

关于自动机器学习的概述(AutoML)
人工智能
描述
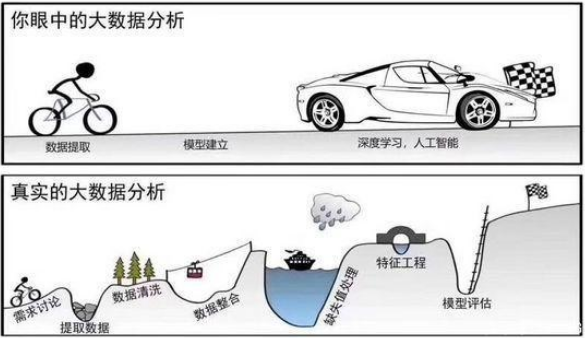
机器学习是让算法自动的从数据中找出一组规则,从而提取数据中对分类/聚类/决策有帮助的特征,随着机器学习的发展,其中人工需要干预的部分越来越多,而AutoML则是对机器学习模型从构建到应用的全过程自动化,最终得出端对端的模型(end to end)。有了AutoML,机器学习就会从下图的曲折变为上图的一马平川。
从流程先后顺序来分,最初是数据准备,包括数据收集和清洗,之后是特征工程,其中包括特征选择(决定哪些特征需要保留),特征提取(对特征进行降维,常用的方法例如PCA),特征组合(将多个特征合并/构建为一个新的特征)。
在之后的模型构建中,最关键的是模型选择,之后超参数优化,可以采取很多方式,最简单的做法是网格搜索,常用的方法包括用强化学习,进化算法,贝叶斯优化,以及梯度下降,来缩小搜索空间;最后,AutoML通过引入提前停止,降低模型的精度,参数共享来自动化模型评价的过程。
数据收集这项任务,不在是搜索与收集真实数据,还包括产生模拟数据,用来扩展训练数据集,可以使用的新技术包括对抗神经网络(点击查看对应文章),还可以使用强化学习的框架,来优化用于控制生成数据的参数,从而使得生成的数据能更有效的助力模型的训练。而数据清洗则是自动完成包括缺失值补全,离群点处理,特征归一化,类别型特征的不同编码等之前手动完成的工作。
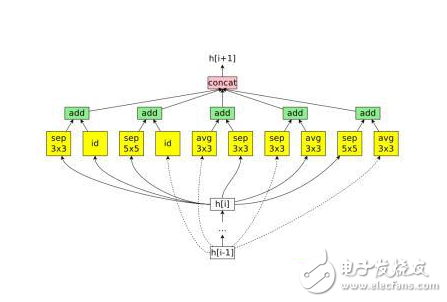
模型的自动化选择,传统的方法是从传统的模型,例如KNN,SVM,决策树中选出一个,或多个组合起来效果最好的模型,而当前AutoML的研究热点是N eural Architecture Search, 也就是不经过人工干预,模型自动生成一个对当前任务最有效的网络结构,模型自动在自我生产的不同结构下搜索最好的操作组合序列。
搜索的结果如下图所示:
其中应用到强化学习的部分如下图所示:
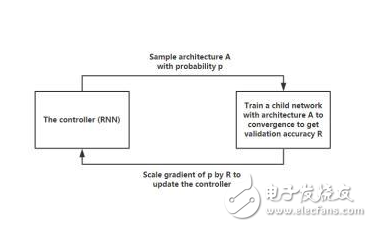
这里的行为是以一定的概率选择某个网络结构,行为是在该结构下,训练子网络,使其在训练集上达到预设的准确率,奖励是该子网络在测试数据集上的准确率与该网络被选择的概率的乘积,通过将子模型的泛化能力作为反馈,用于控制不同模型被选择概率的RNN得以优化其梯度,以选出泛化能力最强的模型,同时通过始终保持一定概率选择其他模型,处理explore VS exploit的权衡。
NAS算法作为当前AutoML最热的研究领域,有很多变种,下图展示了在CIFAR1000上,不同NAS方法的效果及训练用时。相比于强化学习和进化算法,传统方法的用时更少。为了找到合适的网络架构,除了传统的串行网络,还有基于cell来做层级化网络架构搜索的。下图展示的是先从几个最基本的操作,搜索得出一个一级的网络组件,之后在自动化的搜索如何用一级组件搭建网络。
模型选定后的调参过程,最常用的是网格搜索,也就是按照固定的间距,在搜索空间上打点,但下图指出,网格搜索不一定好过随机搜索,原因是对于重要参数,网格搜索采样地点会不足,从而导致无法取到对模型效果相对较好的点,autoML会使用随机抽样,首先评价各个超参数的重要性,之后再对重要的参数进行微调。
-
NFA→FA→GFA自动机转换算法2008-12-10 1096
-
[自动机与自动线].李绍炎.扫描版2013-09-17 1369
-
元胞自动机的介绍资料2016-06-24 776
-
自动机械设计2017-08-02 1673
-
基于统计的AC自动机空间优化2018-03-13 1242
-
Waymo用AutoML自动生成机器学习模型2019-01-19 4169
-
深兰科技发布采用AutoML技术的现代农业开放平台2020-04-29 4239
-
清华大学发布首个开源自动图学工具包2020-12-22 2440
-
自动机器学习简述2020-12-26 1780
-
量化自动机器人是什么2021-03-17 7741
-
自动机终结字查找算法实现优化综述2021-04-28 929
-
自动机器学习的优点与痛点2021-09-01 5791
-
预先设置NAS算法能否实现AutoML自动机器学习革命2021-12-09 670
-
AutoML:训练模型以识别凹坑2022-03-15 3324
-
制作钢琴瓷砖自动机器人2022-11-29 570
全部0条评论

快来发表一下你的评论吧 !
