

Elasticsearch概述 怎么安装ES
电子说
描述
1 Elasticsearch概述
1.1 认识ES
Elasticsearch是一个基于Lucene库的搜索引擎。它提供了一个分布式、支持多租户的全文搜索引擎,可以快速地储存、搜索和分析海量数据。可以用于搜索各种文档并支持多租户。Elasticsearch至少需要Java 8。
1.2 应用场景
在线网上商店,允许客户搜索您销售的产品。在这种情况下,可以使用Elasticsearch存储整个产品目录和库存,并为它们提供搜索和自动填充建议。
收集日志或交易数据,并分析和挖掘此数据以查找趋势,统计信息,摘要或异常。在这种情况下,您可以使用Logstash来收集,聚合和解析数据,然后让Logstash将此数据提供给Elasticsearch。一旦数据在Elasticsearch中,您就可以运行搜索和聚合来挖掘您感兴趣的任何信息。
价格警报平台,允许精通价格的客户指定一条规则,例如“我有兴趣购买特定的电子产品,如果小工具的价格在下个月内从任何供应商降至X美元以下,我希望收到通知” 。在这种情况下,您可以刮取供应商价格,将其推入Elasticsearch并使用其反向搜索功能来匹配价格变动与客户查询,并最终在发现匹配后将警报推送给客户。
1.3 重要概念
集群Cluster:集群是一个或多个节点的集合,它们共同保存您的整个数据,并提供跨所有节点的联合索引和搜索功能。
节点Node:节点是作为集群一部分的单个服务器,存储数据并参与群集的索引和搜索功能。
索引Index:索引是具有某些类似特征的文档集合。索引由名称标识,必须全部小写,此名称用于在对其中的文档执行索引,搜索,更新和删除操作时引用索引。
文档Document:文档是可以编制索引的基本信息单元。Index 里面单条的记录称为 Document。
分片和副本:索引可能存储大量可能超过单个节点的硬件限制的数据。为了解决这个问题,Elasticsearch提供了将索引细分为多个称为分片的功能。
1.4 核心模块
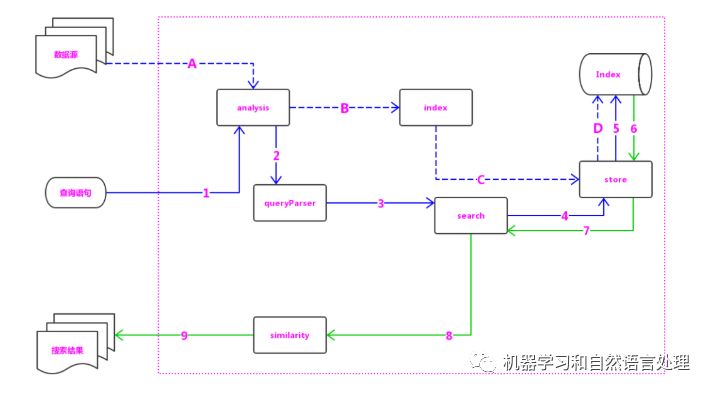
analysis:主要负责词法分析及语言处理,也就是我们常说的分词,通过该模块可最终形成存储或者搜索的最小单元 Term。
index 模块:主要负责索引的创建工作。
store 模块:主要负责索引的读写,主要是对文件的一些操作,其主要目的是抽象出和平台文件系统无关的存储。
queryParser 模块:主要负责语法分析,把我们的查询语句生成 Lucene 底层可以识别的条件。
search 模块:主要负责对索引的搜索工作。
similarity 模块:主要负责相关性打分和排序的实现。
1.5 检索方式
单个词查询:指对一个 Term 进行查询。比如若要查找包含字符串“Lucene”的文档,则只需在词典中找到 Term“Lucene”,再获得在倒排表中对应的文档链表即可。
AND:指对多个集合求交集。比如若要查找既包含字符串Lucene又包含字符串Solr的文档,则查找步骤如下:在词典中找到 Term Lucene得到Lucene对应的文档链表。在词典中找到 TermSolr,得到Solr对应的文档链表。合并链表,对两个文档链表做交集运算。
OR:指多个集合求并集。比如,若要查找包含字符串Luence或者包含字符串Solr的文档,则查找步骤如下同上,对两个文档链表做并集运算,合并后的结果包含Lucene或者包含Solr。
NOT:指对多个集合求差集。比如若要查找包含字符串Solr但不包含字符串Lucene的文档,则查找步骤如下同上,对两个文档链表做差集运算,用包含Solr的文档集减去包含Lucene的文档集,运算后的结果就是包含Solr但不包含Lucene。
2 ES特性与优缺点
2.1 ES特性
Elasticsearch可扩展高达PB级的结构化和非结构化数据。
Elasticsearch可以用来替代MongoDB等做文档存储。
Elasticsearch使用非标准化来提高搜索性能。
Elasticsearch是受欢迎的企业搜索引擎之一,目前使用如Wikipedia,GitHub等。
Elasticsearch是开放源代码,可在Apache许可证版本2.0下提供。
2.2 ES优点
Elasticsearch是基于Java开发的,这使得它在几乎每个平台上都兼容。
Elasticsearch是实时的。
Elasticsearch是分布式的,这使得它易于在任何大型组织中扩展和集成。
与Apache Solr相比,在Elasticsearch中处理多租户非常容易。
Elasticsearch使用JSON对象作为响应。
Elasticsearch支持几乎大部分文档类型,但不支持文本呈现的文档类型。
2.3 ES缺点
Elasticsearch在处理请求和响应数据方面没有多语言和数据格式支持(仅在JSON中可用),与Apache Solr不同不可以使用CSV,XML等格式。
Elasticsearch也有一些伤脑的问题发生,虽然在极少数情况下才会发生。
3 ES安装部署
本文主要采用Win10下的Elasticsearch安装,当然Linux安装操作起来更加简便了。完成之后对python安装elasticsearch包,并实现交互案例。
❶ 第一步:条件检查
Elasticsearch至少需要Java 8,首先需要java -version查看当前版本。

❷ 第二步:安装ES
这里采用elasticsearch-7.1.0-windows-x86_64下载地址链接: https://pan.baidu.com/s/1k5AOGpMy8uJEXtA6KoNb7g 提取码: qtmj 。
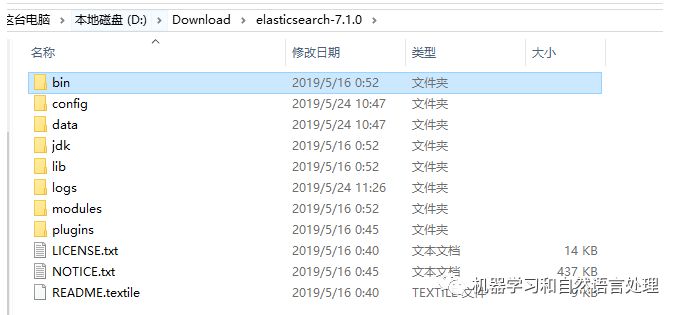
★ bin :运行Elasticsearch实例和插件管理所需的脚本
★ confg: 配置文件所在的目录
★ lib : Elasticsearch使用的库
★ data : Elasticsearch使用的所有数据的存储位置
★ logs : 关于事件和错误记录的文件
★ plugins: 存储所安装插件的地方,比如中文分词工具
然后去运行 bin/elasticsearch(Mac 或 Linux)或者 binelasticsearch.bat (Windows) 即可启动 Elasticsearch 了。我们启动后发现网页并不现实信息,测试下本地网络是否联通:
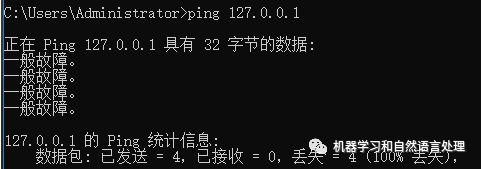
发现是一般性故障,查询资料显示由于防火墙的问题,经过测试关闭”公用网络防火墙“即可:

后我们再去ping下本地IP:
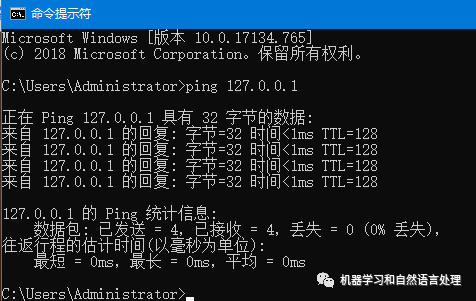
这时已经显示ping通状态,再次启动binelasticsearch.bat (Windows),打开http://localhost:9200/显示如下表示成功安装ES。
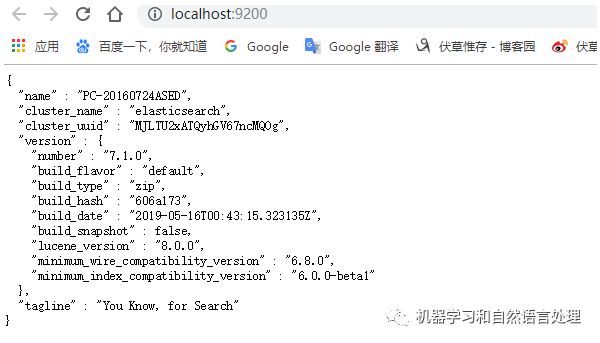
❸ 第三步:Python安装ES
下载地址是https://www.elastic.co/downloads/elasticsearch。如果在windows下安排部署参考文章http://www.cnblogs.com/viaiu/p/5715200.html。如果是Python开发可以使用pip install elasticsearch安装。

4 ES构建全文搜索
4.1 插入数据
打开python运行环境,首先导入【from elasticsearch import Elasticsearch】,然后编写插入数据的方法:
# 插入数据 def InsertDatas(): # 默认host为localhost,port为9200.但也可以指定host与port es = Elasticsearch() es.create(index="my_index",doc_type="test_type",id=11,ignore=[400,409],body={"name":"python","addr":'四川省'}) # 查询结果 result = es.get(index="my_index",doc_type="test_type",id=11) print('单条数据插入完成: ',result)
实例化Elasticsearch,其中默认为空即host为localhost,port为9200。为空也可以指定网络IP与端口。通过创建索引index和文档类别doc_type,文档id,body为插入数据的内容,其中ES支持的数据仅为JSON类型,ignore=409忽略异常。运行结果如下:

4.2 批量插入数据
上面案例我们插入一条信息,查询显示一系列参数包括索引、文档类型、文档ID唯一标识,版本号等。其中资源中包含数据信息,如果我们想插入多条信息可以参考以下代码:
# 批量插入数据 def AddDatas(): es = Elasticsearch() datas = [{ 'name': '美国留给伊拉克的是个烂摊子', 'addr': 'http://view.news.qq.com/zt2011/usa_iraq/index.htm' },{ "name":"python", "addr":'四川省' }] for i,data in enumerate(datas): es.create(index="my_index",doc_type="test_type", id=i,ignore=[400,409],body=data) # 查询结果 result = es.get(index="my_index",doc_type="test_type",id=0) print(' 批量插入数据完成: ',result['_source'])
我们将数据放在datas列表中,如果我们数据在一个json文件中存储,也可以通过读取文本信息并保存在datas中,之后对其进行插入即可。这里面文件ID我采用枚举的序号,也可以采用随机数或者指定格式。完成所有插入之后我们选择第一条id=0的信息查询,此处查询与上文不同,我们只看文章内容可以采用result['_source']方法,结果如下:

4.3 更新数据
如果我们插入数据信息有问题,我们想去修正。可以采用update方法,这里面与我们接触的MySQL,MongoDB等SQL语句差不多。唯一注意的是我们更新数据时候采用{"doc":{"name":"python1","addr":"深圳1"}}字典模式,尤其是doc标识不能忘记,代码实现如下:
# 3 更新数据 def UpdateDatas(): es = Elasticsearch() es.update(index="my_index",doc_type="test_type",id=11,ignore=[400,409],body={"doc":{"name":"python1","addr":"深圳1"}}) # 更新结果 result = es.get(index="my_index",doc_type="test_type",id=11) print(' 数据id=11更新完成: ',result['_source']['name'])
这里我们假如只想查询更新后信息的name字段,可以采用source后面加['name']方法,为什么这么设置呢?请参看插入数据运行结果分析。

4.4 删除数据
这里面比较简单,我们指定文档的索引、文档类型和文档ID即可。
# 删除数据 def DeleteDatas(): es = Elasticsearch() result = es.delete(index='my_index',doc_type='test_type',id=11) print(' 数据id=11删除完成: ')
4.5 条件查询数据
我们通过插入数据构建一个简单我数据信息,如果我们想获取索引中的所有文档可以采用{"query":{"match_all":{}}}条件查询,这里面指定关注的是使用的search方法,上文查询数据采用get方法,其实两者都是可以作为查询使用的。代码如下:
# 条件查询 def ParaSearch(): es = Elasticsearch() query1 = es.search(index="my_index", body={"query":{"match_all":{}}}) print(' 查询所有文档 ',query1) query2 = es.search(index="my_index", body={"query":{"term":{'name':'python'}}}) print(' 查找名字Python的文档: ',query2['hits']['hits'][0])
我们获取索引所有文档的信息

获取文档中name为Python的信息

- 相关推荐
- 热点推荐
- 搜索引擎
- Elasticsearch
-
单节点Elasticsearch+Filebeat+Kibana安装指南2025-05-21 1506
-
如何在Linux环境下高效安装部署和配置Elasticsearch2025-01-16 2326
-
SpringBoot 连接ElasticSearch的使用方式2023-10-09 2785
-
SpringBoot整合ElasticSearch2023-03-09 1301
-
Elasticsearch入门简介2023-02-24 1471
-
Linux安装ElasticSearch2023-02-15 1640
-
ElasticSearch是什么?应用场景是什么?2022-10-09 3334
-
docker安装Elasticsearch操作指南2019-09-16 1570
-
在linux上安装部署ElasticSearch的详细操作2019-07-12 2075
-
基于HanLP的Elasticsearch中文分词插件2019-04-22 3618
-
linux安装配置ElasticSearch之源码安装2019-01-11 3041
-
hanlp for elasticsearch(基于hanlp的es分词插件)2018-11-29 743
-
如何在Python中进行Elasticsearch操作?2018-07-20 8548
全部0条评论

快来发表一下你的评论吧 !
