

如何快速认识Ceph/CephFS,最简单的方式就是快速应用它
电子说
描述
大数据需要大存储,尤其是文件存储,Hadoop组件之一HDFS也因此得到了快速发展。随着AI时代的来临,机器学习对于大存储提出了更高的要求。 分布式、并行、高速、在线扩展、高可用、可靠、安全等等,现代机器学习尤其是深度学习,要做大模型和超大模型训练,要迭代数以TB级别甚至PB级别的样本,要做类似spark的checkpoint,要做动态感知计算和网络环境的调度,等等复杂负载,对文件系统的这些需求逐渐都变成了刚需。
壹
当前比较流行的分布式文件系统,包括HDFS、Ceph/CephFS、Lustre、GPFS、GlusterFS等,各具特点,并应用于一些特定的场景。作为开源项目的佼佼者,Ceph/CephFS因提供了对象存储、块存储、文件系统三种接口,得到了最为广泛的应用。常规的场景中,对象存储可以搭建企业级网盘,块存储可以作为OpenStack/KVM的镜像后端,文件存储可以替代HDFS支持大数据。 在云原生大行其道的今天,Ceph也没有落后脚步。目前已经提供了Kubernetes/Docker存储的原生支持。
贰
了解Ceph的人,大都会认为Ceph是一个相对复杂的系统,尤其当磁盘规模达到千块甚至万块时。Ceph经受住了长时间的应用考验,也说明其架构设计非常之优秀。
在OPPO的机器学习平台里,Ceph也在发挥着极其重要的作用,提供了诸如深度模型 分布式训练、 代码 和 数据共享 、 训练任务容灾 、 模型急速发布 等能力。Ceph的应用场景远不仅如此,但因为Ceph系统太过“复杂”,导致很多架构师或者技术经理不敢轻易触碰。
诚然,采纳和应用一门新技术,向来不是一个简单容易的过程,但认识或者理解一门新技术,对于我们这些混迹于IT和互联网圈的同学,可能从来都不是什么难事儿。
叁
如何快速认识Ceph/CephFS,最简单的方式就是快速应用它 。 如果想要理解它的原理,看代码便是最直接的方式。后面,我们用源码构建并运行一个小型的Ceph,全面感知下Ceph的魅力。对于了解Docker的同学,可以在容器里进行这个尝试。
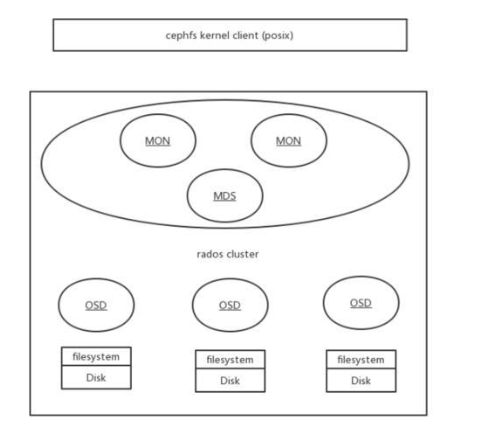
以下演示如何快速编译并启动一个 管理三块磁盘的 分布式文件系统 。图中Rados Cluster即为构造的Ceph存储集群, CephFS Kernel Client 是实现Linux VFS标准的内核模块,两者通过网络传递磁盘IO。
准备阶段
假设物理机ip为10.13.33.36,新启的容器ip为10.244.0.5
第一步: 准备好编译和运行的操作系统容器
第二步: 在容器内安装编译和运行Ceph的环境依赖库

第三步: 下载Ceph源代码并解压进入代码工程目录

第四步: 依赖准备
第五步: 编译Ceph

第六步: 启动Ceph集群并检查Ceph Cluster状态
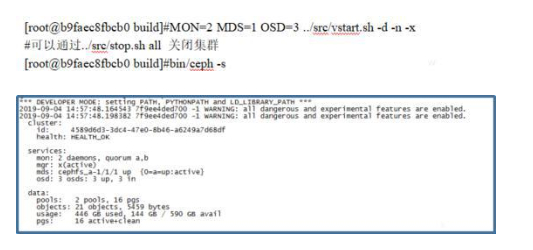
第七步:客户端挂载CephFS文件系统

第八步: 客户端检测并使用CephFS文件系统

肆
通过以上简单操作,即使是在未能熟悉mon/mds/osd服务功能,不用了解CRUSH算法原理,不懂cmake和make编译系统的情况下, 也可以快速体验到一个原生的Ceph/CephFS。
上述的Ceph集群虚拟管理了三块disk(filesystem),并通过CephFS接口暴露文件系统接口,客户端主机通过挂载该CephFS到/tmp/oppofs目录,所有读写/tmp/oppofs目录和文件的IO都会通过网络传递给Ceph Rados Cluster,并分发给三块disk。
当disk分布在多个主机时,在不同主机配置并启动相对应的OSD进程即可,每块磁盘的IO都是通过OSD进程进行管理。对Ceph性能和功能有特殊需求的场景,也可以通过直接调整源代码来定制。
Ceph本身具备的能力足以支撑起成千上万块磁盘,但因磁盘数量高速增长引来的其他相关挑战,就需要各位实践者去不断学习和积累相关的知识去应对了。 Ceph作为领先的大数据存储解决方案 , 应用场景将会越来越丰富 。
-
SDNLAB技术分享:Ceph在云英的实践2023-06-16 986
-
电源快速放电功能的简单介绍2022-11-03 6056
-
Ceph是什么?Ceph的统一存储方案简析2022-10-08 2127
-
autobuild-ceph远程部署Ceph及自动构建Ceph2022-05-05 693
-
ceph-zabbix监控Ceph集群文件系统2022-04-26 785
-
分享一个快速简单、亲测可用的freertos移值教程2022-02-18 763
-
原生的ceph-iSCSI接入方式存在性能瓶颈2021-07-01 5031
-
4种cephfs扩容方案2020-11-19 4891
-
如何才能快速的赚取比特币2019-03-11 3664
-
便携式快速充电设计就是这么简单!2017-03-29 8603
-
无线电基础快速阅读2016-04-29 818
-
如何实现电池容量的快速测量2013-06-14 3418
-
串行通讯简单认识2009-10-17 905
-
简单的快速短路保护电路图2009-04-07 10763
全部0条评论

快来发表一下你的评论吧 !
