

关于加快CNN模型在计算资源受限的应用场景的速度的分析研究
电子说
描述
自驭势科技AI男子天团出道以来,大家都在求“不是博士的小伙伴韦涛的心理阴影面积”。
正确答案是,他的内心没有阴影!他忙着给大家解读一篇有意思的论文呢!
韦涛,毕业于北京大学软件与微电子学院,处女座……
他用“乐观,踏实,好奇心重”三个词来形容自己。作为驭势科技AI天团成员,除了顔值,还需要会写代码,会搞算法,会调板子,会调车子。如果问他,怎么给好基友介绍驭势科技?韦涛说,这里是一个仰望星空,脚踏实地的地方。而青春,就意味着努力工作。
对于那些对AI感兴趣的朋友,韦涛特别推荐《深度学习》“大花书”给大家。
能不能看懂,就看你的IQ了~

该论文主要通过利用Batchnorm Layer中的Scale参数来对模型中通道重要程度进行建模,并引入了L1正则项来对该通道权值进行稀疏化训练,使得最终得到的模型可以更有效的实现通道剪枝,达到网络稀疏化的目标。该论文的通道稀疏化的实现方式非常巧妙。
近些年来,CNN由于其出色的表现,渐渐成为了图像领域中主流的算法框架。
在自动驾驶领域中,许多任务同样可被抽象为图像分类、图像分割、目标检测三个基础问题,因此,CNN在自动驾驶领域中的应用也越来越广泛。
CNN的表现如此突出主要是因为CNN模型有大量的可学习参数,使得CNN模型具备很强的学习能力和表达能力,然而,也正因为这些大量的参数使得在硬件平台上部署CNN模型时有较大困难,尤其是在一些计算资源非常受限的平台上,如移动设备、嵌入式设备等。
在自动驾驶场景中,视觉系统在整个车辆系统中一直扮演着一个十分重要的角色,在视觉算法实际投入应用时,不仅需要算法精度达到极高的指标,也对算法的实时性提出了较高的要求,与此同时,由于场景的特殊性,在自动驾驶场景中算法往往会被部署在一些计算能力较弱的嵌入式开发平台上,因此,如何让CNN模型在计算资源受限的应用场景中跑的更快成为了一个越来越重要的课题。
目前对CNN模型进行加速的方法很多,例如,从快速网络结构设计的角度出发设计设计一些小而精的模型(squeezenet、mobilenet、enet等),从网络压缩角度出发对训练好的网络在保证精度不变或小幅下降的前提下进行压缩剪枝(deep compression、channel-pruning等)等。
摘要
一直以来,由于受限于CNN模型的计算量,在各种实际应用场景中部署CNN模型一直都是个问题。本文提出了一种新型的网络学习方法以达到如下的三个目标:(1)减少模型大小(2)减小运行时内存 (3)减少计算量。
为了实现上述目标,本文主要通过强制增加channel-level的参数并对该参数进行稀疏化训练来实现。与其他的方法不同的是,本文的算法直接应用于训练的环节中,以增加少量计算开销的前提下实现了网络的稀疏化训练。
本文将该算法称作network slimming,该算法的输入是一个“宽大”的网络,在训练过程中,那些不重要的通道会随着训练权值逐渐降低,并通过后处理算法进行通道裁剪,最终得到一个没有精度损失的“瘦小”的网络。
本文在主流的CNN网络结构上验证了该方法,包括VGGNet, ResNet,DenseNet等,并在多个数据集上进行了验证。对于VGGNet, 在经过多次network slimming以后,该模型达到了20倍的模型尺寸压缩比以及5倍的模型计算量压缩比。
引言
近些年来,CNN在多种视觉任务中已经变成了一种主流的方法,比如图像分类,目标检测以及图像分割任务等。随着大规模数据集、高端gpu以及新型网络结构的出现,使得一些大模型的部署成为了可能。比如,imagenet比赛中的冠军模型从AlexNet、VGGNet以及GoogLeNet再到ResNet,模型规模逐渐从8层演变成100层以上。
虽然这些大模型具备较强的表达能力,但是这些模型对计算资源的需求也更苛刻。例如像ResNet-152这样的模型,由于需要大量的计算量,因此很难被部署在移动设备以及其他的IOT设备上。
上述提及的部署困难主要受限于如下的三个因素:
1.模型尺寸。CNN模型的强表达能力主要来源于他具有大量可学习的参数,而这些参数将和网络的结构信息一起被保存在存储介质上,当需要使用模型做inference时,再从硬盘上进行读取。举例来说,存储一个典型的在 ImageNet上训练好的模型需要大约300MB的空间,这对于嵌入式设备来说是一个非常大的开销。
2.运行时内存的消耗。在inference过程中,即使batchsize =1,中间层的计算需要消耗远大于模型参数量的内存空间。这对于一些高端的GPU可能不是什么问题,但是对于一些计算资源比较紧张的设备而言,这是一个比较大的部署问题。
3.计算量的大小。当把一款大型CNN模型部署于移动设备上时,由于计算量大同时移动设备计算性能弱,因此可能会消耗数分钟去处理一张图片,这对于一款模型被部署于真实应用中是一个比较大的问题。
当然,现在有很多工作提出可以通过压缩CNN模型来使得模型具备更快的inference性能,这些方法主要包括低秩分解、模型量化、模型二值化、参数剪枝等。然而上述所说的方法都只能解决之前所提到的三个主要问题中的一个或两个,同时,部分方法还需要软件或硬件的支持才能实现真正的加速。
另一个减少CNN计算资源消耗的方法就是网络稀疏化。稀疏化可被应用于不同的层级。本文提出了一种network slimming的网络稀疏化方法,该方法解决了在资源有限的场景下上述所提到的问题。
本文的方法中,主要通过对BatchNorm layer中的scale参数应用了L1正则项,从而非常方便的在当前的框架下实现了通道稀疏化。在该方法中,L1正则项将会使得不重要的通道的BatchNorm Layer中的scale参数推向0附近,通过这样的方法,算法筛选出了不重要的通道,为后续的通道剪枝带来了很多的便利。
与此同时,在该算法中引入的L1正则项并没有带来精度的损失,相反,在一些案例中,反而得到了更高的精度。在做通道剪枝的过程中,裁剪掉一些不重要的通道(即低权值的通道)可能会带来一些精度的损失,但是这些损失的精度可以通过后续的fine-tuning操作补偿回来。剪枝得到的压缩版网络在模型尺寸、运行时内存占用以及计算量方面与初始的网络相比更具竞争力。上述所说的过程可以被重复数次,在进行多道裁剪工序后将会得到压缩比越来越高的网络模型。
根据本文在多个数据集上的实验结果可以验证本文的网络在经过slimming操作后,实现了20倍的模型尺寸压缩以及5倍的模型计算量压缩,而在精度方面没有损失,甚至反而比原始模型更高。此外,由于本文的算法并没有对网络进行参数存储方式对修改,因此该方法可适用于在常规的硬件平台以及软件包上实现网络压缩以及inference加速。
Network Slimming
本文的目标是提供一个简单的策略在CNN上实现通道稀疏。在本章节将对channel-level稀疏的优势以及难点做一些分析,并且介绍了本文如何通过BatchNormLayer的scale参数来实现通道稀疏化。
(1)channel-level 稀疏化的优势
网络稀疏化可以被应用于不同的层级中,主要可分为weigh-level、kernel-level、channel-level或者layer-level。weight-level的稀疏化通常具备高度的灵活性以及通用性,并带来了较大的压缩比,但是该方案通常需要特殊的软硬件加速的支持才能实现最终的加速。
与此相反,layer-level的方案不需要特殊软硬件加速的支持即可实现最终的加速,但是这种方案相比weight-level不够灵活,部分层需要被整个裁剪掉,同时,该方案只会在网络层数特别深的前提下才会显得比较有效。因此,根据上述的对比,channel-level的稀疏化在灵活性以及实现难度方面达到了一个较好的平衡,该方案可被用于各种典型的CNN模型中,为每一个原始模型生成一个“瘦身”版的网络模型,该模型可以在各个常规的CNN平台上高效的运行。
(2)channel-level稀疏化的挑战
要实现channel-level的稀疏化需要裁剪掉所有与被裁剪通道相关的输入通道以及输出通道。直接用算法根据通道权值去裁剪一个预训练模型的通道会比较低效,因为不是所有的通道权值都会分布在0附近。如论文[23]所阐述的,直接在预训练好的ResNet中裁剪时,在精度不损失的前提下,只能裁剪掉~10%的通道。论文[35]通过引入了强制的稀疏正则项来实现通道权值的稀疏化,令通道的权值分布在0附近。本文提出了一种新方法来解决上述问题。
本文的方法就是为每一个通道引入一个scale 因子,该因子将对该通道的输出做乘积运算,从而实现对通道重要程度的建模,本文对模型参数以及scale因子进行联合训练,最后把那些scale因子小的通道裁剪掉并fine-tune整个网络。在引入了正则项以后,优化的目标函数如下式所示:
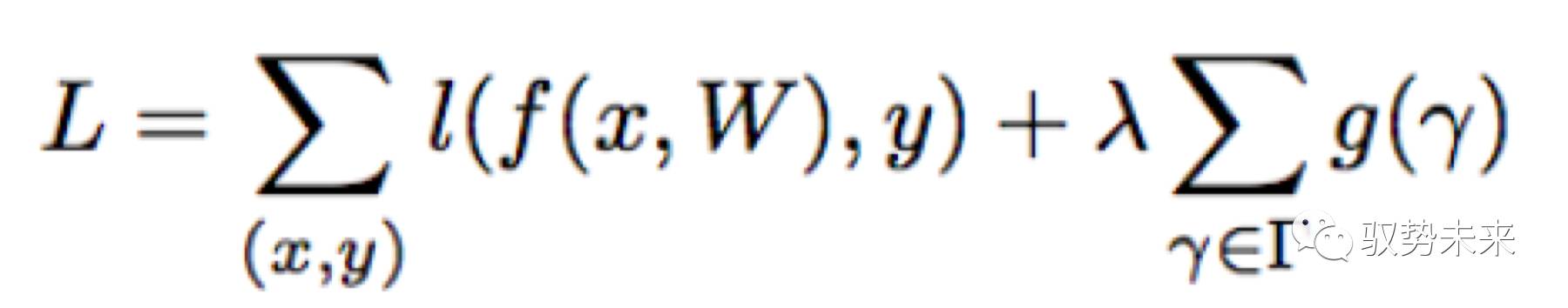
上式中,(x,y)表示训练的输入项与目标项,W表示可训练的参数,第一项表示CNN常规的训练损失, g(.)是一个引入在scale因子γ上的惩罚项,入表示第一项与第二项之间的权重比。在本文在实现中采用了g(s)=|s|,即L1正则项,被广泛应用于实现网络稀疏化,同时采用了subgradient descent的优化方法来优化L1正则项。
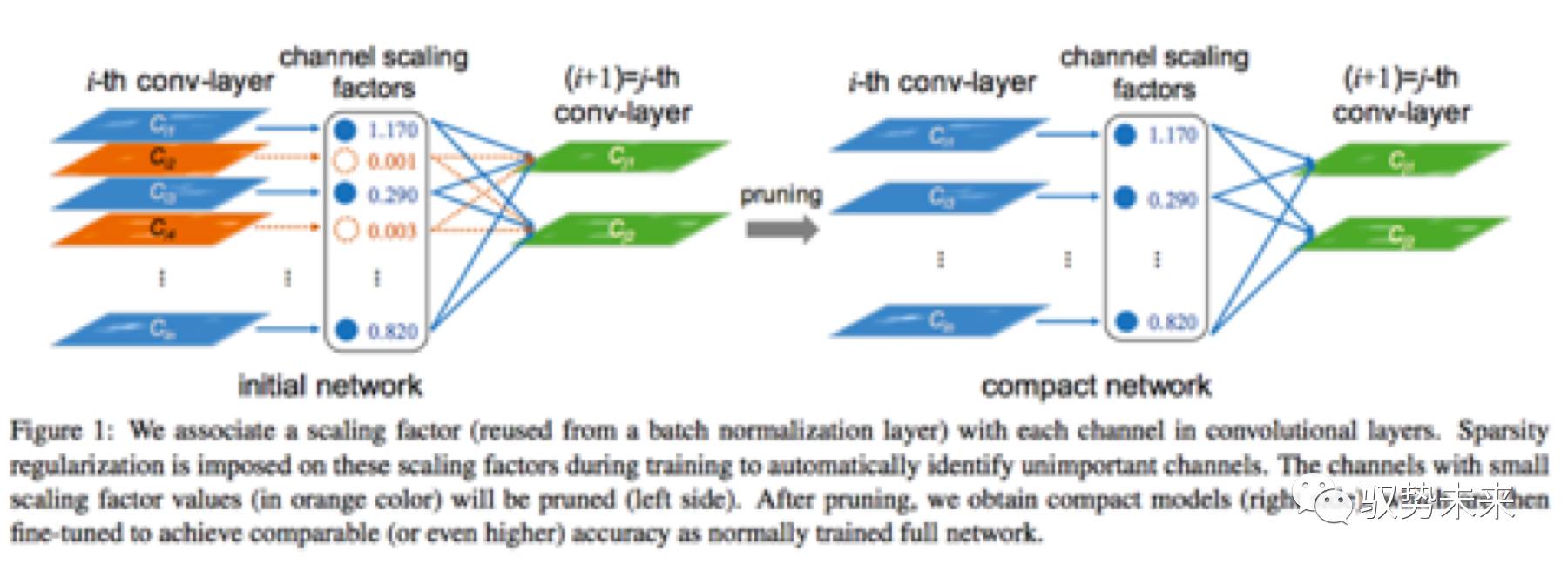
如上图Figure 1所示,当需要裁剪一个通道时仅需要移除该通道的输入与输出的连接即可得到一个压缩后的模型而不需要做其他的一些特殊操作。同时,由于在训练过程中,scale因子实现了对通道的重要程度的建模,因此,当后续做剪枝时,仅需要直接移除那些不重要的通道即可而不会影响模型整体的泛化能力。
(1)利用BatchNorm Layer进行channel-wise的稀疏化
BatchNorm 层已经被广泛的应用于各种CNN结构中,作为一种标准的方法来实现快速收敛以及增强泛化能力。BatchNorm Layer的设计思路启发了作者去设计一种简单有效的方法来实现channel-wise稀疏化。BatchNorm Layer的计算定义如下:
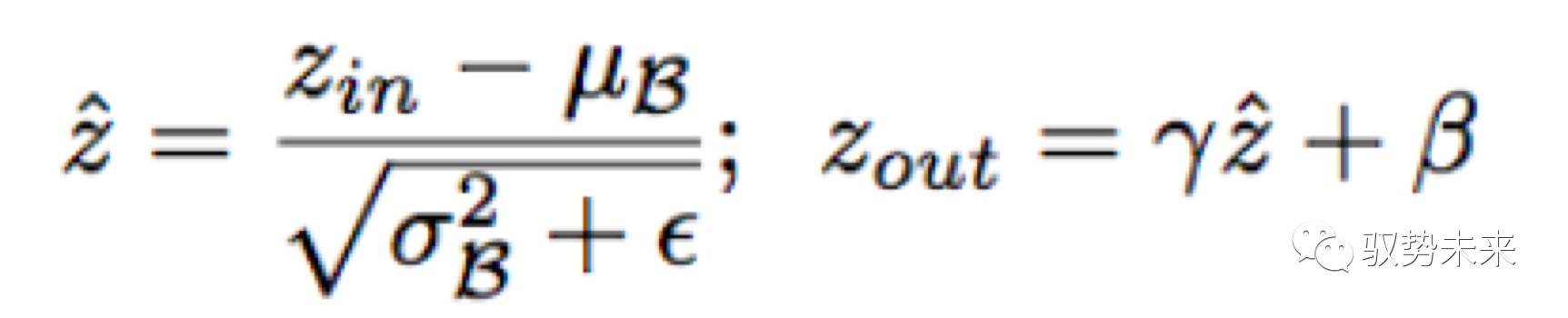
其中zin与zout分别代表Batchnorm Layer 的输入和输出,与分别表示当前mini-batch下面的均值与方差,而与是可学习的参数,可以将规范化后的分布返回到任何一种原始尺度下。
将BN层放置在Convolution层的后面是一种非常通用的方法。因此,可以直接利用BN层中的γ参数来建模通道的重要性,通过这样的设计,不需要引入额外的实现就能达到算法的设计目标,事实上,这是可以用来实现channel-wise稀疏化的最有效也是最快捷的方法。接下来讨论一下ScaleLayer的放置问题。
1.假如只是在Convolution后面增加了scale层而没有使用Batchnorm Layer,Scale层学到的参数对于评估通道的重要性没有意义,因为,Convolutionlayer和Scale layer都是线性变换,可以通过减少Scale因子的值同时放大Convolution Layer的参数值来达到同样的目标。
2.假如将Scale Layer放置在BatchnormLayer前,Scale Layer的效果会被BatchnormLayer 的规范化效果完全抵消掉。
3.将ScaleLayer 插入在Batchnorm Layer 之后时,就可以为每一个通道提供两个scale参数进行通道建模了。
(2)通道剪枝以及Finetune
在引入L1正则项进行网络稀疏化训练以后就可以得到一个多数通道权值在0附近的模型。之后对网络这些权值在0附近的通道进行裁剪,将这些通道对应的输入输出的连接移除。在裁剪过程中,本文采用了一个全局裁剪阈值,比如,当需要裁剪70%的通道时,本文会选取一个裁剪百分位为70%的阈值。通过这样的操作即可得到裁剪后的模型。
经过上述的裁剪操作后,如果采用的裁剪比例较高可能会带来部分精度的损失,但是这部分损失可以通过后续的Finetune操作补偿回来。在作者的实践过程中发现,在进行Finetune操作后,裁剪后的模型往往会比原始的未裁剪的网络精度高。
(3)多次循环剪枝
本文的方法可以从单步操作推广到多步操作。操作流程如下图所示:
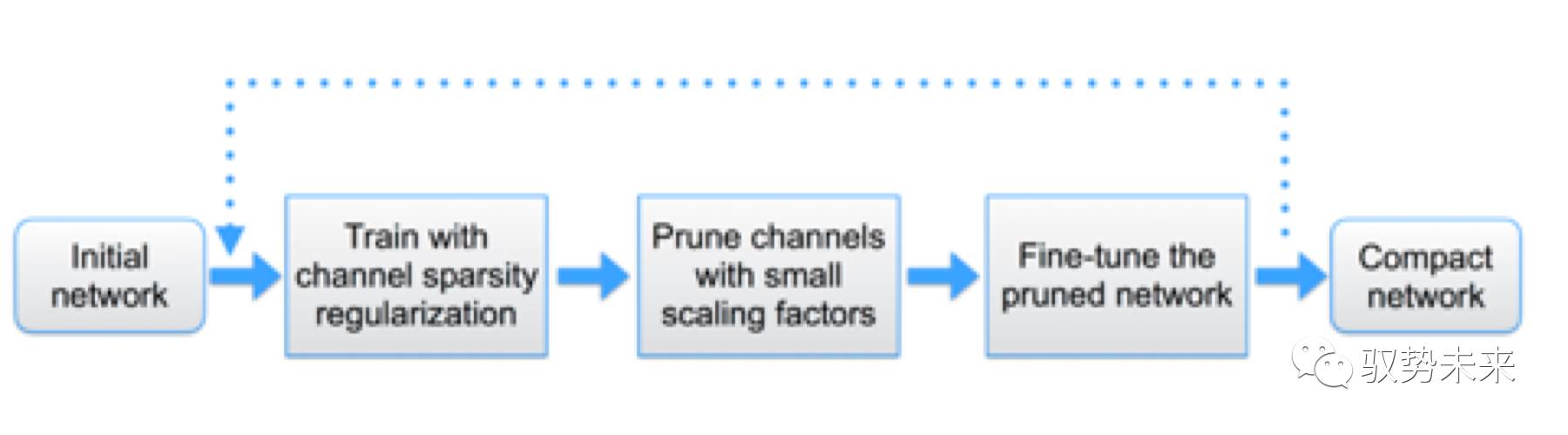
根据本文的实践经验发现multi-pass得到的结果往往会得到更高的压缩比。
(4)对Cross Layer Connections 以及 Pre-activation 结构剪枝.
network slimming的方法可以被直接应用于VGGNet、AlexNet这样的网络结构,但是当需要把该方法应用于ResNet、DenseNet这样的网络结构时需要做其他的一些特殊设计。对于这样的网络,前一个网络的输出往往会被作为后面多个网络模块的输入,这些网络中 BN层的放置将被放置在Convolution层前。在这样的网络结构中,为了在inference时实现网络参数以及网络计算量的压缩,需要在不重要的通道前放置一个channel-selection-layer来屏蔽不需要的channel。
结果分析
在Cifar10、Cifar100、SVHN上,本文采用了三种模型结构进行了测试分析。分别为VGGNet、ResNet164、DenseNet-40。在ImageNet数据集上,本文采用了VGGNet-A网络进行了测试分析。下图table 1为在Cifar数据集以及SVHN数据集上进行验证的一些结果。
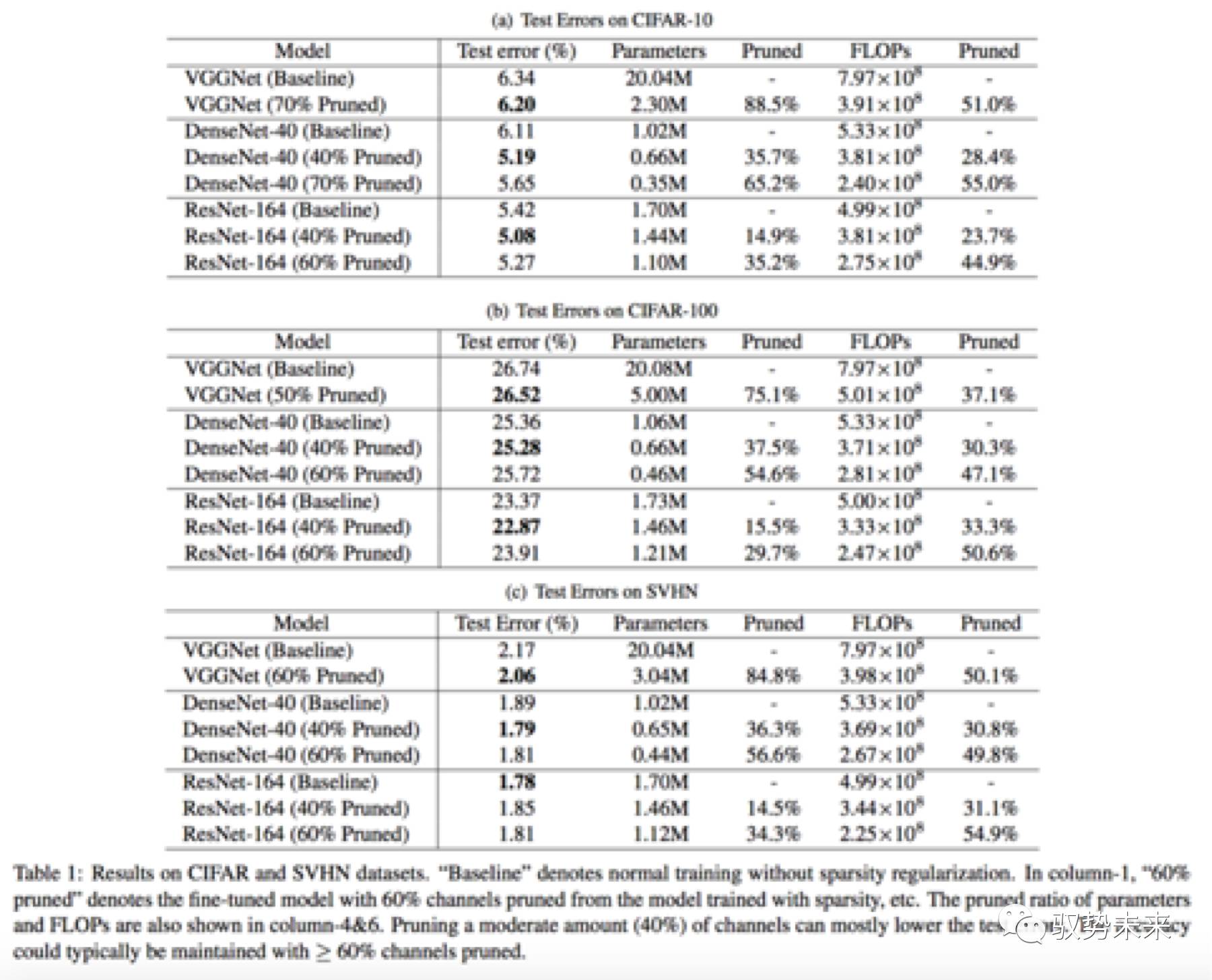
如上表table1所示,分别在Cifar10、Cifar100以及SVHN三个数据集进行了训练测试,可以看到在这三个数据集中,每一个模型在进行了60%以上的channel-pruning以后,均能保持与原始模型几乎一致的结果,甚至部分模型裁剪后的结果还有提升。
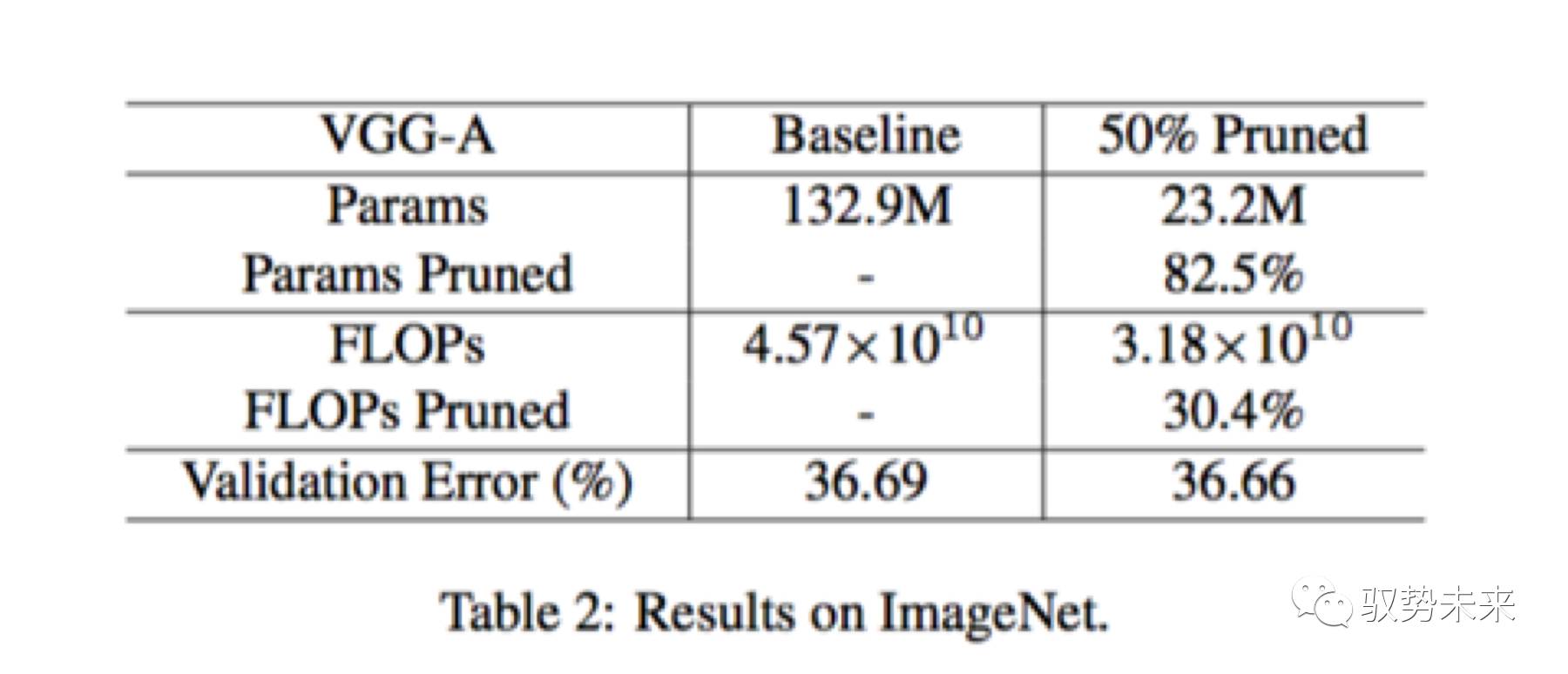
如下图table2所示为VGGNet-A网络在ImageNet上训练测试的一个结果表。当采用了50%的通道裁剪以后,参数裁剪比例超过了5倍,但是Flops裁剪比例仅为30.4%,这是因为在卷积层中只有378个通道被裁剪掉了,而在全连接层中,有5094个通道被裁剪掉。
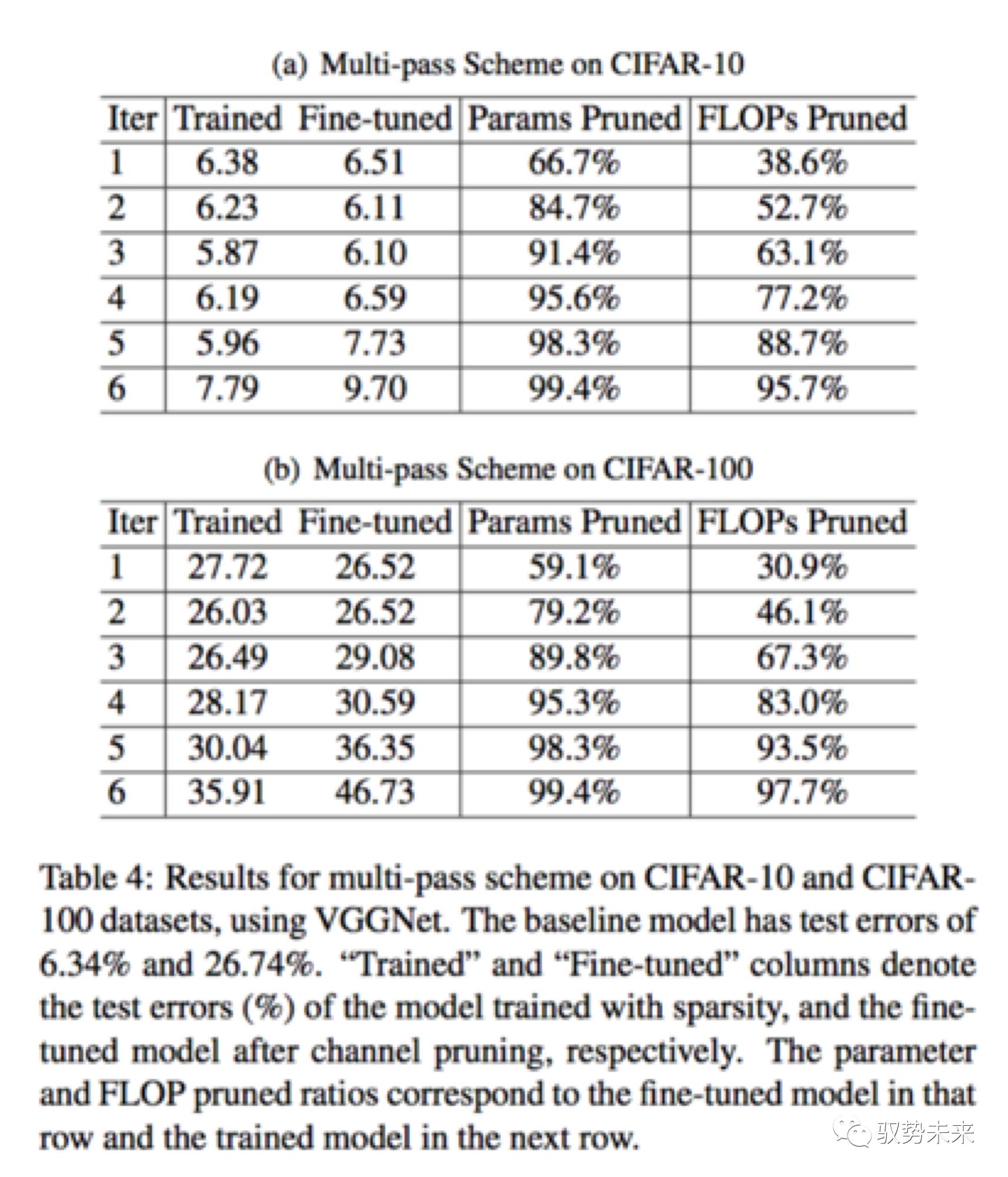
如下表table4, 展示了在VGGNet在Cifar10以及Cifar100上进行multi-pass裁剪的一个对比结果。如在Cifar10数据集上,随着迭代次数的提升,裁剪比例越来越高,在iter 5的时候,得到了最低的test error。此时该模型达到了20x的参数减少和5x的计算量减少。而在Cifar100上,在iter3上,test error开始增加。这可能是因为在cifar100上,类别数目大于Cifar10,所以裁剪的太厉害会影响最终的结果,但是仍然实现了接近90%的参数减少以及接近70%的计算量下降。
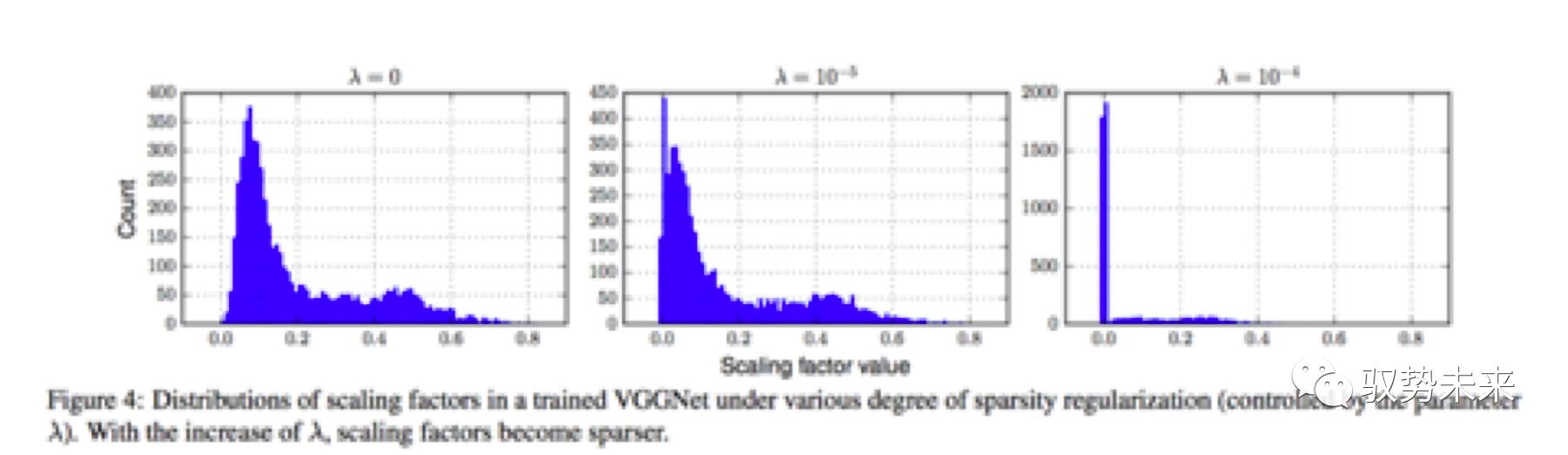
如下图Figure 4为本文采用VGGNet在Cifar100上作稀疏化训练一些对比实验,可以发现随着入的增大,模型通道权重的结果会越来越稀疏。
我们的一些实践
由于公布的代码是在torch框架下的代码,因此,我们根据在Caffe上对上述结果进行了一次简单的验证。在验证过程中采用了VGGNet-A网络作为实验网络,并采用的Cifar10作为训练数据集。
如下图所示,左上为入=0,在iteration = 10000时的入参数分布图,右上为入=0,iteration=45000的参数分布图。左下为入=10e-4,iteration = 45000的参数统计图,右下为入=10-3, iteration = 45000下的参数统计图。[横轴值除以100为参数实际区间]
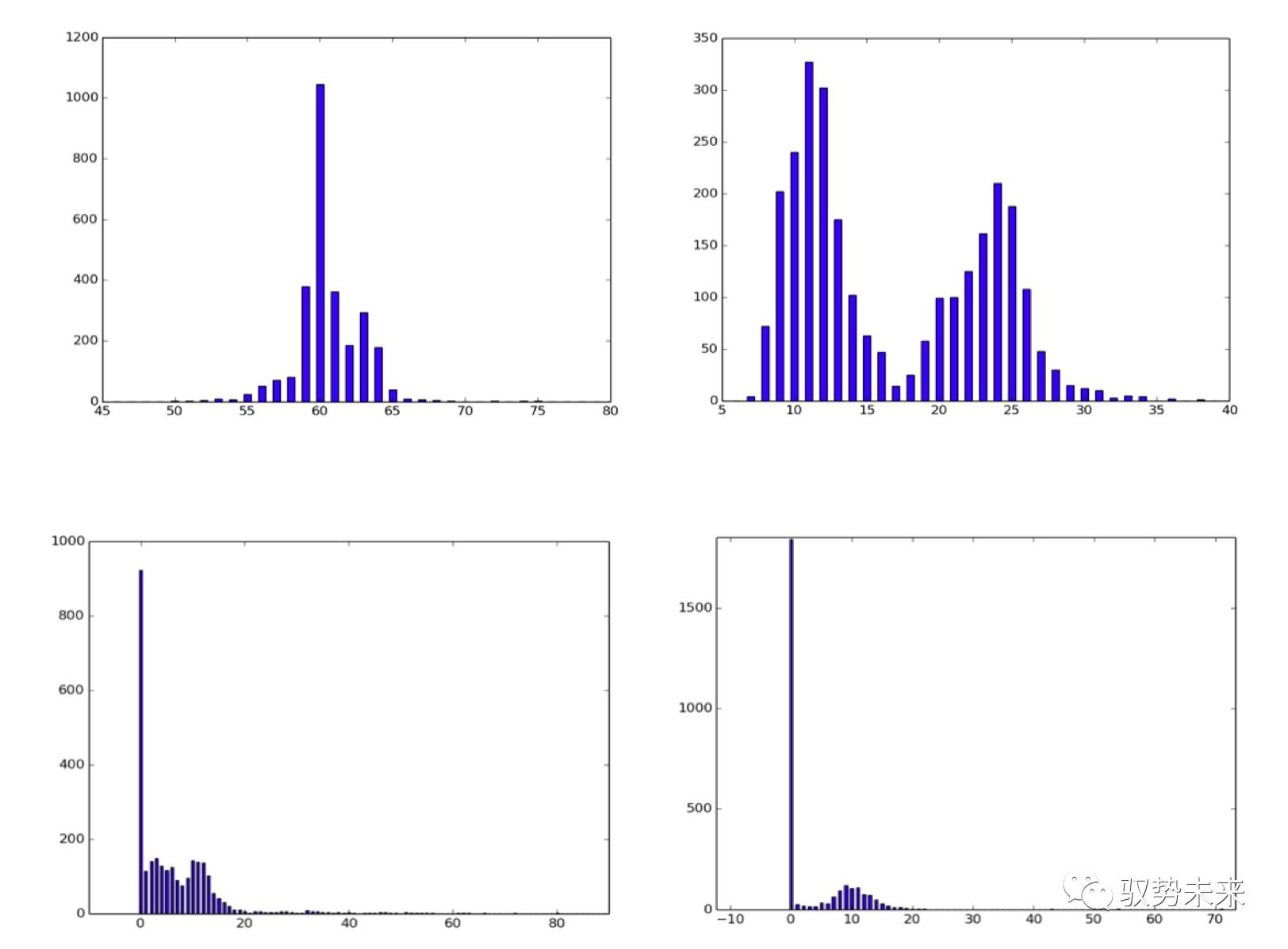
根据上面这一组图我们发现如下几点得到了验证。
(1)随着训练次数的增加,入参数在正则项的影响下,逐步左移,重要的通道权值逐步凸显,不重要的通道权值逐步抑制,与论文中Figure6的结论相符
(2)随着入参数的增大,L1正则项的影响越来越大,参数越来越向0点靠拢,稀疏比例提高
(3)在增加L1正则项以后,实现了对通道的稀疏化但训练的结果并没有下降甚至反而有所提升,考虑在训练过程中,“噪声”通道由于L1正则项的引入被抑制,而真正的有效通道被凸显。
因此,我们认为slimming的方法对于channel-wise的稀疏化是有效的。我们也采用同样的参数在ImageNet数据集上进行了实验,实验发现效果并不如在cifar10数据集上那么好,虽然也有参数稀疏化的效果但是并不如cifar10上那么明显,同时参数稀疏化后大部分主要分布在0.2附近,后续我们将进一步进行试验。
总而言之,channel-slimming利用了BatchNorm Layer的特性巧妙的对通道重要性建模并最后实现通道的稀疏化还是非常值得学习的。
-
大模型推理显存和计算量估计方法研究2025-07-03 883
-
脉冲信号分析仪的原理和应用场景2025-01-23 1585
-
混合信号分析仪的原理和应用场景2025-01-21 541
-
USB协议分析仪的技术原理和应用场景2024-09-24 4185
-
NanoEdge AI的技术原理、应用场景及优势2024-03-12 1684
-
基于多媒体社会事件的分析研究综述2021-04-08 1654
-
小容量OLT应用场景分析2020-12-03 4271
-
大数据开发之spark应用场景2018-04-10 2696
-
MMC控制策略比较分析研究2017-01-07 786
-
matlab关于城市空气污染数据的真实性判别及分析研究2016-08-15 4180
-
耦合电感式的Boost电路分析研究2010-05-11 1072
-
基于资源空间模型的虚拟场景技术研究2010-03-01 578
-
受限领域问答系统的中文问句分析研究2009-04-22 710
-
轿车参数化分析模型的构造研究及应用2009-04-16 3136
全部0条评论

快来发表一下你的评论吧 !
