

一文读懂NVMe的基本原理
接口/总线/驱动
描述
任何新技术的出现都是为了解决当前情况存在的问题。NVMe的出现也是为了解决当前存在的问题。这个问题就是日益快速增长的存储介质性能与传输通道性能太差之间的矛盾。基于SSD的存储设备性能都要上天了,但SAS和SATA接口的性能却没有本质的提升。
目前基于SCSI协议的SAS和SATA只能是单个队列而且每个队列的深度也比较低,分别是254和32的队列深度。而NVMe协议设计之初就考虑了该问题,它的***队列数量可以是64K(65535个命令队列和1个管理队列),而每个队列的深度可以高达64K。与SCSI协议相比,就好比一个乡村的羊肠小路和一个双向八车道的高速公路的差别。
图1 美丽的乡村下路和京港澳高速
NVMe基本原理
为了便于理解主机和NVMe设备的关系,我们这里简化NVMe设备的内部结构。如图2所示为NVMe白皮书中的配图,这里主机称为Host,而NVMe设备称为Controller(控制器)。主机和控制器之间通过共享内存的队列实现交互。
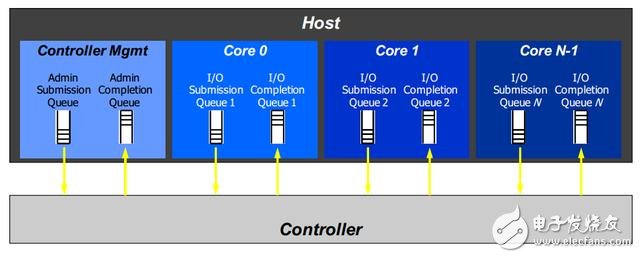
图2 NVMe多队列示意图
NVMe的队列分为2种,其中一种是用于管理的队列,称为Admin Queue(管理队列),仅有一个,另外一种是命令队列(Command Queue),最多可以有65535个。其中命令队列的数量和模式都是通过管理队列来设置的。其中每一个队列实际上是一个队列对,也就是包括两个队列,分别是提交队列(Submission Queue)和完成队列(Completion Queue)。提交队列用于主机端向NVMe设备发送NVMe命令,而完成队列则用于NVMe设备向主机反馈命令执行情况。实际上NVMe还有另外一种模式,就是多个提交队列共享同一个完成队列的情况,本文暂时不做介绍。
NVMe队列及命令的处理流程
上文我们知道NVMe是通过队列传递控制命令和命令等内容的,那么这里的队列实体到底是什么呢?其实这里提交队列和完成队列就是内存的一个区域。在数据结构原理上这里的队列其实是一个环形缓冲区,如图3所示。
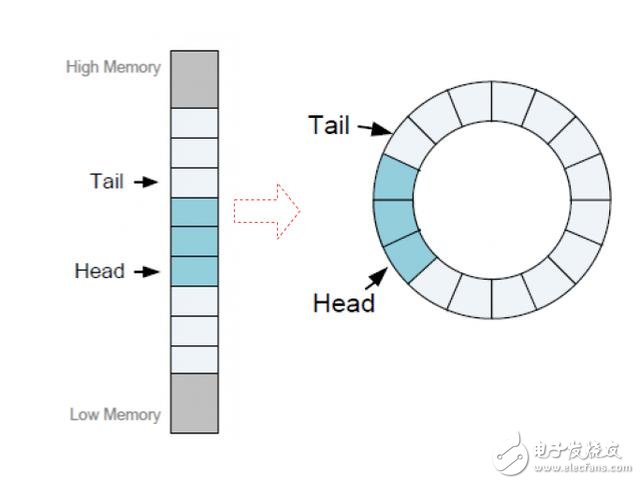
图3 环形缓冲区
NVMe通过一种门铃机制(Doorbell)来告知控制器命令队列是否有新数请求/命令。也就是说每个队列都有一个门铃指针。对于发送队列来说,这个指针表示的是发送队列的尾指针。主机端将数据写入到发送队列后,更新映射到位于设备寄存器空间中的门铃的尾指针。此时,在控制器端就知道有新的请求/命令到来,接下来就可以进行对其进行处理。
当控制器完成一个NVMe请求时,通过完成队列来把完成的结果告知主机端。与发送队列不同,完成队列是通过中断机制(可以是INTx,MSI或MSIx)告诉主机端。如图4是一个命令的完整处理流程。
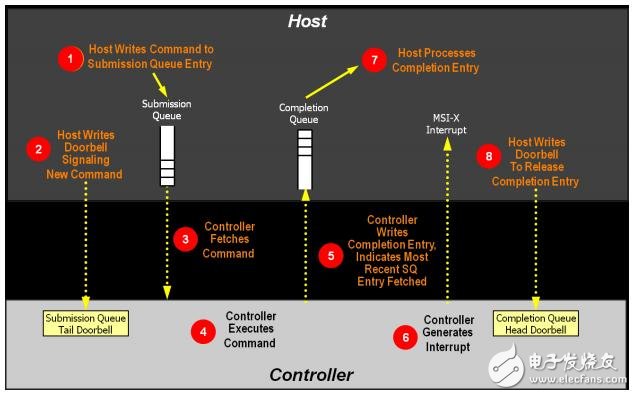
图4 命令处理完整流程
NVMe的命令格式
前面我们介绍了命令的发送和处理流程,接下来我们看看NVMe的命令长什么样。如图5是NMVe命令的具体格式,如果大家了解TCP/IP协议或者SCSI协议,那么理解本图将相当容易。在图4中每一行为8个字节,命令大小总共为64字节。
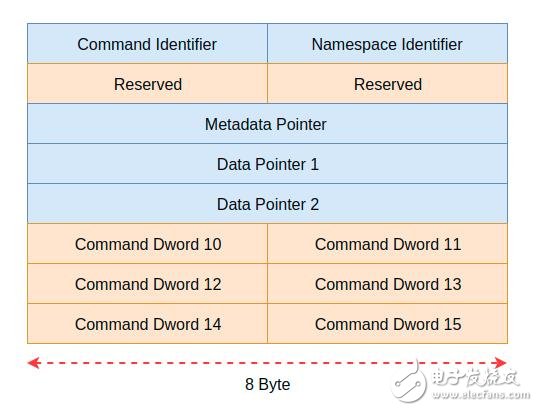
图5 NVMe的命令格式
在这个命令格式中有几个字段本身是比较复杂的,限于篇幅,且不打算让大家看完本文后头疼,本文不打算介绍所有细节。本文简单的介绍一下该命令格式的几个关键字段。其中Command Identifier标识一个具体的命令。Namespace Identifier则表示命令发送到那个命名空间。Data Pointer 1 和Data Pointer 2则用于标识数据的具体位置。
这里有两点需要说明:
NVMe的一个控制器下面可以有多个命名空间(Namespace),通过Namespace ID来标识的。
命令与数据是分离的,并不像TCP那样数据在命令后面。
我们这里重点介绍一下Command Identifier,该字段占用4个字节的空间。虽然仅有4个字节,但有分为3大部分,6小部分,具体如图6所示。
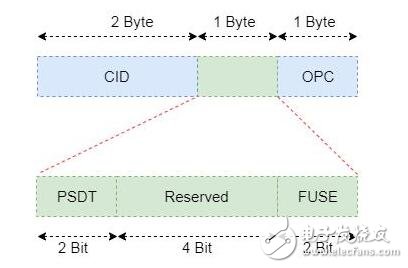
图6 命令标识格式
我们以从低位到高位的顺序分别介绍一下各个字段的含义:
OPC: 全称为Opcode,也就是被执行命令的操作码。具体来说就是想让控制器干什么,比如读数据、写数据或者刷写等。

图7 OPC定义
FUSE: 全称为Fused Operation, 用于标识该命令是普通命令还是复合命令。如图8是白皮书对该字段的说明。
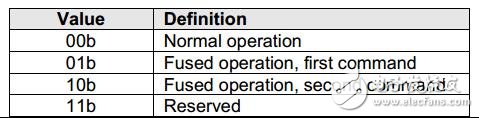
图8 FUSE的定义
PSDT: 全称为PRP or SGL for Data Transfer,这个用于说明存储数据的内存的组织形式。
NVMe的性能
***我们看一下NVMe与SAS和SATA存储设备的性能对比。为了避免广告嫌疑,本文就布局图说明设备的厂商和类型了。
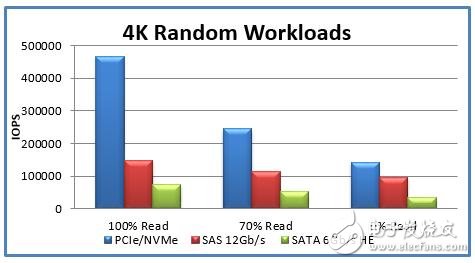
图9 性能对比
通过上图可以清楚的看到SAS和SATA设备与NVMe设备的性能差异,特别是对于读操作,NVMe有绝对的性能优势。
来源:itworld123 (SunnyZhang)
-
步进电机基本原理2012-08-16 2839
-
串联谐振逆变器的基本原理2018-11-07 6702
-
一文读懂接口模块的组合应用有哪些?2021-05-17 2484
-
串口通信基本原理是什么2021-07-14 2106
-
电机转动的基本原理是什么?2021-07-21 2484
-
线性电源的基本原理是什么2021-07-30 2245
-
一文读懂EtherCAT2021-09-02 6521
-
SPWM的基本原理2021-09-06 3714
-
无线充电的基本原理是什么2021-09-15 2726
-
RAID技术的基本原理是什么2021-10-14 2637
-
一文读懂什么是NEC协议2021-10-15 2720
-
DMA基本原理及相关实验相关资料推荐2021-12-10 1246
-
串口通信的基本原理是什么?2021-12-13 2983
-
步进马达基本原理2021-11-30 1910
-
一文读懂,什么是BLE?2023-11-27 5038
全部0条评论

快来发表一下你的评论吧 !
