

使用智能传感器的内置机器学习内核可以优化“始终开启”运动跟踪。
电子说
描述
消费者对于健身跟踪器和其他个人移动设备具备“始终开启”运动跟踪功能的需求不断增长,在过去,这意味着设计人员需要在这些功能与电池寿命之间做出取舍。若是尝试降低功耗,势必会牺牲跟踪功能或分辨率,因而会使用户的体验受到影响。
不过,随着内置运动检测功能的低功耗传感器的出现,将有助于开发人员消除这一设计局限性。
本文将介绍并展示如何使用 STMicroelectronics 推出的智能运动传感器,该传感器集成了精密的运动处理功能,能提供更有效的解决方案来实现低功耗、始终开启的运动跟踪。
传统的电源管理实践
在典型的低功耗移动系统设计中,主机微控制器在正常有源模式下所用功耗占系统总功耗的绝大部分。因此,开发人员会寻找一切机会让微控制器在低功耗休眠模式下运行,并将处理器的唤醒时间控制在仅仅足够让处理器完成传感器数据处理或通信等任务的程度内。
多年来,开发人员一直通过使用可独立收集主机处理器数据的传感器实现这一目标。在对传感器输出数据速率要求不高的应用中,传感器可能会将一系列测量数据填入片载缓冲区,甚至执行直接存储器访问 (DMA) 事务以将数据传输到系统内存中,然后再发出中断信号唤醒处理器以使其完成处理任务。由于传感器的集成式信号链可以执行信号调节、转换和滤波,因此处理器可以立即开始处理经过预处理的数据,并寻找对于应用意义重大的事件。
在这些传感器中集成了阈值检测功能之后,开发人员可以进一步延长处理器持续处于低功耗模式的时间。传感器不需要处理器识别重要事件,传感器仅在测得超出开发人员所设定阈值的事件时发出唤醒信号。例如,设计人员可以对这种高级温度传感器进行编程,让它只在测得的温度超过指定的最大阈值或低于指定的最小阈值时发出唤醒信号。
这种降低功耗的方法对于比较简单的需求虽然有效,但用来检测更为复杂的事件时,它的效果却要大打折扣。再加上对始终开启感测的要求,检测这些复杂事件意味着处理器的有效占空比变得更高,这样会导致个人可穿戴设备中常用的容量相对较小的充电电池电量很快耗尽。因此,随着用户对始终开启检测和更长电池续航时间的需求越来越高,以往使用主机微控制器执行检测的这一做法变得难以为继。
如果传感器能够执行更复杂的检测算法,那么开发人员就可以沿用目前的最佳实践,通过低功耗工作模式和处理器休眠状态来降低系统功耗。与此同时,这种更加智能的传感器还需要为开发人员提供高度灵活性。仅仅将几种特定的算法硬写到传感器中并不能满足人们对于更新颖、更出色产品特性的需求。STMicroelectronics 的 LSM6DSOX iNEMO (LSM6DSOXTR) 惯性传感器可提供这一灵活性,还有内置在该器件内的多种信号处理功能和灵活计算能力。
传感器架构
LSM6DSOX iNEMO 是一个系统级封装 (SiP),在一个接点栅格阵列 (LGA) 封装中整合了微机电系统 (MEMS) 传感器、专用的信号链、滤波器和专用的计算引擎,体积仅为 2.5 x 3.0 x 0.83 mm。该器件还具有内置的三轴加速计和三轴数字陀螺仪 MEMS 传感器,因此可以将其配置为一个传感器中枢,用来通过专用的中枢寄存器单独安排最多四个外部传感器的运行。
LSM6DSOX 采用与以前的 STMicroelectronics LSM6DSO 相同的架构,可提供早期器件的所有功能和特性(请参阅“IMU:通过板载机器学习让主机休眠”)。不过,LSM6DSOX 让 STMicroelectronics 在早期的器件中提供的有限状态机 (FSM) 具备了机器学习 (ML) 内核,可通过最多 8 个决策树对数据集进行分类。即使不激活 FSM 和 ML 内核能力,开发人员也可以实现高级运动检测能力,这要归功于用于预处理 MEMS 传感器数据的高级信号链。发烧友公众号回复资料可以免费获取电子资料一份记得留邮箱地址。
与很多高级传感器一样,LSM6DSOX 架构也具有多级信号链,可以将模数转换器 (ADC) 与多个滤波级组合在一起。陀螺仪信号链将 ADC 级与一系列可选择的数字滤波器(包括高通滤波器 (HPF)、低通滤波器 (LPF1) 和第二个低通滤波器 (LPF2))配合使用,这些数字滤波器在器件的高性能模式下运行,但在正常模式或低功耗模式下会被绕过(图 1)。
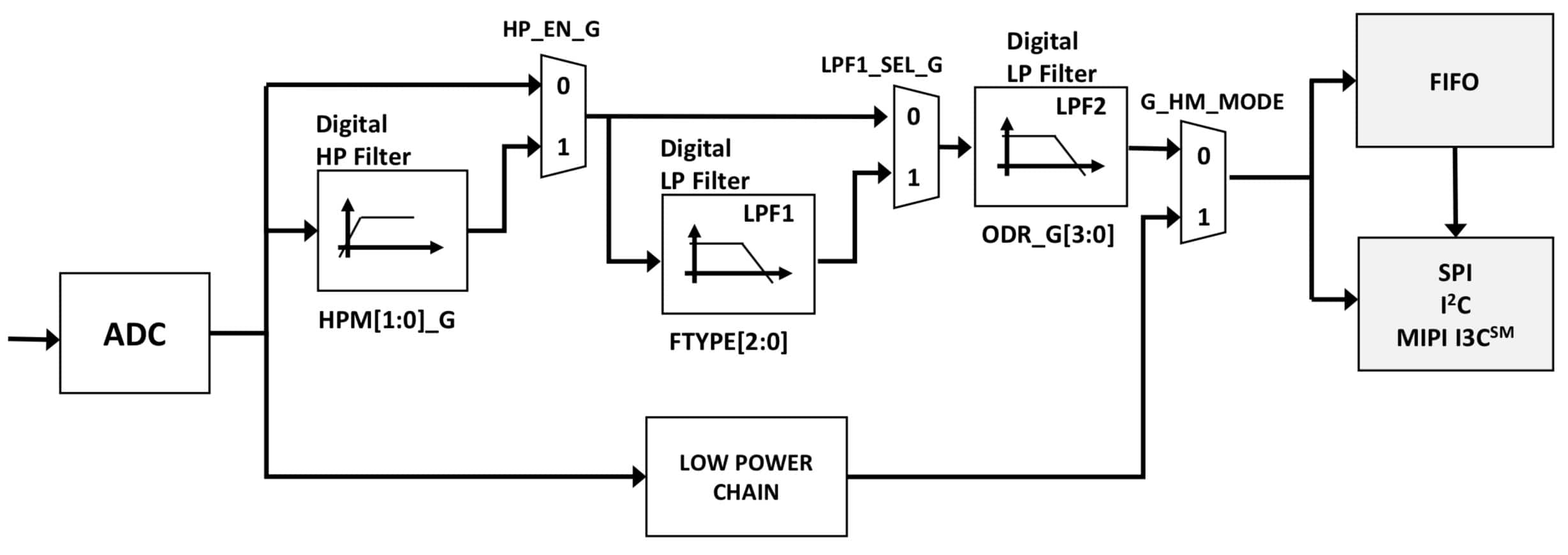
图 1:与以前的 STMicroelectronics LSM6DSO 一样,STMicroelectronics LSM6DSOX 也使用具有多个滤波器级的专业、专用信号链来跟踪每个传感器,此处所示为陀螺仪传感器。(图片来源:STMicroelectronics)
由于很多集成式功能都需要加速计,因此在这种架构中显著增强了加速计信号链。它的初始级提供了大多数高级传感器都具备的基本信号调节和转换能力。例如,模拟抗混叠低通滤波器提供了基本信号调节能力,一个 16 位 ADC 会对调节信号进行数字化处理,并通过数字低通滤波器传输数字化的结果。该器件与其他器件的不同之处在于,它采用精密的复合滤波器块来跟踪此初始转换级(图 2)。
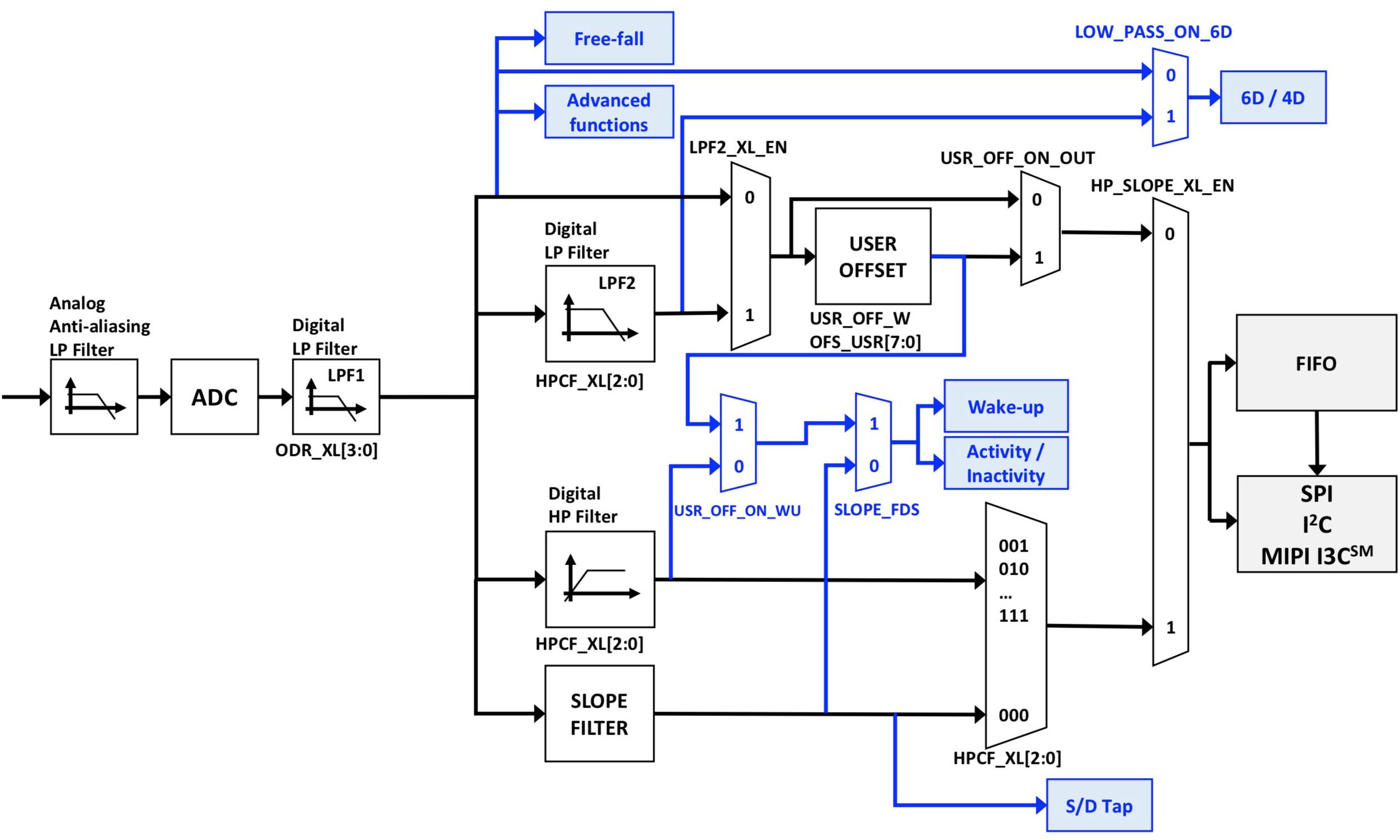
图 2:以前的 STMicroelectronics LSM6DSO 和现在的 STMicroelectronics LSM6DSOX 运动传感器都采用全面的加速计信号链,以便能够独立于主机检测多种复杂运动,包括自由落体、多维定向和单/双 (S/D) 抽头。(图片来源:STMicroelectronics)
通过将处理块与滤波器配合使用,加速计的复合滤波器部分能够自主检测多种迄今仍然要用处理器来唤醒和运行专用事件检测代码的那些复杂事件。而现在,开发人员可以对滤波器参数进行编程,以自动检测多种复杂运动事件并发出中断信号,这些事件包括单抽头或双抽头、自由落体、活动/非活动、六自由度 (6D) 方向或者通常用来检测器件运动的 4D 方向。例如,从纵向到横向模式。
复合滤波器的高级检测器综合了来自处理块和滤波器的结果来执行检测。例如,单抽头检测功能采用内置的斜率滤波器,此滤波器会为当前的加速计样本 acc(tn) 连续生成斜率,如下所示:
slope(tn) = [ acc(tn) - acc(tn-1) ] / 2 (等式 1)
对于单抽头事件,相比更宽的冲击事件,斜率会升至某个阈值以上,然后快速回落(图 3)。使用开发人员设置的抽头阈值和冲击窗口持续时间值,器件可以自动检测单抽头事件,并向主机微控制器发出中断信号。
双抽头检测功能在这种方法的基础上增加了另一个参数,以指定两个单抽头事件之间所需的等待时间。

图 3:LSM6DSO 和 LSM6DSOX 运动传感器利用内置的斜率函数执行独立于主机的单抽头事件检测。此斜率函数表明,与宽冲击事件 (b) 的特征相比,单抽头 (a) 更快地回到基线水平。(图片来源:STMicroelectronics)
该器件能够生成衍生数据(例如斜率),因此在集成式 FSM 和机器学习 (ML) 内核的更高级功能中发挥着核心作用。由于前面提到的文章中已经讨论了 FSM 功能,因此本文的其余部分将侧重于 LSM6DSOX 的 ML 内核及其如何检测复杂得多的运动事件,包括运动序列甚至复杂的健身活动,例如特定的锻炼。
决策树
LSM6DSOX 的 ML 内核提供了基于传感器的处理,且其处理能力远远超过很多高级智能传感器中常用的参数化阈值设置。使用 ML 内核,开发人员可以在该器件中实施复杂的检测算法,以便在无需唤醒微控制器的情况下始终开启复杂运动事件检测。为此,ML 内核利用决策树,基于输入数据的模式来识别事件。
决策树已经在决策支持系统中使用多年,其会对照预定义的条件测试输入数据或属性,以便将复杂的决策分解成一系列选择。从初始节点或根开始,对属性的值进行测试,并根据结果确定是否继续前往特定的子节点(图 4)。
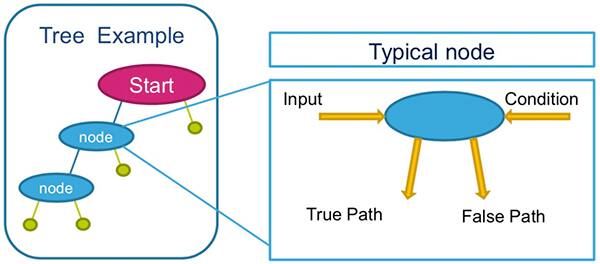
图 4:决策树会利用一系列节点生成结果,每个节点都会对照某个条件(例如特定的阈值水平)测试某个输入值的特定属性,然后根据测试结果继续前往不同的子节点。(图片来源:STMicroelectronics)
例如,在每个更新周期都会调用决策树,以使决策树通过它的节点确定可用于此更新的数据表示无运动、向前运动还是某种其他的运动,如下所示:
-
测试加速计测量幅度
- 1.1.如果值低于某个预定值(条件),则终止
-
1.2.否则,前往某个分支的子节点,以测试在同一个时间窗口中取得的陀螺仪测量结果
- 1.2.1.如果陀螺仪测量结果低于某个预定值,则终止,或者
- 1.2.2.继续前往更深的子节点,以测试在同一个时间窗口中测得的其他属性,或者对照另一个条件测试同一个属性。
重复此过程,直到测试达到终端节点,在这种情况下对应于一个特定的复杂运动事件或类。在这个简单的示例中:
- 终端节点 1.1 可能表示应将数据或特性集归类为“无运动”
- 终端节点 1.2.1 可能表示应将特性集归类为“向前运动”
- 节点 1.2.2 下面的终端节点可能表示运动转向或者更复杂的方向变化
当然,要用到决策树的现实世界问题要复杂得多,需要采用大量包含许多不同属性和条件的特性集。事实上,LSM6DSOX 为开发人员提供了丰富的可用特性,以使他们能够开始处理来自加速计、陀螺仪以及在传感器中枢连接模式下安装的任何外部传感器的相关数据(图 5)。

图 5:STMicroelectronics 的 LSM6DSOX 独特内置 ML 内核使用主要传感器数据、经过滤波的数据和衍生的参数(例如均值和方差),并将它们输入到该器件所支持的 8 个决策树之一。(图片来源:STMicroelectronics)
根据这些主要传感器数据,该器件会生成大量的特性,这些特性是根据滑动时间窗口内的主要数据计算得出,包括:
- 范数 V = Ö( x2 + y2 + z2) 和 V2
- 均值
- 方差
- 能量
- 峰峰值
- 零交叉点
- 正零交叉点
- 负零交叉点
- 峰值检测器
- 正峰值检测器
- 负峰值检测器
- 最小值
- 最大值
对于特定特性,例如零交叉点检测器和峰值检测器,开发人员还可以指定一个阈值,分别用于改变零交叉点轴或峰值阈值。
受监督的学习工作流
利用这些特性对 LSM6DSOX 的 ML 内核实施决策树时,需要遵循一个大多数机器学习模型开发工作都会用到的典型受监督学习工作流。一般而言,此工作流会首先识别相关的活动,并收集与这些活动相关的数据样本。
在这种情况下,开发人员只需使用 LSM6DSOX 来收集数据,并执行最终应用需要检测的一组特定运动活动。对于这一开发阶段,开发人员可以利用 STMicroelectronics 提供的板和软件构建一个数据采集平台。对于硬件平台,开发人员只需将 STEVAL-MKI197V1 的 LSM6DSOX 适配器板插入到 STEVAL-MKI109V3 评估主板中。对于软件,开发人员可以使用 STMicroelectronics 免费提供的 Unico 软件工具,此工具具有 Windows、Mac OSX 和 Linux 版本。
Unico 需要与 STEVAL-MKI109V3 主板配合使用,它利用一种简单的方法来收集 LSM6DSOX 生成的数据。要收集数据,开发人员可以将此主板与 Unico 配合使用。为此,开发人员或助理需要紧紧握住主板,并反复执行其中一种特定的相关运动活动,同时利用 Unico 来收集 LSM6DSOX 运动数据。
在多次反复执行同一个活动期间从 LSM6DSOX 收集的数据可以为相应的类(例如上一个示例中的“向前运动”)提供训练集。由于在此运动期间收集的数据都对应于同一个类,因此这种主动收集数据的方法不需要单独的数据标记阶段,此阶段有时会拖慢受监督的学习工作流。
在收集每个相关运动事件类的运动数据之后,开发人员需要使用 Unico 来查看数据和类标签。Unico 除了用于查看数据以外,还允许开发人员配置所需决策树的多个方面、定义滤波器、设置时间窗口持续时间以及选择要在构建决策树时使用的特定特性。
在实践中,开发人员通常会根据经验和试验尽可能减少用于检测特定一组活动的特性。即使只有极少的特性集,能否高效地实施决策树这一任务也主要取决于:确定要在决策树的各个节点测试那些特性或属性中的哪一些。选择要在每个节点测试的“最佳”属性对于尽可能减少决策树的大小非常重要,而决策树的大小对于资源有限的器件(例如传感器)尤其重要。
读者须知:到目前为止,您可能对特性 (feature) 与属性 (attribute) 的使用感到疑惑。难点在于,对于 ML 模型,我们探讨的是“特性”,但谈及决策树时,这些特性被称为“属性”。我们曾尝试在某一部分内容中只使用其中一个术语,但在这里,我们会在随后的决策树讨论中从“特性”改为“属性”。毫无疑问,您会注意到在其他地方,这两个术语会互换使用,不过在这里以及随后的“arff”部分,我们将使用“属性”。
尽管概念简单,但在每个决策节点选择要使用的最佳属性却并不直观,因为决策树具有大量属性,其中每个属性都由各种数据值表示。要确定要在每个节点测试的最佳属性,首选方法是利用下面的等式 2 计算每个属性在此节点的香农熵:
entropy(p1,p2,...,pn) = - p1log2(p1) - p2log2(p2)...- pnlog2(pn)(等式 2)
概率 pn 表示每一个与此属性相关的 n 个可能类。
结果是信息内容,显示为 0 到 1 之间的位值,而不仅仅是人们更熟悉的数位定义中的 0 或 1。
随后,每个属性的信息“增益”会成为此信息值与基线信息值之间的差异,而基线值是根据在不使用决策节点的情况下做出正确决策的概率,并针对属性计算得出。尽管本文无法就这一计算进行详细探讨,但要直观地解读这一计算,需要比较哪种方法更有可能更高效地取得所需的结果:是根据此属性的值(“基线”)对数据集进行强力自下向上分割来取得结果,还是根据此属性的特定值范围进行自上向下选择来取得结果。自上向下选择采用“各个击破”方法,这种方法通常能够比自下向上方法更快地减少可能的结果数量。
快速部署
幸运的是,开发人员几乎不需要亲自考虑信息增益详细信息以及如何优化属性的选择。相反,他们可以利用免费的第三方机器学习工具(例如 Weka)来自动执行必要的计算,以生成最佳决策树。
事实上,Unico 和 Weka 可以密切协同工作,以提供一个用于快速实施决策树的工作流。特定决策树开发工作流中的关键步骤通常是前面提到的数据收集步骤,具体而言是指利用 LSM6DSOX 来为每个相关的活动类收集具有代表性的数据集,然后利用 Unico 来细化这些数据集并定义决策树配置。完成后,这两个工具会相互结合来加速执行此过程的最后阶段。
在 Unico 中细化了数据和决策树配置之后,开发人员可以使用此工具将所选的特性集转换为一种称为属性-关系文件格式 (arff) 的标准格式。arff 文件具有一个标题部分,其中会列出所选的属性(特性)和可能的类,还具有一个数据部分,其中会列出所收集的每一组数据和相关的类(列表 1)。在此示例中只使用了很少的几个特性,而且只使用了很小的一组数据实例来识别有限的一组类,包括二头肌弯曲训练、侧举和深蹲。

列表 1:标准属性-关系文件格式 (arff) 文件包括一个标题部分,其中定义了属性和类,还包括一个数据部分,其中包含每个属性的数据实例和相关的类。(数据来源:STMicroelectronics)
使用 Weka,开发人员可以在 Preprocess(预处理)窗口中加载 arff 文件并查看整个特性集的图形化概览(图 6)。
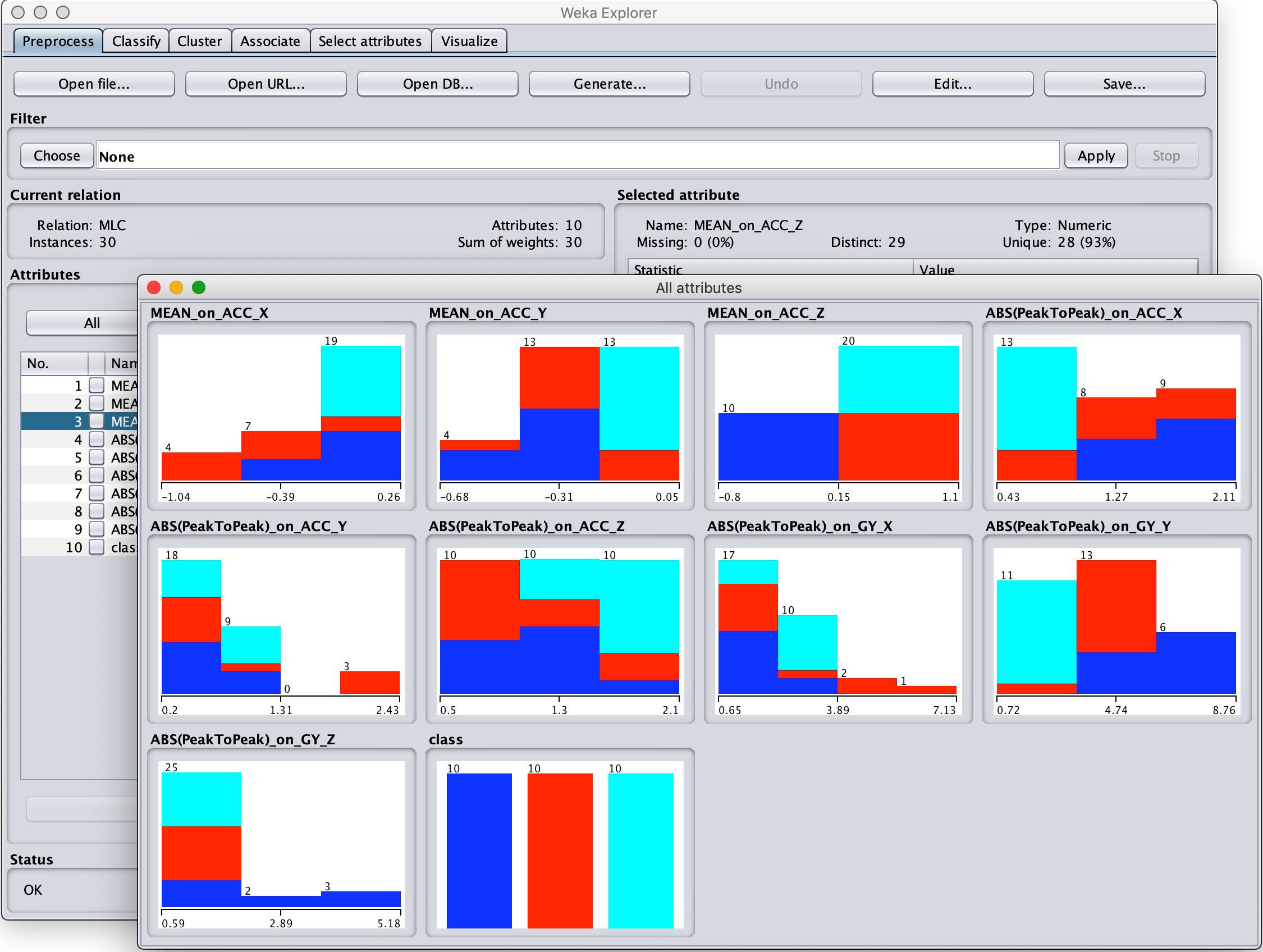
图 6:使用 STMicroelectronics 的 Unico 工具为自己的数据集生成一个 arff 文件之后,开发人员可以使用第三方机器学习工具 Weka 来查看整个数据集,这里显示了列表 1 中的 arff 数据的数据集。(图片来源:Digi-Key Electronics)
要构建决策树,开发人员需要切换到 Weka 的 Classify(分类)窗口并选择 Weka J48 分类器(Weka 的决策树分类器),然后单击 Start(开始)。在其输出窗口中,分类器会列出汇总的输入数据,并同时以图形格式(图 7)和文本格式(图 8)提供决策树。

图 7:要构建决策树,开发人员只需加载一个 arff 文件、选择 Weka J48 决策树分类器并生成最终的树。内置的 Weka 可视化工具用于查看结果,并列出了每个节点的属性和条件 - 在此示例中使用的是列表 1 中的 arff 数据。(图片来源:Digi-Key Electronics)

图 8:除了直观地显示决策树以外,Weka 还会生成实际 J48 决策树规格 - 在此示例中使用列表 1 中的 arff 数据来生成列表 2 中的 J48 规格。(图片来源:Digi-Key Electronics)
在此示例中,生成的 J48 决策树规格只需要几行代码(列表 2)。
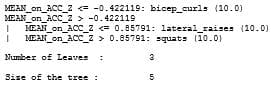
列表 2:Weka 会为列表 1 中的 arff 数据生成一个类似于此规格的 J48 决策树规格。开发人员将此规格加载到 STMicroelectronics 的 Unico 工具中,以生成一个配置文件,然后将其加载到 STMicroelectronics 的 LSM6DSOX 传感器中。(数据来源:STMicroelectronics)
复制 J48 树文本并将其保存到文件中之后,开发人员将此文本文件加载到 Unico 中,以生成一个寄存器配置文件。最后,开发人员使用 Unico 的 Load/Save(加载/保存)选项卡完成此工作流,以便将此配置文件加载到 LSM6DSOX 中。此时,开发人员可以持续使用上文所述的 STEVAL-MKI109V3 主板执行支持性的运动,并利用 Unico 从所配置决策树的 LSM6DSOX 输出寄存器中读取决策树分类结果。
在定制设计中,开发人员可以利用决策树输出寄存器中发生的变化向微控制器发送信号,将其唤醒并执行代码以通知用户、增大锻炼计数器或者酌情执行应用所需的其他高级操作。
尽管此示例极其简单,但 LSM6DSOX ML 内核可以利用更多的上述各种特性对复杂得多的运动事件进行分类。例如,STMicroelectronics 为这种简单的应用描述了一个更高级版本:使用更多的特性将健身房的活动分类为多种锻炼,包括二头肌弯曲训练、开合跳、侧举、俯卧撑和深蹲。
除了这个简单的示例中使用的均值和峰峰值特性以外,这个复杂的示例还增加了为一个两秒钟的时间窗口计算出的方差、最小值、最大值和零交叉点特性。在 LSM6DSOX ML 内核中运行的这个更先进的应用会消耗大约 569 μA 的电流(当电压为 1.8 V 时),其中只有 13 μA 的电流是 ML 内核本身所消耗的电流。如此低的功耗能够让开发人员放心大胆地执行始终开启的运动检测,而且只会对电池的充电状态产生轻微的影响。
机器学习注意事项
机器学习的实际应用取决于受监督的学习工作流,这些工作流会不可避免地导致最终机器学习模型出现某种形式的偏差,无论此模型是非常复杂的卷积神经网络还是相对比较简单的决策树。特别值得一提的是,基于运动的数据还在很大程度上取决于身体形态和运动机能,因此从开展活动的某一个人那里收集的数据可能明显不同于从另一个人那里收集的数据。
因此,使用基于 ML 的活动检测功能的开发人员面临着这样一个持续的挑战:在数据特异性与普遍性之间找到平衡点。过高的特异性通常会限制普遍性,而过高的普遍性通常无法精确地检测不同的个人做同一个动作时的独特变化。尽管这些问题并不是这个具体的实施所独有的,但由于面临着如何在个性化运动检测器件中找到这个平衡点的挑战,因此需要能够利用用户的特定数据来更新决策树。但在仔细考虑这些对于机器学习数据科学的各种要求之后,开发人员已经能够利用 LSM6DSOX 和现有的工作流将始终开启精密运动检测功能整合到功率受限的设计中。
总结
用户需要始终开启运动跟踪和更长电池续航时间,这为健身设备和其他小型可穿戴设备的开发人员带来了似乎无法克服的冲突。尽管很多高级传感器都能提供一定水平的独立于处理器的运动检测,但由于用户需要始终开启对更复杂运动的检测,因此一些新兴的应用抛弃了这种方法。
不过,使用 STMicroelectronics 的 LSM6DSOX 运动传感器提供的机器学习能力,开发人员可以解决始终开启跟踪与更长电池续航时间之间的冲突,从而构建更加高级并能够感知活动的健身腕带和其他可穿戴设备。
-
意法半导体推出具有机器学习功能的LSM6DSOXiNEMO™传感器运动传感器2019-02-13 2389
-
如何有效使用智能运动传感器进行运动跟踪?2019-07-26 6690
-
智能机器人对于传感器的需求2015-01-20 6843
-
什么运动跟踪传感器能跟踪多个对象?2018-10-19 5062
-
在运动控制中,传感器是控制的关键部分2018-11-12 2278
-
焊接传感器一款转为焊接机器人而设计的焊缝跟踪传感器2020-06-16 1877
-
管焊机器人适配激光焊缝跟踪传感器搭载5G技术,智能工业发展的新方向2020-07-29 1230
-
怎样去设计一种基于LSM6DSOX运动传感器的机器学习电路?2021-07-02 2294
-
MMA9550L 内置智能的高精度运动传感器2010-09-15 1517
-
ST推出具有机器学习功能的新型运动传感器2019-02-14 4472
-
8位AVR内核可以做什么?2021-04-01 882
-
使用智能传感器的内置机器学习核心来优化“始终在线”的运动跟踪2022-11-25 290
-
8位AVR内核可以做什么2023-09-25 643
-
电弧跟踪传感器通常安装在机器人什么位置?2023-11-23 1647
-
焊缝跟踪未来:人工智能与机器学习的影响2023-12-12 1213
全部0条评论

快来发表一下你的评论吧 !
