

TensorFlow2.0中创建了一个Transformer模型包,可用于重新构建GPT-2、 BERT和XLNet
电子说
描述
今日Reddit最热帖。博主在TensorFlow2.0中创建了一个Transformer模型包,可用于重新构建GPT-2、 BERT和XLNet。这个项目的目标是创建Transformer模型的所有核心部分,这样就可以重用它们来创建更新的、更多的SOTA模型,比如BERT和XLNet。
Transformer是谷歌在2017年提出的一个革新性的NLP框架,相信大家对那篇经典论文吸睛的标题仍印象深刻:Attention Is All You Need。
自那以来,业内人士表示,在机器翻译领域,Transformer 已经几乎全面取代 RNN。总之 Transformer 确实是一个非常有效且应用广泛的结构,应该可以算是自 seq2seq 之后又一次 “革命”。
如今,谷歌手上握有两个强大的AI战力:TensorFlow 2.0和Transformer。如果能将两大战力合体,就能制造出更强大的AI武器。
想到不如做到。于是Zachary Bloss(就是下图这位带着淡淡忧伤的背影),一位美国最大的非银行贷款机构之一Quicken Loans的数据分析师,花了一点时间,在TF2中构建一个可扩展的transformer模型。
该项目的目标是创建"Attention is all you need"论文中所讨论的transformer模型的所有核心部分,以便可以重复使用它们来创建更前卫、更多像BERT和XLNet一样的SOTA模型,
Zachary已经将做好的模型打包放在了GitHub上,而且这个包抽象度很高,只要是相关的类都可以随意使用。
只要你野心够大,完全可以用这个包来折腾Encoder和Decoder类去创建其他模型,比如BERT,Transformer-XL,GPT,GPT-2甚至XLNet都没问题,你只需要调整masking类即可。
那么我们看看具体应该如何安装和使用。
如何安装
前期准备
进行安装
强烈建议为项目创建一个新的虚拟环境!因为此软件包需要Tensorflow 2.0,你懂的。
接下来通过安装Tensorflow 2.0的gpu版本来使用GPU:
如何使用
Repo里有一个(example.py)文件。这是一个示例文件,可以用来了解此模型的工作原理。该模型以其最基本的形式,以numpy数组作为输入,并返回一个numpy数组作为输出。
此模型的常见用例是语言翻译。一般来说,训练这个模型的时候,功能列是原始语言,目标列是要翻译的语言。
生成输入/输出
这里提供了一些辅助函数,但基本上需要生成两个Tensorflow标记生成器以及一个带有功能和目标列的pandas DataFrame
可以利用DataProcess类中的辅助函数从DataFrame生成TensorDatasets,以及执行train_test_split
学习率/优化器
当设置在具有急剧倾斜然后指数衰减的自定义学习速率时,transformer模型表现优异
这项工作已在CustomSchedule()类中实现。随意玩热身步骤,以完成日程安排!
定义transformer模型
创建HPARAMS,定义模型的大小。
训练
定义Trainer类后,只需要在训练器对象上调用train()方法。
这将返回训练的准确性和损失
Attention is all you need
从实践中学习,才能对理论理解的更加透彻。在通过上述方式实操后,我们回过头再看Transformer的论文,可能就会觉得更加清晰了。
早在2年前,谷歌大脑、谷歌研究院和多伦多大学学者合作的一项新研究称,使用一种完全基于注意力机制(Attention)的简单网络架构 Transformer 用于机器翻译,效果超越了当下所有公开发表的机器翻译模型,包括集成模型。
值得一提的是,该研究没有使用任何循环或卷积神经网络,全部依赖注意力机制。正如文章的标题所说:“注意力机制是你需要的全部(Attention Is All You Need)。
一直以来,在序列建模和序列转导问题中,比如涉及语言建模和机器翻译的任务,循环神经网络(RNN),尤其是长短时记忆(LSTM)及门循环网络,都被视为最先进的方法。研究人员也想方设法拓展循环语言建模和编码器-解码器架构。
其中,注意力机制自提出以来便成为序列建模和转导模型不可或缺的一部分,因为注意力机制能够在不关注输入输出序列之间距离的情况下,对依存(dependence)建模。只有在极少数的案例中,作者将注意力机制与一个循环网络作为整个网络中相等的结构,并行放置。
在谷歌大脑最新公开的一项研究中,研究人员提出了一个全新的架构 Transformer,完全依赖注意力机制从输入和输出中提取全局依赖,不使用任何循环网络。
谷歌大脑的研究人员表示,Transformer 能够显著提高并行效率,仅在 8 颗 P100 GPU 上训练 12 小时就能达到当前最高性能。
论文作者以 Extended Neural GPU、ByteNet 和 ConvS2S 为例,这些结构都使用卷积神经网络(CNN)作为基本的模块,并行计算所有输入和输出位置的隐藏表征,从而减少序列计算的计算量。在这些模型中,将来自两个任意输入或输出位置的信号相关联的运算次数会根据位置之间的距离增加而增加,对于 ConvS2S 这种增加是线性的,而对于 ByteNet 则是呈对数增长的。
这让学习距离较远的位置之间的依赖难度增大。在 Transformer 当中,学习位置之间的依赖被减少了,所需的运算次数数量是固定的。
这需要使用自注意力(Self-attention),或内部注意力(intra-attention),这是一种与单个序列中不同位置有关的注意力机制,可以计算出序列的表征。
以往研究表明,自注意力已被成功用于阅读理解、抽象概括等多种任务。
不过,谷歌大脑的研究人员表示,据他们所知,Transformer 是第一个完全依赖自注意力的转导模型,不使用 RNN 或 CNN 计算输入和输出的表征。

摘要
当前主流的序列转导(transduction)模型都是基于编码器-解码器配置中复杂的循环或卷积神经网络。性能最好的模型还通过注意力机制将编码器和解码器连接起来。
提出了一种简单的网络架构——Transformer,完全基于注意力机制,没有使用任何循环或卷积神经网络。两项机器翻译任务实验表明,这些模型质量更好、可并行化程度更高,并且能大大减少训练时间。
该模型在 WMT 2014 英德翻译任务上实现了 28.4 的 BLEU 得分,在现有最佳成绩上取得了提高,其中使用集成方法,超过了现有最佳成绩 2 个 BLEU 得分。
在 WMT 2014 英法翻译任务中,该模型在单一模型 BLEU 得分上创下了当前最高分 41.0,而训练时间是在 8 颗 GPU 上训练 3.5 天,相比现有文献中的最佳模型,只是其训练成本的很小一部分。
研究还发现,Transformer 泛化性能很好,能够成功应用于其他任务,比如在拥有大规模和有限训练数据的情况下,解析英语成分句法解析(English constituency parsing)。
模型架构
大多数性能较好的神经序列转导模型都使用了编码器-解码器的结构。Transformer 也借鉴了这一点,并且在编码器-解码器上使用了全连接层。
编码器:由 6 个完全相同的层堆叠而成,每个层有 2 个子层。在每个子层后面会跟一个残差连接和层正则化(layer normalization)。第一部分由一个多头(multi-head)自注意力机制,第二部分则是一个位置敏感的全连接前馈网络。
解码器:解码器也由 6 个完全相同的层堆叠而成,不同的是这里每层有 3 个子层,第 3 个子层负责处理编码器输出的多头注意力机制。解码器的子层后面也跟了残差连接和层正则化。解码器的自注意力子层也做了相应修改。
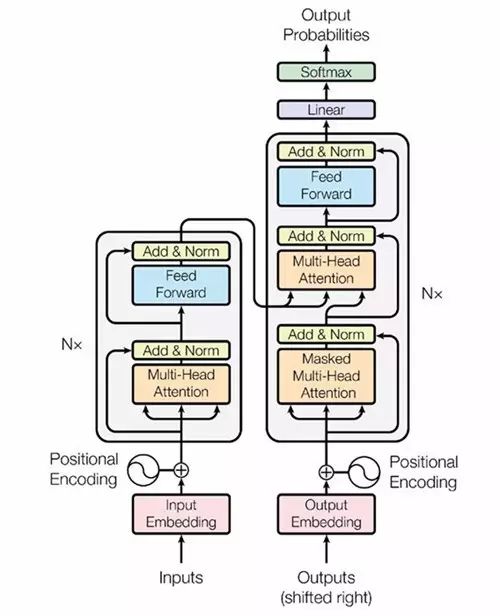
(图1)Transformer 的架构示意图
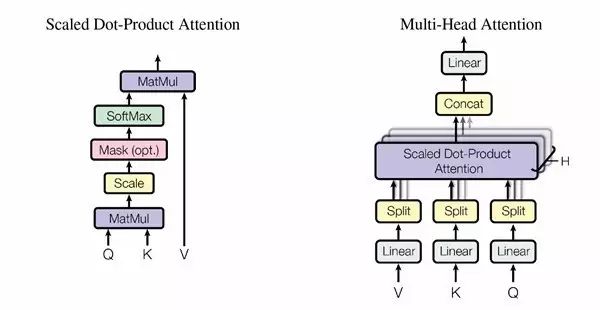
(图2)具体采用的注意力机制。左边是 Scaled Dot-Roduct Attention,右边是多头注意力(Multi-Head Attention),由几个并行的层组成。
在编码器-解码器层当中,query 来自上一个解码层,编码器输出值(value)及 memory key。这样,解码器中所有位置都能照顾到输入序列中的所有位置。
编码器含有自注意力层。在自注意力层中,所有的 key、value 和 query 都来自同一个地方,那就是编码器的上一层输出。编码器中的每一个位置都能照顾到编码器上一层中所有的位置。
同样,解码器中的自注意力层让解码器中所有位置都能被注意到,包括那个位置本身。
创造了BLEU的最高分28.4
在WMT2014 英语到德语的翻译任务中,大型transformer在性能上优于此前在有记录的所有模型(包括集成的模型),并且创造了BLEU的最高分28.4。
模型的配置详情见表3下的清单。训练过程为3.5天,在8颗P100 GPU上运行。即便是最基础的模型,也超越了此前所有发布的和集成的模型,但是训练的成本却只是此前最好的一批模型中的一小部分。
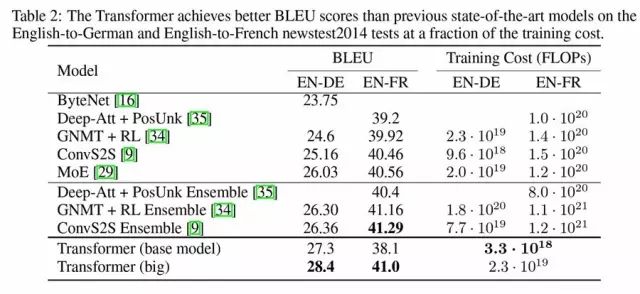
表2:Transformer 在英语到德语和英语到法语新闻测试2014数据集上,比此前最好的模型获得的BLEU分数都要高。
表2 总结了结果,并与其他模型在翻译质量和训练成本上进行对比,评估了被用于训练模型的浮点操作数量,用来乘以训练时间,使用的GPU的数量,并评估了每一颗GPU中,可持续的单精度浮点承载量。
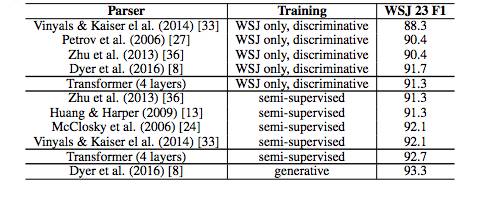
表4 Transformer 在英语成分句法解析任务上也取得了较好的效果。(基于WSJ Section 23 数据库)
为了测试Transformer能否用于完成其他任务,研究人员做了一个在英语成分句法解析上的实验。这一任务的难度在于:输出受到结构限制的强烈支配,并且比输入要长得多得多。另外,RNN序列到序列的模型还没能在小数据领域获得最好的结果。
- 相关推荐
- 热点推荐
- 机器翻译
- tensorflow
-
【大语言模型:原理与工程实践】大语言模型的基础技术2024-05-05 1330
-
如何使用TensorFlow构建机器学习模型2024-01-08 1900
-
500篇论文!最全代码大模型综述2023-11-17 2516
-
BEV人工智能transformer2023-08-22 1612
-
Transformer结构及其应用详解2023-06-08 3451
-
GPT/GPT-2/GPT-3/InstructGPT进化之路2023-03-03 5501
-
介绍XLNet的原理及其与BERT的不同点2022-11-01 2311
-
使用NVIDIA TensorRT优化T5和GPT-22022-03-31 4926
-
什么是XLNet,它为什么比BERT效果好2020-12-10 1164
-
高阶API构建模型和数据集使用2020-11-04 1780
-
OpenAI宣布,发布了7.74亿参数GPT-2语言模型2019-09-01 3659
-
XLNet和Bert比,有什么不同?要进行改进吗?2019-07-26 5832
-
OpenAI发布一款令人印象深刻的语言模型GPT-22019-05-17 5209
-
GPT2.0究竟是做什么的?有哪些优势和不足?未来发展趋势如何?2019-02-18 8891
全部0条评论

快来发表一下你的评论吧 !
