

关于分布式训练的线性加速实践详解
描述
分布式训练需求
Deep Learning 在过去几年中取得了长足的发展,尤其在语音、图像、机器翻译、自然语言处理等领域更是取得了飞跃式的提升,但与之相伴的是模型越来越复杂,参数量越来越大,例如: Inception v3参数量约 25million,ResNet 152 拥有 60million 参数、VGG16 约 140million 参数,Deep Speech 2 参数量更是超过300million,一些语言模型参数量甚至超过 1billion (Exploringthe Limits of Language Modeling)。数据并行训练方式要求每个 GPU 节点拥有一份完整的模型参数副本,并在融合梯度时发送和接收完整的梯度数据,巨大的通信数据量给多机多卡并行训练带来了极大的网络通信压力。
另一方面,越来越多的机器学习领域开始转向 DeepLearning 比如 TTS、NLP。这意味着 GPU 集群的用户(研发人员)数量将大幅膨胀。如何在多用户环境下更高效的分配、利用 GPU 资源?一个办法是计算资源以 GPU 为单位分配给用户,而不管这些 GPU 是否在同一台物理机上。这种分配方式的资源利用率虽高但同时也要求分布式训练效率要足够高,高到可以忽略跨机通信时延。
以上两方面原因促使我们必须寻找更高效的通信算法,最大限度释放 GPU 集群的并行计算能力。
分布式训练的通信方法和问题
模型参数量的大小与计算量不是成简单的正比关系,比如相同参数量的全连接模型和 CNN 的计算量相差了几个数量级,但模型的参数量与分布式训练的网络通信代价一定是正相关的,尤其是超大模型,跨节点同步参数通常会造成严重的网络拥塞。
主流的 Deep Learning 框架解决参数同步的方式有两种:同步更新和异步更新。同步更新模式下,所有 GPU 在同一时间点与参数服务器交换、融合梯度;异步更新模式下,GPU 更新参数的时间点彼此解耦,各自独立与参数服务器通信,交换、融合梯度。两种更新模式各有优缺点,为了文章不失焦点并限制篇幅,这里不做展开讨论了,我们只列出结论:
异步更新通信效率高速度快,但往往收敛不佳,因为一些速度慢的节点总会提供过时、错误的梯度方向
同步更新通信效率低,通常训练更慢,但训练收敛稳定,因为同步更新基本等同于单卡调大 batch size 训练
在实际生产环境中,我们通常很看重模型效果和训练速度,但当鱼与熊掌不能兼得时,模型效果还是更重要一些的,为此牺牲一些训练速度也不是不可接受,所以同步更新基本是主流方法
那么如何解决同步更新的网络瓶颈问题呢?学者和工程师想出了多种优化方法,比如结合同步更新和异步更新、半精度训练、稀疏梯度更新等等。限于篇幅,我们无法一一展开,在本文中,我们只介绍一种方法:Ring Allreduce 。
如何搭建一套高效的分布式训练框架
通过上面的分析,以及日常工作中的经验,我们通常认为一个理想的 GPU 集群应包含这样几个特性:
1. GPU 跨机并行,达到近似线性加速比
2. 用户以 GPUs 为单位申请资源,物理节点对用户透明
3. 使用要简单,甚至单机单卡、单机多卡、多机多卡可以由一套代码实现
目标确定了,就来看看如何搭建这样一套系统,我们选择如下几个组件:Kubernetes 、TensorFlow 以及 Horovod。
Kubernetes 是目前最流行的开源容器集群管理系统,在我们的系统中,Kubernetes 主要负责负责集群的容器化管理,包括 GPU 资源的申请、释放、监控等。
TensorFlow 是 Google 大力推广的基于数据流图的 Deep Learning 框架,无论是使用者数量还是社区活跃程度,都遥遥领先其他竞争对手,在我们的系统中主要负责各个业务线上深度模型的搭建。
Horovod 是 Uber 新近开源的高效分布式训练通信框架,Horovod 本身只负责节点间网络通信、梯度融合,在运行时需要绑定 TensorFlow 做单机运算。
这里有两个问题需要说明一下:
1. TensorFlow 框架本身已经支持分布式训练,为什么不直接使用呢?
因为 TensorFlow的分布式框架是基于参数服务器的,这种结构容易造成网络堵塞;
并且开源版 TensorFlow 的跨机通信是通过 gRPC + ProtocolBuffers 实现的,这种方案的问题是,首先 gRPC 本身的效率就比较差,其次使用 Protocol Buffers 序列化就意味着节点间的所有交互必须经过内存,无法使用 GPUDirect RDMA,限制了速度提升;
即使抛开性能问题,编写 TensorFlow 的分布式代码也是一件十分繁琐的工作,有过相关经验的同学应该有所体会。
2. Horovod 是一个较新的分布式训练通信框架,它有哪些优势呢?
Horovod 有如下主要特点:Horovod 可以实现接近 0.9x 的加速比;
一套代码实现单机单卡、单机多卡、多机多卡;社区活跃,代码迭代速度快,作为对比 Baidu Allreduce 已经停止维护了。
在接下来的两小节中,我们将分别介绍 Horovod 的核心算法和以及部署实践。
Horovod 核心算法
Ring Allreduce ,原是 HPC 领域一种比较成熟的通信算法,后被 Baidu SVAIL 引入到 Deep Learning 训练框架中,并于 2017年2月公开 。 Ring Allreduce 完全抛弃了参数服务器,理论上可以做到线性加速。Ring Allreduce 算法也是 Horovod 的核心,Horovod 对 Baidu SVAIL 的实现做了易用性改进和性能优化。
在这一节中,我们会详细介绍 Ring Allreduce 的算法流程:。
PS WORKER 框架下同步更新方式,以及网络瓶颈定量分析
我们来定量分析一下,同步更新的网络瓶颈问题,以 Deep Speech 2 为例:
模型包含 300M 参数,相当于 1.2 G 的大小的内存数据(300M * sizeof(float))
假设网络带宽 1G bytes/s (万兆网卡)
2 卡同步更新,需要 1.2 s 完成参数 Send(这还不算 Receive 的时间)
10 卡同步更新,需要 9.8 s 完成参数 Send
通过简单的计算会发现,在单 ps 节点、有限带宽环境下,通信时间随着 GPU 数量的增加而线性增长,很难想象一个10卡的集群每训练一个 batch 都需要等待 10 ~ 20s 来同步参数!通信时延几乎完全覆盖掉了 GPU 并行计算节节省下的计算时间,当然在实际训练环境中,网络速度也是能达到几十 Gbps 的,而且通常也会多设置几个 ps 节点,比如每个物理节点设置一个 ps ,这样可以减轻带宽瓶颈,但这些措施都没有从根本上解决问题。

Ring Allreduce 框架下同步更新方式
在上面的通信方式中,网络传输量跟 GPU 成正比,而 Ring Allreduce 是一种通信量恒定的通信算法,也就是说,GPU 的网络通信量不随 GPU 的数量增加而增加,下面我们会详细说明一下 Ring Allreduce 框架下 GPU 的通信流程。
首先定义 GPU 集群的拓扑结构:
GPU 集群被组织成一个逻辑环
每个 GPU 有一个左邻居、一个右邻居
每个 GPU 只从左邻居接受数据、并发送数据给右邻居。
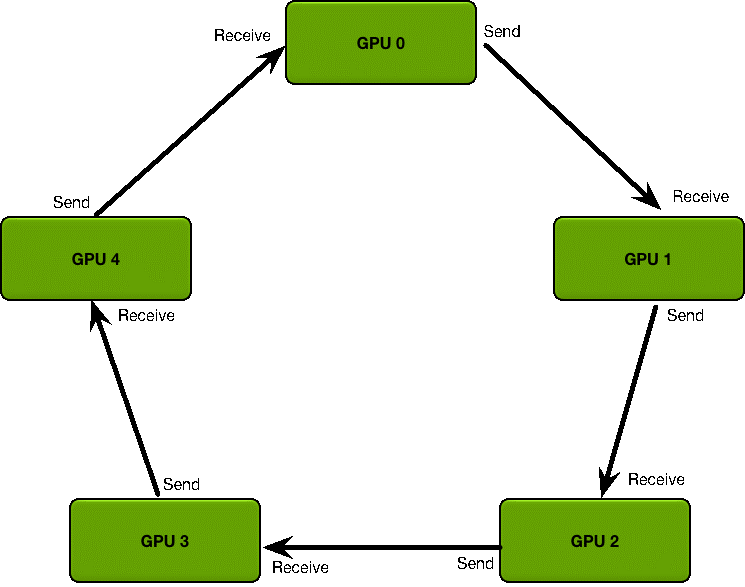
梯度融合过程分为两阶段:
1. Scatter Reduce :在这个 Scatter Reduce 阶段,GPU 会逐步交换彼此的梯度并融合,最后每个 GPU 都会包含完整融合梯度的一部分
2. Allgather :GPU 会逐步交换彼此不完整的融合梯度,最后所有 GPU 都会得到完整的融合梯度
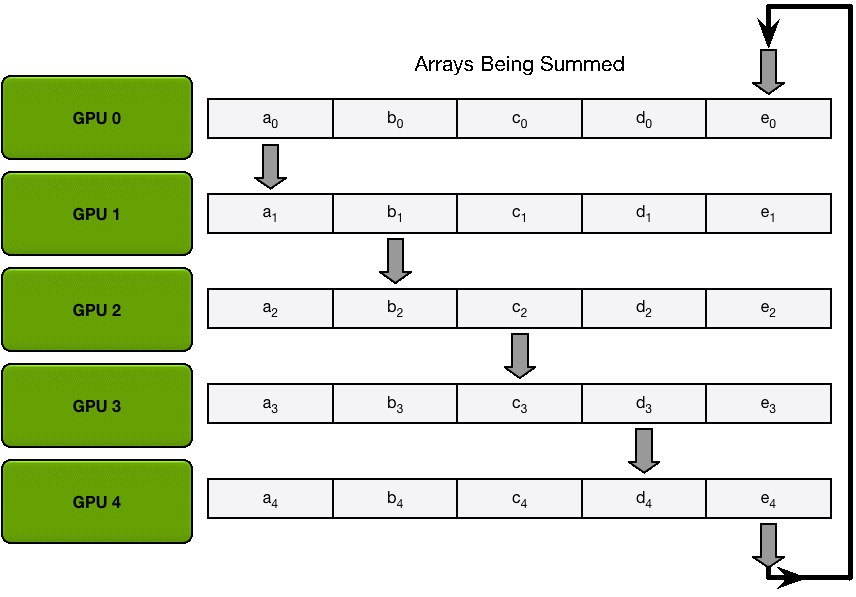
Scatter Reduce
为了方便说明,我们用梯度加和代替梯度融合。假设集群中有 N 个 GPU,那么将梯度数据等分为 N 份,接下来将在 GPUs 间进行 N-1 次 Scatter Reduce 迭代,在每一次迭代中,每个 GPU 都会发送所有梯度数据的 1/N 给右邻居,并从左邻居接收所有梯度数据的 1/N 。同一次 Scatter Reduce 迭代中,发送和接收的数据块的编号是不同的,例如,第一轮迭代,第 n 个 GPU 会发送第 n 号数据块,并接收第 n-1 号数据块。经过 n-1 轮迭代,梯度数据会像图2 所示,每个 GPU 都包含了部分完整梯度信息。
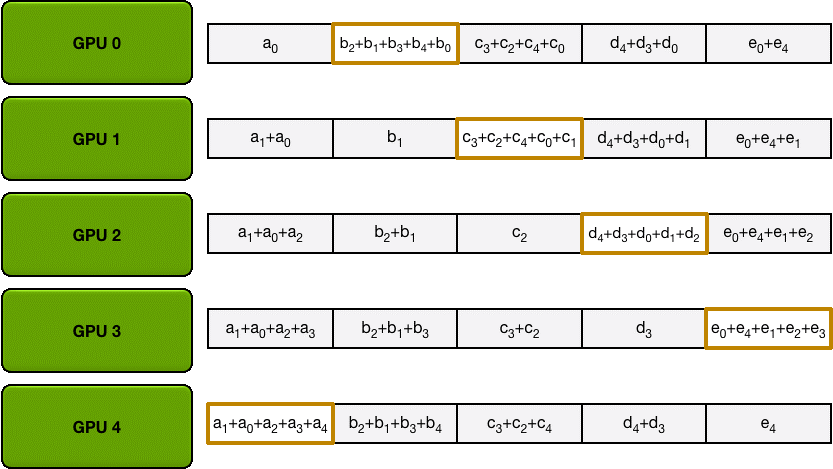
Allgather
和 Scatter Reduce 阶段类似,只不过这里只拷贝不求和,最终每个GPU 都得到了所有融合后的梯度。
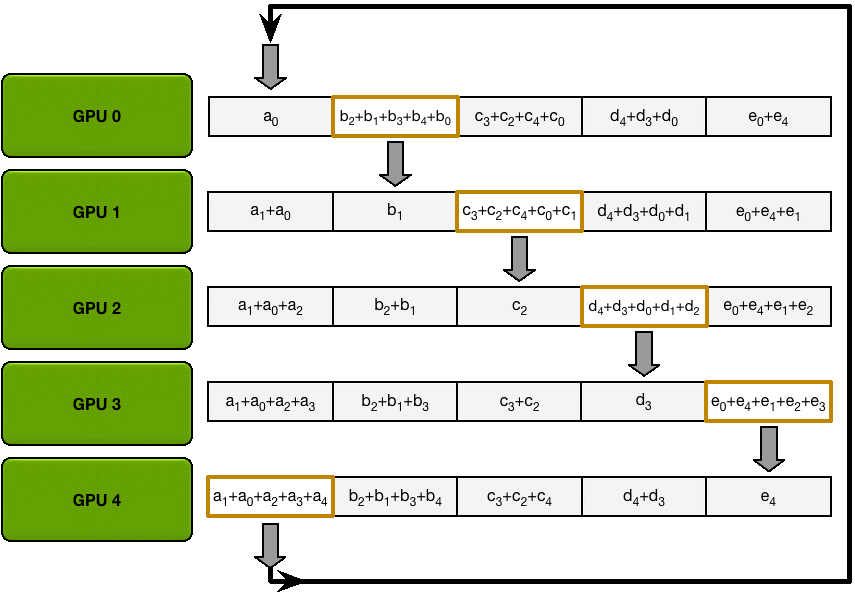

这么做有什么好处呢?
下面我们来定量的分析一下,每个 GPU 在Scatter Reduce 阶段,接收 N-1 次数据,N 是 GPU 数量;每个 GPU 在allgather 阶段,接收 N-1 次 数据;每个 GPU 每次发送 K/N 大小数据块,K 是总数据大小;所以,Data Transferred=2(N−1)*K/N =
(2(N−1)/N)*K,随着 GPU 数量 N 增加,总传输量恒定!总传输量恒定意味着通信成本不随 GPU 数量增长而增长,也就是说我们系统拥有理论上的线性加速能力。再回到 DS2 的例子,300million 参数也就是 1.2Gb 数据量,Ring Allreduce 方式更新一次需要传送并接收 2.4Gb 数据,假设网络使用 GPUDirect RDMA + InfiniBand,GPUDirect RDMA 带宽约为10Gb/s;InfiniBand 带宽约为 6Gb/s,所以通信瓶颈在 InfiniBand 。(2.4Gb)/(6.0Gb/s) ≈ 400ms,也就是每轮迭代需要 400 ms 做参数同步,这 400ms 的数据传输时间是恒定的,不随 GPU 数量增加而增加。
在 Kubernetes 环境部署 Horovod
Kubernetes 是一套容器集群管理系统,支持集群化的容器应用,从使用角度看
Kubernetes 包含几个重要的概念:
1. pod,pod 由一个或多个容器构成,在问本文描述的场景下,一个 pod 包含一个容器,容器中包含1个或多个 GPU 资源
2. Services,对外提供服务发现,后面通常会对接容器实例
3. YAML , YAML 是一种类似 JSON 的描述语言 ,在 Kubernetes 中用 YAML 定义 pod 、Service 、Replication Controller 等组件
4. kubectl,kubectl 是一套命令行工具,负责执行开发人员和 Kubernetes 集群间的交互操作,例如查看 Kubernetes 集群内 pod 信息汇总 kubectl get pod;查看 Kubernetes 内物理节点信息汇总 kubectl get node
另外,近期我们还会有一篇详细介绍 TensorFlow on Kubernetes 的文章,所以关于 Kubernetes 的详细信息本文就不赘述了。
Build image
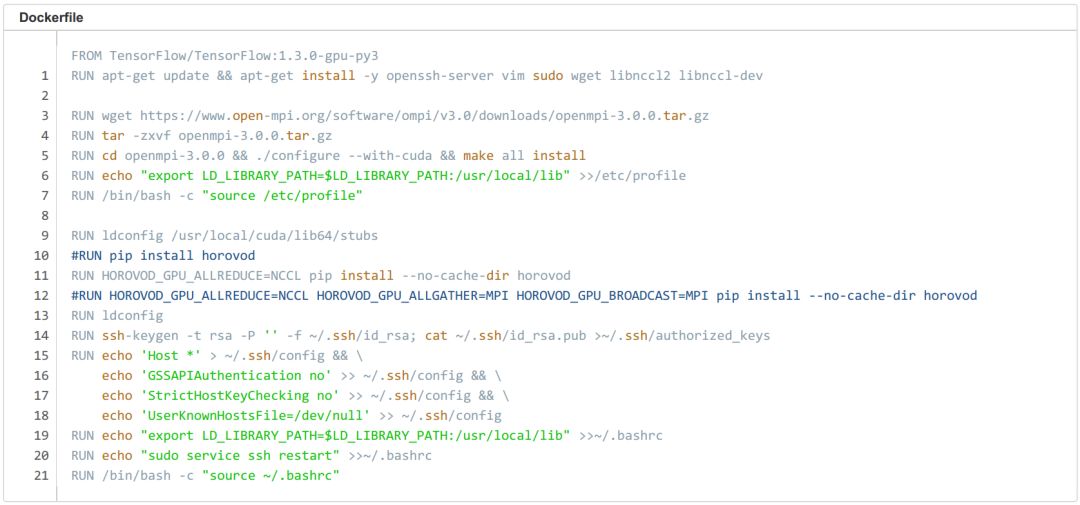
首先我们需要创建一个 Horovod 镜像,这个镜像需要包含 TensorFlow 环境 、Horovod 环境 、以及 OpenMPI 的免密的登陆配置,我们可以选择 TensorFlow:1.3.0-gpu-py3 作为基础镜像,通过 Dockerfile 逐步安装 Horovod 环境及 Open MPI 免密登陆配置。
第一步,安装 Horovod 相关依赖:apt-getupdate ; apt-get install -y openssh-server wgetlibnccl2 libnccl-dev。
第二步,下载并安装 Open MPI ,注意:如果你的网络环境支持 RDMA,那你需要带 --with-cuda 参数从源码配置安装:./configure --with-cuda ; make all install。
第三步,安装 Horovod :HOROVOD_GPU_ALLREDUCE=NCCLpip install --no-cache-dir horovod,
第四步,设置 MPI SSH 免密登陆环境,方法见下面的 Dockerfile。
编写完成 Dockerfile 后,我们就可以 build 镜像了:docker build -t horovod:v1 . 。
MPI on Kubernetes 相关问题
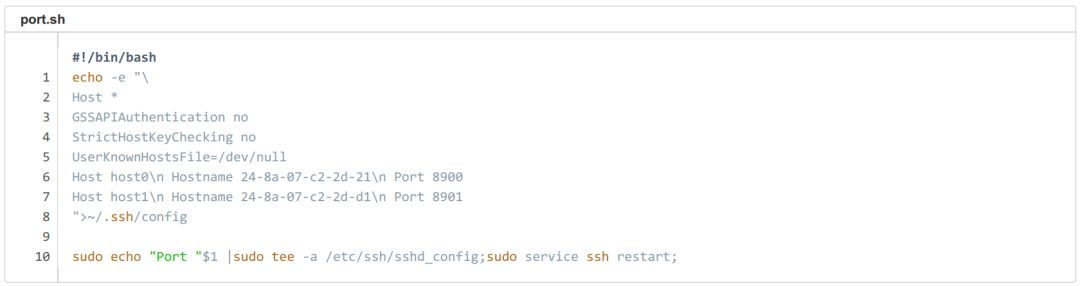
我们在调试过程中发现,Kubernetes 环境运行 Open MPI 必须将 pod 设置为 host 网络模式,否则 MPI 节点间通信时会 hang 住。host 网络模式的问题在于它会占用宿主机端口号,多用户环境下会有冲突,所以我们还需要想办法为每个 pod 独立设置一个 SSH 端口号,并通知集群里所有 Horovod 节点。
方法详见下面的脚本:脚本在 pod 创建时启动,其中 Host** 为集群中所有节点的节点名和 SSH 端口号,脚本的最后一行作用是更改本机的 SSH 端口号。这种方法可行但并不优雅,所以如果你有其他更好的方案,请在文章下方留言告诉我。
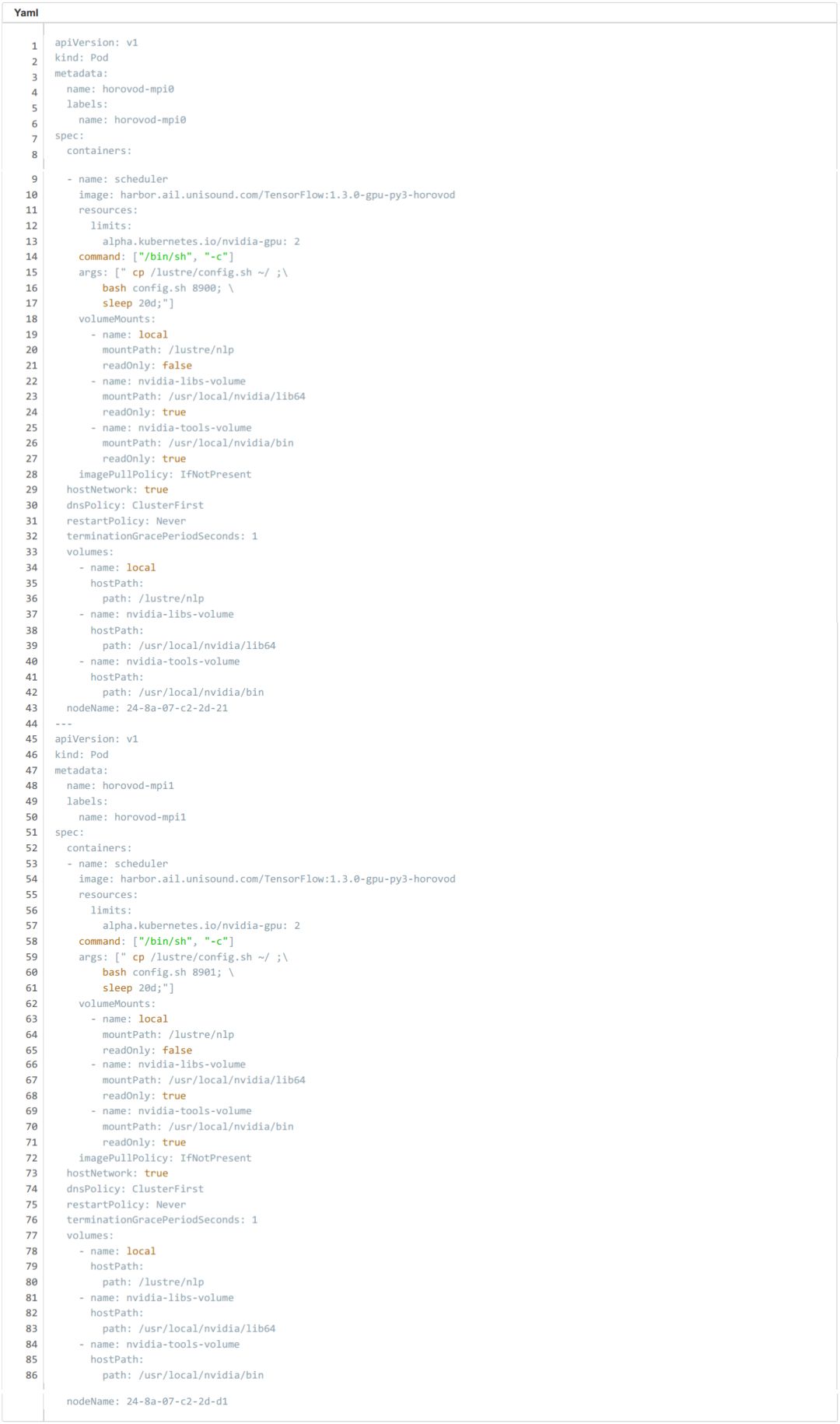
Pod yaml
这里我们申请 2 pod,每个 pod 各 2 个 GPU ,horovod-mpi0 的 SSH 端口设置为 8900 ;horovod-mpi1 的 SSH 端口设置为 8901。
测试脚本及 Benchmark
· 集群环境:Kubernetes,两机两卡,1080ti
启动脚本:
如果将 Benchmark 整理成图表,那么看起来是这样的。
在普通以太网环境下, 2 机 4 卡相比单机单卡,Horovod 可加速 3.6 倍。
-
分布式软件系统2009-07-22 5187
-
LED分布式恒流原理2011-03-09 5401
-
基于分布式调用链监控技术的全息排查功能2018-08-07 3109
-
分布式光纤测温系统DTS2018-10-18 3884
-
关于分布式系统的全面介绍2019-07-25 2070
-
分布式系统的优势是什么?2020-03-31 2941
-
HarmonyOS应用开发-分布式设计2020-09-22 2590
-
如何高效完成HarmonyOS分布式应用测试?2021-12-13 2367
-
分布式系统硬件资源池原理和接入实践2023-12-06 589
-
GL Studio的分布式虚拟训练系统关键技术2011-03-22 923
-
关于分布式系统的几个问题2020-09-23 3568
-
探究超大Transformer语言模型的分布式训练框架2021-10-20 3422
-
欧拉(openEuler)的分布式能力加速举例2021-11-10 2055
-
基于PyTorch的模型并行分布式训练Megatron解析2023-10-23 5381
-
分布式通信的原理和实现高效分布式通信背后的技术NVLink的演进2024-11-18 2138
全部0条评论

快来发表一下你的评论吧 !
