

一种具有强记忆力的 E3D-LSTM网络,强化了LSTM的长时记忆能力
电子说
描述
清华大学、Google AI 和斯坦福大学李飞飞团队提出了一种具有强记忆力的 E3D-LSTM 网络,强化了 LSTM 的长时记忆能力,这为视频预测、动作分类等相关问题提供了新思路,是一项非常具有启发性的工作。 如何对时间序列进行时空建模及特征抽取,是 RGB 视频预测分类,动作识别,姿态估计等相关领域的研究热点。 清华大学、Google AI 和斯坦福大学李飞飞团队提出了一种具有强记忆力的 E3D-LSTM 网络,用 3D 卷积代替 2D 卷积作为 LSTM 网络的基础计算操作,并加入自注意力机制,使网络能同时兼顾长时和短时信息依赖以及局部时空特征抽取。 这为视频预测、动作分类等相关问题提供了新思路,是一项非常具有启发性的工作。

时间序列的时空建模问题 现实生活中许多数据都同时具有时间特征和空间特征,例如人体的运动轨迹,连续帧的视频等,每个时间点都对应一组数据,而数据往往又具有一定的空间特征。因此要在这样的时间序列数据上开展分类,预测等工作,就必须在时间(temporal)和空间 (spatial) 上对其进行建模和特征抽取。 常用的时间建模工具是循环神经网络(RNN)相关模型(LSTM 等),由于其特有的门结构设计,对时间序列特征具有强大的抽取能力,因此被广泛应用于预测问题并取得了良好的成果,但是 RNN 并不能很好的学习到原始特征的高阶表示,这不利于对空间信息的提取。空间建模则当属卷积神经网络(CNN),其具有强大的空间特征抽取能力,其中 3D-CNN 又能将卷积核可控范围扩大到时域上,相对于 2D 卷积灵活性更高,能学习到更多的运动信息(motion 信息),相对于 RNN 则更有利于学习到信息的高级表示(层数越深,信息越高级), 是目前动作识别领域的流行方法。当然 3D 卷积的时间特征抽取能力并不能和 RNN 媲美。 得益于 3D 卷积和 RNN 在各自领域的成功,如何进一步将二者结合起来使用也成为了研究热点,常见的简单方法是将二者串联堆叠或者并联结合(在图卷积网络出现之前,动作识别领域的最优方法就是将 CNN 和 RNN 并联),但测试发现这么做并不能带来太大的提升,这是因为二者的工作机制差距太大,简单的结合并不能很好的实现优势互补。本文提出用 3D 卷积代替原始 LSTM 中的门更新操作,使 LSTM 不仅能在时间层面,也能在空间层面上进行短期依赖的表象特征和运动特征的抽取,从而在更深的机制层面实现两种网络的结合。此外,在 LSTM 中引入自注意力(self-attention)机制,进一步强化了 LSTM 的长时记忆能力,使其对长距离信息作用具有更好的感知力。作者将这种网络称为 Eidetic 3D LSTM(E3D-LSTM),Eidetic 意思是具有逼真记忆,强调网络的强记忆能力。 E3D-LSTM 网络结构

图 1:三种不同的 3D 卷积和 LSTM 的结合方法 图中每个颜色的模块都代表了多层相应的网络。图(a)和图(b)是两种 3D 卷积和 LSTM 结合的基线方法,3D 卷积和 LSTM 线性叠加,主要起到了编码(解码器)的作用,并没有和 RNN 有机制上的结合。图(a)中 3D 卷积作为编码器,输入是一段视频帧,图(b)中作为解码器,得到每个单元的最终输出。这两个方法中的绿色模块使用的是时空长短时记忆网络(ST-LSTM)[1],这种 LSTM 独立的维护两个记忆状态 M 和 C,但由于记忆状态 C 的遗忘门过于响应具有短期依赖的特征,因此容易忽略长时依赖信息,因此 E3D-LSTM 在 ST-LSTM 的基础添加了自注意力机制和 3D 卷积操作,在一定程度上解决了这个问题。具体单元结构下一节介绍。 图(c)是 E3D-LSTM 网络的结构,3D 卷积作为编码 - 解码器(蓝色模块),同时和 LSTM 结合(橙色模块)。E3D-LSTM 既可用于分类任务,也可用于预测任务。分类时将所有 LSTM 单元的输出结合,预测时则利用 3D 卷积解码器的输出作为预测值。 E3D-LSTM 单元结构设计
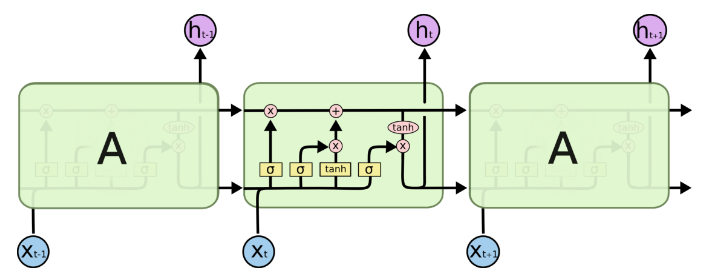
图 2:标准 LSTM 单元结构 首先简要介绍一下标准 LSTM 结构,和 RNN 相比 LSTM 增加了更复杂的门结构(图中黄色模块),主要解决 RNN 中存在的梯度消失问题,从而提高网络对长时依赖(long-term dependency)的记忆感知能力。LSTM 有两个输入门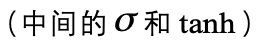 ,一个输出门
,一个输出门 和遗忘门
和遗忘门 。
。

图 2:ST-LSTM 网络结构和单元结构 和标准 LSTM 相比,ST-LSTM 还增加了不同层间对应位置的 cell 连接,如图 2 左侧,水平灰色连接线表示标准 LSTM 的单元连接,竖直黄色连接线表示层间同一时刻的单元连接,通过张量 M 传播,注意当 l=1 时, (作者认为 t 时刻的顶层信息对 t+1 时刻的底层信息影响很大),这样记忆信息就能同时在层内和层间传播。
(作者认为 t 时刻的顶层信息对 t+1 时刻的底层信息影响很大),这样记忆信息就能同时在层内和层间传播。


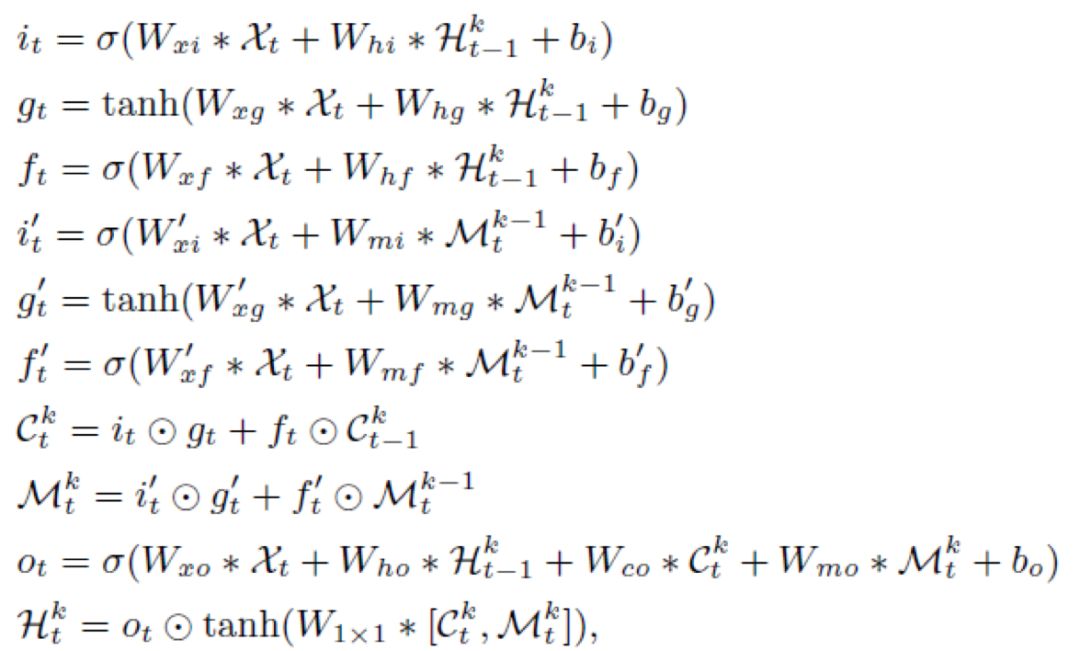

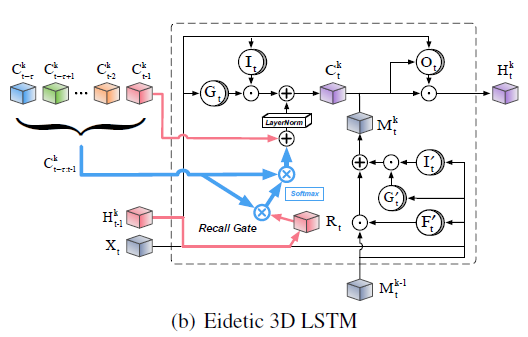
图 3 E3D-LSTM 单元结构 图 3 是本文提出的 E3D-LSTM 模型的单元结构,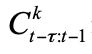 是一个维度为
是一个维度为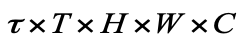 的五维张量,代表之前
的五维张量,代表之前 个时间步的所有隐状态。
个时间步的所有隐状态。 表示召回门(代替遗忘门),和 ST-LSTM 相比,主要有以下改进:
表示召回门(代替遗忘门),和 ST-LSTM 相比,主要有以下改进:
1、输入数据是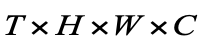 的四维张量,对应时刻
的四维张量,对应时刻 的连续帧序列,因此现在每个单元时间步都对应一段视频,而不是单帧视频。
的连续帧序列,因此现在每个单元时间步都对应一段视频,而不是单帧视频。
2、针对帧序列数据额外添加了一个召回门(recall gate)以及相关结构,用于实现长时依赖学习,也就是自注意力机制。这部分对应网络名称中的 Eidetic。
3、由于输入数据变成了四维张量,因此在更新公式中采用 3D 卷积操作而不是 2D 卷积。 大部分门结构的更新公式和 ST-LSTM 相同,额外添加了召回门更新公式:
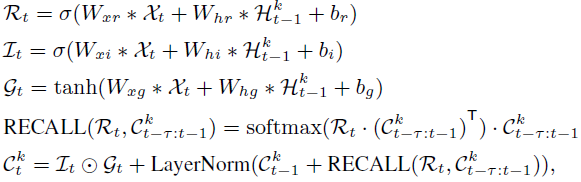

上面介绍的机制用于同一层不同时间步连接,作者将这种机制也用在了不同层同一时间步的连接,但效果并不好,这是因为不同层在同一时刻学习到的信息并没有太好的依赖性。 基于 E3D-LSTM 的半监督辅助学习 在许多监督学习任务,例如视频动作识别中,没有足够的监督信息和标注信息来帮助训练一个令人满意的 RNN,因此可以将视频预测作为一个辅助的表征学习方法,来帮助网络更好的理解视频特征,并提高时间域上的监督性。 具体的,让视频预测和动作识别任务共享相同的主干网络(图 1),只不过损失函数不同,在视频预测任务中,目标函数为:
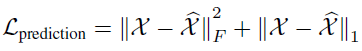
带上标的 X 表示预测值,不带上标的表示真值,F 表示 Frobenius 归一化。 在动作识别任务中,目标函数为:
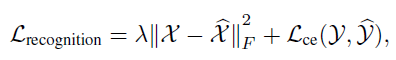
其中 Y 和 是预测值和帧值,这样通过将预测任务的损失函数嵌入到识别任务中,以及主干网络的共享,能在一定程度上帮助识别任务学习到更多的时序信息。为了保证过渡平滑,额外添加了一个权重因子
是预测值和帧值,这样通过将预测任务的损失函数嵌入到识别任务中,以及主干网络的共享,能在一定程度上帮助识别任务学习到更多的时序信息。为了保证过渡平滑,额外添加了一个权重因子 ,会随着迭代次数的增加而线性衰减:
,会随着迭代次数的增加而线性衰减: 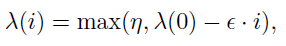 作者将这种方法称为半监督辅助学习。 实验结果 视频预测任务,在 Moving MINIST 数据集上的结果:
作者将这种方法称为半监督辅助学习。 实验结果 视频预测任务,在 Moving MINIST 数据集上的结果:
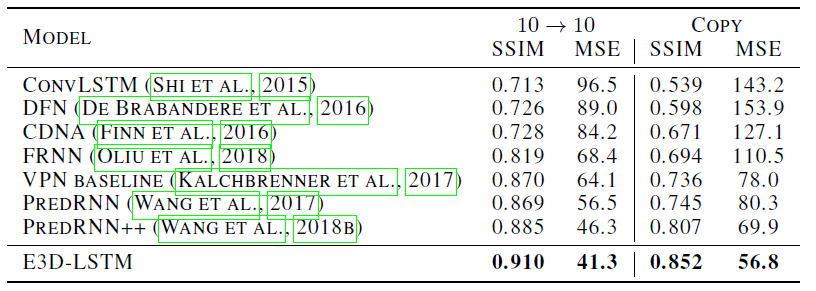
为了验证 E3D-LSTM 中不同模块对性能的影响,作者还在该数据集上进行了烧蚀研究:

可以看到不管是添加 3D 卷积还是自注意力机制,网络性能相对于基线方法都有提升。 视频预测任务,在 KTH 人体动作数据集上的结果:
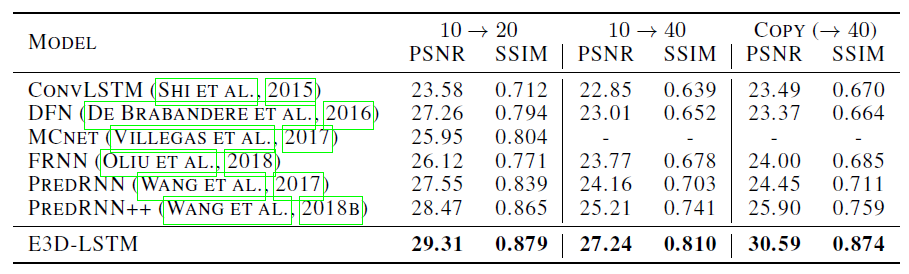
接下来在一个实际视频预测任务:交通流预测中,与其他方法进行了对比:
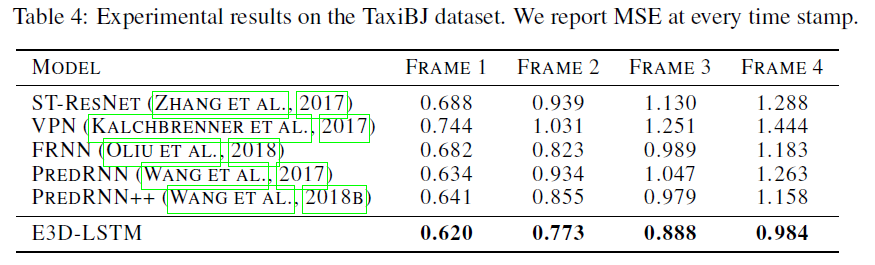
动作识别任务,在 Something-Something 数据集上进行了测试:

同样在该数据集上进行了烧蚀研究:

以及不同的半监督辅助学习策略带来的性能提升:
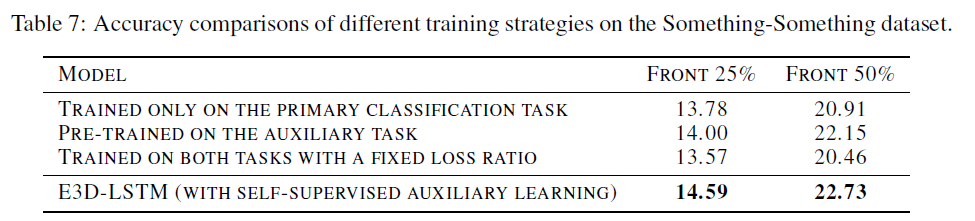
总结 本文对 ST-LSTM 进行了改进,将流行的 3D 卷积操作作为其基本张量操作,同时添加了自注意力模块,进一步强化了网络对长距离依赖信息的刻画能力,不仅能用于预测任务,还能通过辅助学习的方法拓展到其他任务上,是非常具有启发性的工作。 [1] Yunbo Wang, Mingsheng Long, Jianmin Wang, Zhifeng Gao, and S Yu Philip. Predrnn: Recurrent neural networks for predictive learning using spatiotemporal lstms. In NIPS, 2017. (本文经授权转载自AI科技大本营,ID: rgznai100)
-
LSTM神经网络的基本原理 如何实现LSTM神经网络2024-11-13 3136
-
LSTM模型的基本组成2024-07-10 4718
-
PyTorch教程之长短期记忆(LSTM)2023-06-05 768
-
长短时记忆网络(LSTM)介绍2022-02-14 6952
-
基于时空特性的ST-LSTM网络位置预测模型2021-06-11 1450
-
长短时记忆网络(LSTM)2021-01-27 1618
-
清华、GoogleAI和斯李飞飞团队提出具有强记忆力的E3D-LSTM网络2019-08-27 2758
-
记忆力增进器电路图2010-08-03 729
全部0条评论

快来发表一下你的评论吧 !
