

回顾驭势联合新加坡国立大学推出东风网络的理解
电子说
描述
给定目标硬件,如何确定最优的速度-精度折衷边界?换言之:给定推断延时的限制,模型能达到的最高精度是多少?给定精度要求,模型所需的最短延时是多少?

为此,驭势科技AI研究院联合新加坡国立大学提出了偏序关系剪枝(Partial Order Pruning)方法,直接考虑模型在目标硬件上的延时,利用偏序关系假设对搜索空间进行剪枝,平衡模型的宽度与深度,以提高速度-精度折衷的边界。应用该方法所得的东风(DF)骨干网络,取得了目标硬件(TX2)上的最优速度-精度折衷。应用该方法于语义分割网络Decoder的结构搜索,所得的东风分割网络(DF-Seg)也取得了TX2/1080Ti上最优的速度-精度折衷。
在实际运用当中,具备多重实用价值,主要体现在以下几个方面:
(一)DF/DF-Seg网络的实用价值
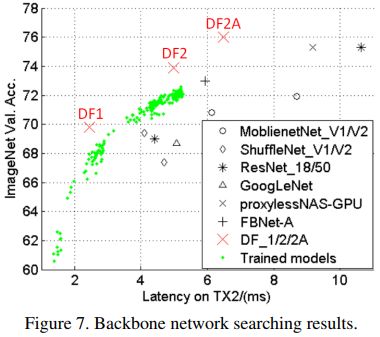
(1)DF网络取得了目标硬件(TX2)上最优的速度-精度折衷。
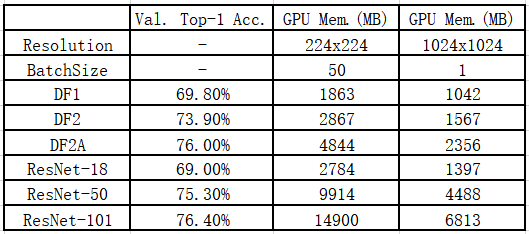
(2)DF网络节约显存。以DF2A网络为例,其精度介于ResNet50/101之间,而仅需1/3至1/2的显存(以BVLC Caffe测试)。
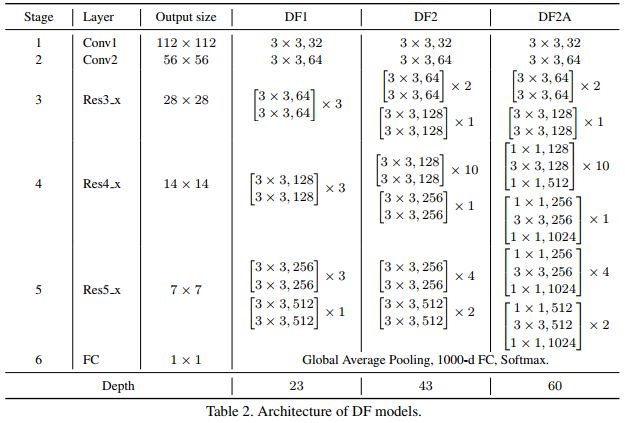
(3)DF网络结构简单,仅使用基本的残差模块,相当于更“精耕细作”的ResNet。
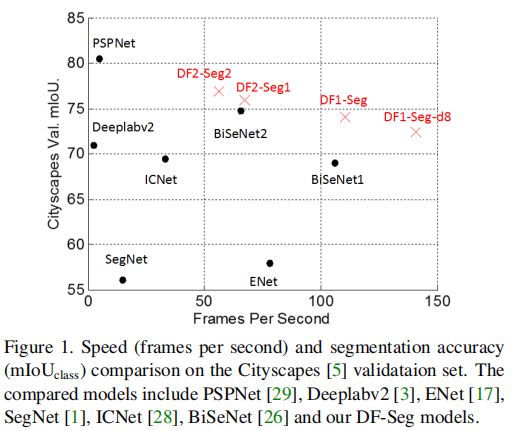
(4)DF-Seg网络是TX2/1080Ti/Titan X(Maxwell)上速度-精度折衷最好的分割网络。
省时间、省显存、结构简单,使得DF/DF-Seg网络有助于在嵌入式设备TX2上部署高精度、低延时、多路图像并行处理的CNN模型;有助于高端GPU上的视频处理、大规模图像数据处理等任务的部署;有助于科研人员,尤其是计算资源不足的科研人员,节省计算资源,实现更复杂的算法。
(二)偏序关系剪枝算法的实用价值
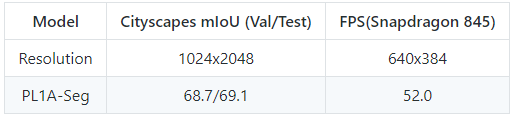
DF网络更适合GPU平台,我们也利用偏序关系剪枝算法,在骁龙845 CPU平台上进行了骨干网络结构与分割网络Decoder结构的搜索,所得语义分割网络得到了目前CPU平台上最好速度-精度折衷。
以下为该论文内容翻译:
一、偏序关系剪枝算法
(一)搜索空间设计与模型结构编码
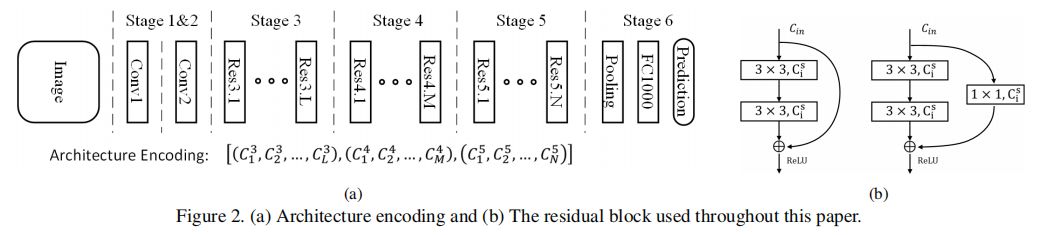
图2(a)为本文的模型搜索空间,图2(b)为本文使用的残差模块结构。网络由6个Stage构成,Stage1~5均通过设步长为2降低输入特征的分辨率,Stage6通过全局池化与全连接层产生分类结果。本文的模型搜索不搜索基本模块的结构,而是在基本残差模块的基础上,对网络整体的宽度与深度进行平衡。在Stage3~5,模型分别包含L/M/N个残差模块,Stage s中的第i个残差模块的宽度记为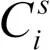 ,因此本文将一个结构表示为:
,因此本文将一个结构表示为:
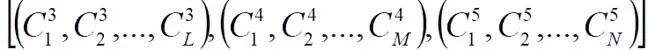
(二)模型延时估计与子搜索空间
图2(a)所表达的搜索空间记为s,实践中我们仅关心延时在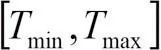 中的子集,即
中的子集,即 。为估计各网络的延时,我们使用TensorRT提供的性能分析工具,在目标硬件TX2上,测量了不同的残差模块所需的延时,并建立一个查找表
。为估计各网络的延时,我们使用TensorRT提供的性能分析工具,在目标硬件TX2上,测量了不同的残差模块所需的延时,并建立一个查找表
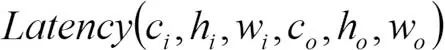
。这里, 分别是输入输出特征的通道数,而
分别是输入输出特征的通道数,而
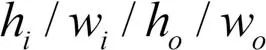
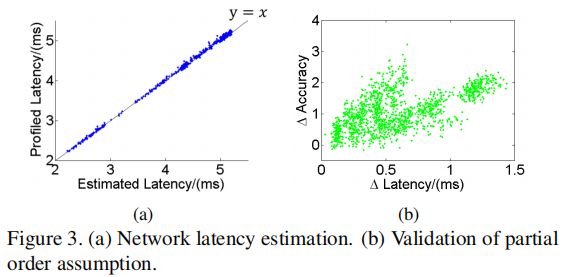
是相应的空间尺寸。利用该查找表将各残差模块延时进行加和记为对一个网络延时的估计。在图3(a)中,我们对若干网络的估计延时与实际延时进行了比较,可见估计延时与实际延时基本一致。
(三)偏序关系假设
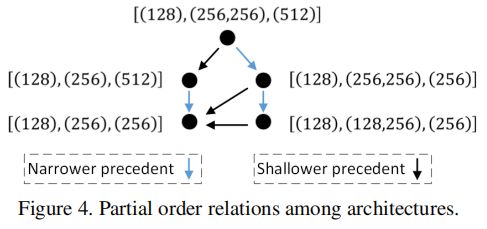
我们借用集合论中的偏序(Partial Order)关系来描述模型结构之间的联系:集合中的元素为不同的模型结构(见图2(a)),集合中的二元关系定义为:若x比y更浅且更窄,则称x是y的前序,记为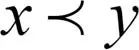 。如此,整个搜索空间中的模型结构就满足了严格偏序关系,包括反自反性、反对称行、传递性。图4给出了若干模型结构间偏序关系的示意图。偏序关系假设为:若x是y的前序(意味着x比y更浅且更窄),则x的速度更快,精度更低。这可以写为:
。如此,整个搜索空间中的模型结构就满足了严格偏序关系,包括反自反性、反对称行、传递性。图4给出了若干模型结构间偏序关系的示意图。偏序关系假设为:若x是y的前序(意味着x比y更浅且更窄),则x的速度更快,精度更低。这可以写为:
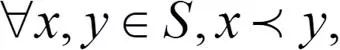
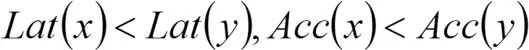
在图3(b)中,我们基于已训练的模型,对偏序关系假设的合理性进行了验证,其中,
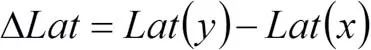
,
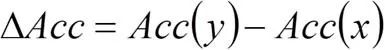
。可见,在本实验所关心的模型子空间中,偏序关系假设是合理的。
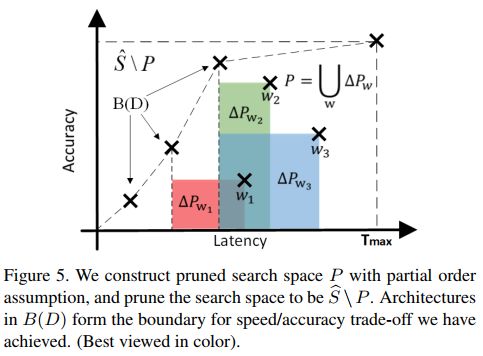
(四)偏序关系剪枝
基于偏序关系假设,我们可以在模型搜索中对搜索空间进行剪枝。图5是该剪枝过程的一个示意图。集合 为已训练的模型结构,集合
为已训练的模型结构,集合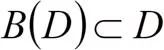 中的模型代表了当前迭代中所能达到的最优速度-精度折衷边界。对于一个非边界模型
中的模型代表了当前迭代中所能达到的最优速度-精度折衷边界。对于一个非边界模型
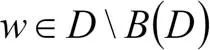
,其任意前序模型

,应有:
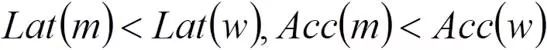
而我们已有速度-精度折衷更好的边界点:
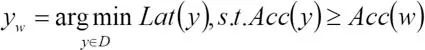
因此w的部分前序元素 ,延时将比
,延时将比 高,而精度将比低,也即处于图5的阴影部分。这些
高,而精度将比低,也即处于图5的阴影部分。这些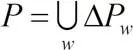 中的模型结构无法提供更好的速度-精度折衷,可以据此对搜索空间进行剪枝:
中的模型结构无法提供更好的速度-精度折衷,可以据此对搜索空间进行剪枝: 。如此反复迭代,在迭代中不断对搜索空间进行剪枝,直至速度-精度折衷的边界趋于稳定,如算法1所描述。
。如此反复迭代,在迭代中不断对搜索空间进行剪枝,直至速度-精度折衷的边界趋于稳定,如算法1所描述。

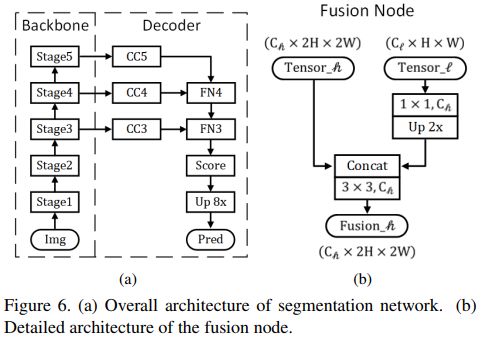
(五)语义分割网络的Decoder设计
本文中语义分割网络的结构设计如图6所示,在Stage 5中加入了pyramid pooling module,使用图6(b)所示的Fusion node融合不同分辨率的特征,其中Channel Controller(CC)为1x1卷积,用以控制Decoder在不同分辨率下的宽度。不同的 ,构成了不同复杂度的Decoder结构。这些Decoder结构之间也存在着偏序关系假设,因此也可以使用偏序关系剪枝算法对搜索空间进行剪枝。
,构成了不同复杂度的Decoder结构。这些Decoder结构之间也存在着偏序关系假设,因此也可以使用偏序关系剪枝算法对搜索空间进行剪枝。
二、实验数据
(一)TX2上的骨干网络搜索
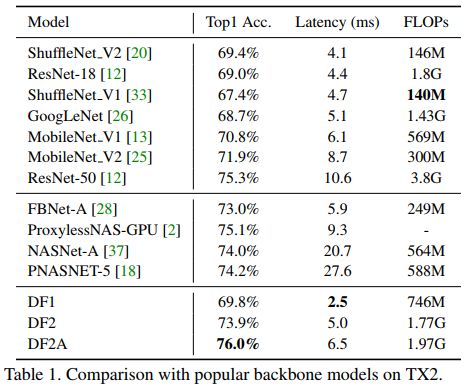
我们在TX2上进行骨干网络的搜索,最终选取3个最有代表性的网络,记为3个东风(DF)骨干网络。如图7与表1所示,DF网络取得了TX2上最好的速度-精度折衷。
DF1网络FLOPs明显高于MobileNet于ShuffleNet等,但在TX2上实际延时更低。这是因为FLOPs作为间接指标,仅考虑了浮点计算量而没有考虑内存访问的延时。以ShuffleNetV2与DF1为例,其内存访问代价(也即中间层的特征),分别为4.9M与2.9M。
NASNet与PNASNet在网络结构搜索中均未考虑模型延时,所得模型结构复杂,内存访问量大,实际延时较高。有一些同期工作(ProxylessNAS/FBNet)也在模型搜索中考虑了模型延时,DF网络在速度-精度折衷上也优于这些模型。这是因为:一、这些模型未针对TX2平台进行模型搜索;二、这些网络均基于MobileNetV2的inverted bottleneck模块,相比本文使用的残差模块,内存访问量更高。
(二)TX2/1080Ti上的Decoder网络结构搜索
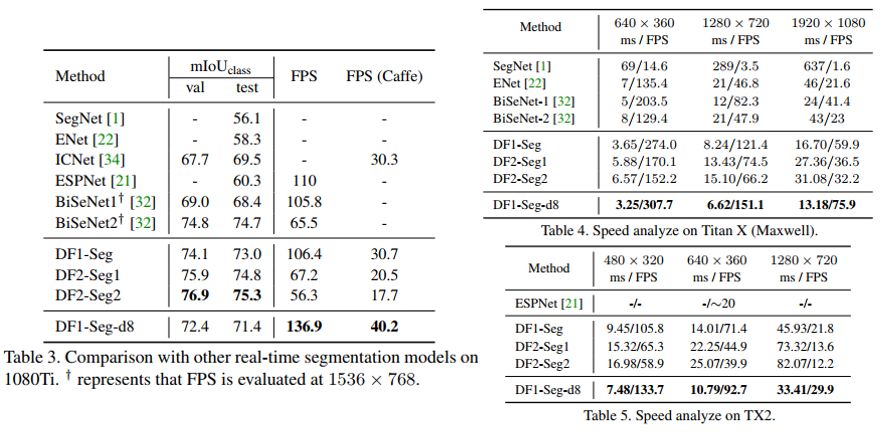
基于TX2上搜索的东风骨干网络,我们也在TX2/1080Ti上分别进行了Decoder结构搜索。如表3所示,东风分割网络(DF-Seg)是目前1080Ti上速度-精度折衷最好的语义分割网络。DF-Seg网络的速度(FPS)与精度(mIoU)均在1024x2048的分辨率下,使用TensorRT提供的性能分析工具在1080Ti上进行测试。为与ICNet公平对比,在FPS(Caffe)栏中使用“Caffe Time”工具,在Titan X(Maxwell)上进行速度测试。表4与表5分别为Titan X(Maxwell)/TX2上的速度测试,DF-Seg的速度大幅优于现有结果,能够在TX2上实现对720P分辨率图像的30FPS的语义分割。
-
***国立大学经典PLL讲义(内行人都知道)2011-12-07 73974
-
新加坡国立大学研发了EsoGlove轻便智能康复设备2018-07-15 4676
-
2019 QS世界大学排名公布,清华成为唯一一所进入前20的内地高校2019-03-02 14148
-
关于驭势科技11月大事件回顾2019-09-19 1867
-
回顾驭势科技荣获“2017年度AI新锐企业奖”的介绍2019-09-20 1218
-
语音识别重大突破!快商通&新加坡国立大学联合论文入选ACL 20202020-04-21 2526
-
东风公司联合驭势科技、元戎启行等企业,共同建设自动驾驶车队2020-08-27 1043
-
新加坡发明更快速持久的防伪新技术2021-02-26 2197
-
新加坡国立大学开发出能为LED和传感器供电的新型芯片2021-05-25 2234
-
新加坡国立大学:摩擦电纳米发电机支持可穿戴传感器和电子设备用于可持续物联网集成绿色地球2022-11-25 2110
-
新加坡国立&天大EES:WO3晶面设计,实现高性能光辅助Li-O2电池!2023-02-03 3217
-
新加坡国立大学(NUS)理学院:研发新型光场传感器 可助力自动驾驶汽车2023-05-16 1161
-
中国制造走进海外名校!国仪量子EPR200M交付新加坡国立大学2023-12-22 1276
-
Living Well Digitally:由新加坡国立大学可信互联网和社区中心发起并由 DQ 提供支持的全球倡议2024-04-21 923
全部0条评论

快来发表一下你的评论吧 !
