

Adam模型的新改进“Rectified Adam”
电子说
描述
UIUC华人博士生团队提出了对常用机器学习模型优化器Adam的新改进RAdam,省去了使用Adam必须的“预热”环节,既能保证学习率和收敛速度,又能有效避免模型陷入“局部最优解”的陷阱,堪称Adam的优秀接班人!
近日,UIUC的华人博士生Liyuan Liu等人的一篇新论文中介绍了Adam模型的新改进“Rectified Adam”(简称RAdam)。这是基于原始Adam作出的改进,它既能实现Adam快速收敛的优点,又具备SGD方法的优势,令模型收敛至质量更高的结果。
有国外网友亲测,效果拔群。
以下是网友测试过程和RAdam的简介:
我已经在FastAI框架下测试了RAdam,并快速获得了高精度新记录,而不是ImageNette上两个难以击败的FastAI排行榜得分。我今年测试了许多论文中的模型,大部分模型似乎在文中给出的特定数据集上表现良好,而在我尝试的新的数据集上表现不佳。但RAdam不一样,看起来真的实现了性能提升,可能成为vanilla Adam的永久“接班人”。
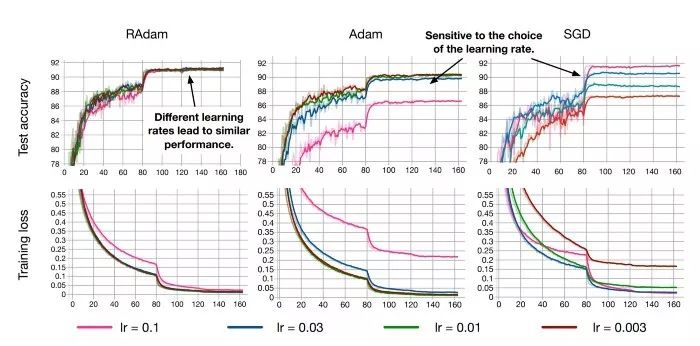
RAdam具备在多种学习率下的强大性能,同时仍能快速收敛并实现更高的性能(CIFAR数据集)
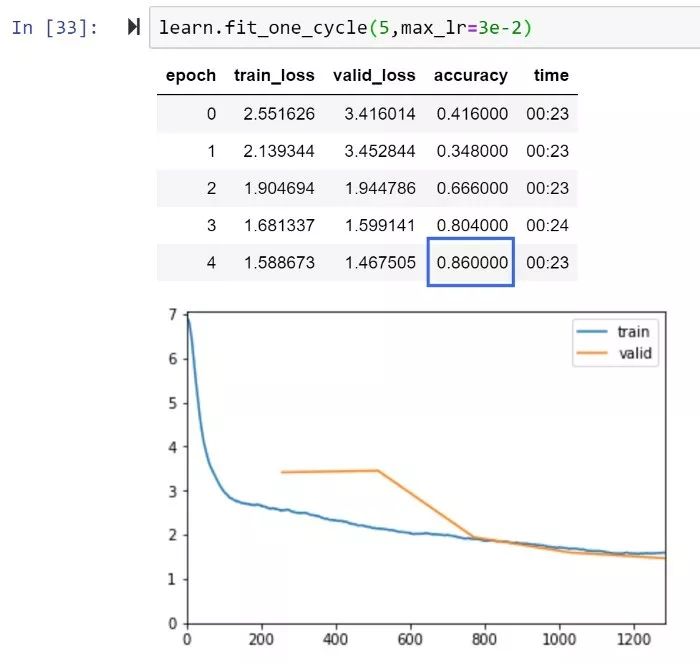
RAdam和XResNet50,5个epoch精度即达到86%

Imagenette排行榜:达到当前最高性能84.6%
下面来看看RAdam的内部机制,看看为什么能够实现更优质的收敛,更好的训练稳定性(相对所选择的学习率更不敏感),为何基于几乎所有AI应用都能实现更好的准确性和通用性。

不只是对于CNN:RAdam在Billion Word Dataset上的表现优于LSTM
RAdam:无需预热,避免模型收敛至“局部最优解”
作者指出,虽然每个人都在努力实现快速稳定的优化算法,但包括Adam,RMSProp等在内的自适应学习率优化器都存在收敛到质量较差的局部最优解的可能。因此,几乎每个人都使用某种形式的“预热”方式来避免这种风险。但为什么需要预热?
由于目前对AI社区中对于“预热”出现的潜在原因,甚至最佳实践的理解有限,本文作者试图揭示这个问题的基础。他们发现,根本问题是自适应学习率优化器具有太大的变化,特别是在训练的早期阶段,并且可能由于训练数据量有限出现过度跳跃,因此可能收敛至局部最优解。
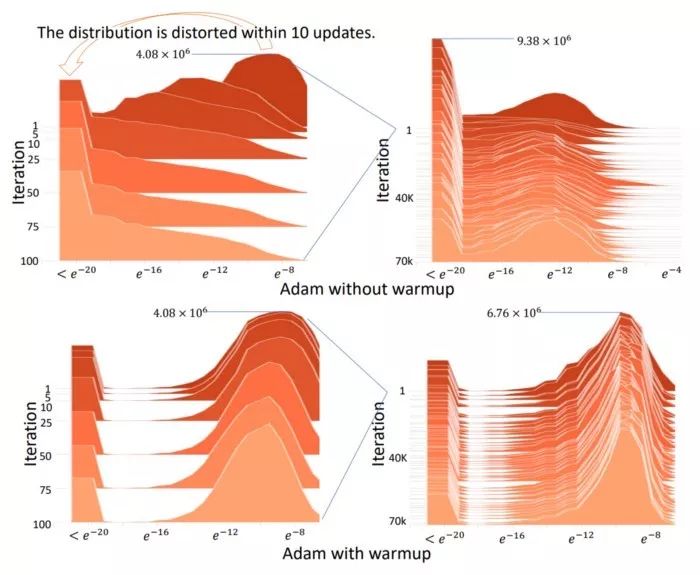
使用原始Adam必须预热,否则正态分布会变得扭曲,是否预热的分布对比见上图
因此,当优化器仅使用有限的训练数据时,采用“预热”(这一阶段的学习率要慢得多)是自适应优化器要求抵消过度方差的要求。
简而言之,vanilla Adam和其他自适应学习速率优化器可能会基于训练早期数据太少而做出错误决策。因此,如果没有某种形式的预热,很可能在训练一开始便会收敛局部最优解,这使得训练曲线由于糟糕的开局而变得更长、更难。
然后,作者在不用预热的情况下运行了Adam,但是在前2000次迭代(adam-2k)中避免使用动量,结果实现了与“Adam+预热”差不多的结果,从而验证了“预热”在训练的初始阶段中起到“降低方差”的作用,并可以避免Adam在没有足够数据的情况下在开始训练时即陷入局部最优解。
适用于多个数据集,堪称Adam的优秀“接班人”
我们可以将“预热”作为降低方差的方法,但所需的预热程度未知,而且具体情况会根据数据集不同而变化,本文确定了一个数学算法,作为“动态方差减少器”。作者建立了一个“整流项”,可以缓慢而稳定地允许将自适应动量作为基础方差的函数进行充分表达。完整模型是这样的:

作者指出,在某些情况下,由于衰减率和基本方差的存在,RAdam可以在动量等效的情况下退化为SGD。
实验表明,RAdam优于传统的手动预热调整,其中需要预热或猜测需要预热的步骤数。RAdam自动提供方差缩减,在各种预热长度和各种学习率下都优于手动预热。
总之,RAdam可以说是AI最先进的优化器,可以说是Adam的优秀接班人!
-
ADAM - 4572:一款强大的1端口Modbus网关2026-05-12 263
-
LabVIEW开发研华ADAM-4017+2022-06-13 15352
-
ADAM-4117测量电流的跳线该如何去设置?2021-07-26 2331
-
ADAM-4117快速入门手册-4-20模块知识及编程2019-07-08 5947
-
ADAM-4510I和ADAM-4520I及ADAM-4117技术数据资料免费下载2019-01-15 1617
-
ADAM AUDIO发布T系列专业录音监听音箱2018-05-31 11396
-
ADAM55102018-05-19 2183
-
基于研华ADAM模块的温度测量系统设计2017-04-20 2363
-
ADAM-4000-5000Utility_4.00.06_LabVIEW板卡2016-01-11 3052
-
ADAM应用配置程序Utility.exe安装2016-01-08 2707
-
基于LabView的研华ADAM4117远程采集例程2014-03-25 27133
-
研华科技发布工业级以太网远程I/O模块ADAM-61002011-08-29 3665
全部0条评论

快来发表一下你的评论吧 !
