其含义是 GPU Container 可使用计算节点上的所有 GPU 资源,用户利用 NV_GPU 控制可用 GPU 资源数量,而 nvidia-docker 脚本再将 NV_GPU 传递给 NVIDIA_VISIBLE_DEVICES。我们可以通过两种方式设置 NV_GPU:
指定 GPU index,此 index 和 nvidia-smi 显示的 GPU index 一致
指定 GPU 的 UUID
如下面所示:
# Running nvidia-docker isolating specific GPUs by index
NV_GPU='0,1' nvidia-docker
# Running nvidia-docker isolating specific GPUs by UUID
NV_GPU='GPU-836c0c09,GPU-b78a60a' nvidia-docker
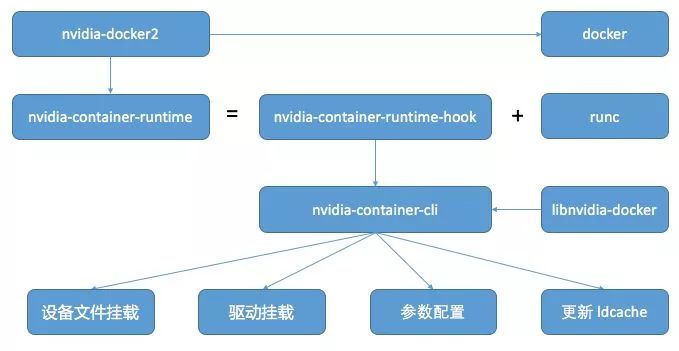
下图展示的是 nvidia-docker2 的工作逻辑图,GPU 相关的核心工作是由 nvidia-container-runtime 实现的。nvidia container runtime 是 Nvidia 定义的一种 GPU 运行环境 (https://github.com/NVIDIA/nvidia-container-runtime),基于对 runc (https://github.com/opencontainers/runc)运行环境的一种修改版本,符合 openContainer 的 OCI 标准定义。
为了提供一定的灵活性,nvidia-container-runtime 定义了一些 GPU 相关的环境变量。比如,控制 GPU 使用数目的 NVIDIA_VISIBLE_DEVICES。下面所示的是两个常用的环境变量示例。详细的环境变量参见:
https://github.com/NVIDIA/nvidia-container-runtime#environment-variables-oci-spec
NVIDIA_VISIBLE_DEVICES:控制在容器中使用的 GPU 数目,可选项:
0,1,2, GPU-fef8089b …: GPU UUID 或者 GPU 索引列表
all: 默认值,在容器中可以使用节点上的所有 GPU 资源
none: 只加载 GPU 驱动,但 GPU 设备不可使用
void or empty or unset: 等同于常规的 runc
NVIDIA_DRIVER_CAPABILITIES:控制容器如何挂载 GPU 驱动和附属文件,可选项:
compute,video,graphics,utility …: 驱动功能列表,对于 deep learning 需要开启 compute
compute: CUDA and OpenCL 计算应用
compat32: 兼容 32位计算应用
graphics: OpenGL and Vulkan 图形应用
utility: nvidia-smi and NVML 等命令行工具使用
video: 视频编解码
all: 开启驱动所有功能
empty or unset: 空或者不设置,默认值为:utility
我们根据nvidia-container-runtime Github 上的代码,具体分析其是如何工作的。首先,我们看一下 nvidia-container-runtime 如何编译出来的,通过下面节选的关键代码,nvidia-container-runtime 是在 runc 代码的基础上,打上一个 patch,然后编译,并重命名为 nvidia-container-runtime。

此 patch 加了一个 prestart Hook,在容器创建时,执行程序 nvidia-container-runtime-hook。除此改动之外,nvidia-container-runtime 其余相关的功能依赖 runc 实现。nvidia-container-runtime-hook 是一个 go 语言实现的可执行程序,主要功能是读取当前容器的配置信息 config.json,和 runtime 配置文件 /etc/nvidia-container-runtime/config.toml,并处理 runtime 定义的环境变量。
nvidia-container-runtime-hook 的上述功能是通过调用 nvidia-container-cli 实现 (https://github.com/NVIDIA/libnvidia-container),nvidia-container-cli 也是 Nvidia 官方维护的一个 GPU 工具,其主要功能包括:
加载 GPU 驱动运行动态库
挂载 GPU 设备文件
配置参数
更新系统动态库缓存
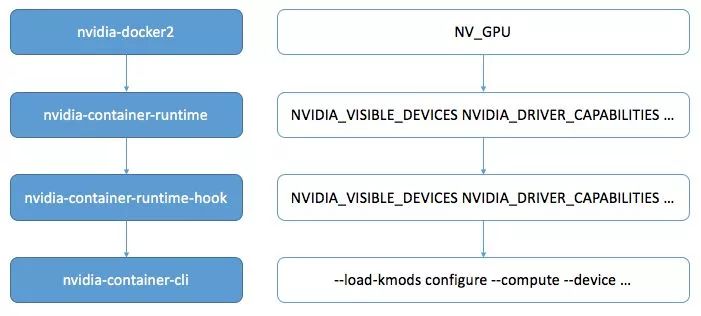
下图展示的是 nvidia-docker2 调用逻辑与环境变量传递图,从 nvidia-docker2 开始,容器最终的 GPU 配置由 nvidia-container-cli 执行。图中右侧是用户可以设置的环境变量传递图,从 nvidia-docker2 层级的 NV_GPU 到最终转化为 nvidia-container-cli 命令的 --compute --device 等参数。
总结
本篇针对如何简单有效的实现在单机上使用 GPU 和 TensorFlow 等 AI 计算框架,深入介绍任务容器化的基本思路和概念,详细分析了 nvidia-docker2 的工作流程和实现逻辑。借助 nvidia-docker2,在单机上运行 AI 计算任务更加方便,解决了安装配置框架以及多版本共存运行的问题,也避免了配置使用 GPU 的繁琐工作量。
本篇为 AI 计算系列:从单机到集群(上),那么后续篇 —— 从单机到集群(中)继续为大家带来 AI 计算系列的分享,将在本篇介绍单机 AI 计算的基础上,实现从单机到集群的跨越,重点介绍如何构建面向 AI 计算的 GPU 集群,分析最新 AI 计算集群的 GPU 资源调度逻辑,帮助大家更进一步理解如何实现多机 GPU 资源的自动分配和管理。
-
物联网未来发展趋势如何?2025-06-09 2078
-
云计算技术的未来发展趋势2024-10-24 4361
-
未来AI大模型的发展趋势2024-10-23 3242
-
物联网未来发展趋势2022-03-11 5913
-
云计算产业发展现状及趋势2021-07-27 5335
-
未来PLC的发展趋势将会如何?2021-07-05 3677
-
蜂窝手机音频架构的未来发展趋势是什么2021-06-08 2478
-
电源模块的未来发展趋势如何2021-03-11 3167
-
灵动微对于未来MCU发展趋势分析2020-12-23 2381
-
云知声打磨四年的AI芯片出炉2020-05-05 2030
-
云计算的未来趋势及入门云计算介绍2019-06-19 2541
-
蓝牙技术未来的发展趋势2019-03-29 4045
-
公众wifi的未来发展趋势2014-04-09 3139
全部0条评论

快来发表一下你的评论吧 !
