

基于序列信息来预测潜在的抗癌多肽的深度学习方法
电子说
描述
癌症是人类健康最致命的杀手,在全球范围内每年造成数百万人的死亡。传统的物理和化学方法,包括靶向治疗、化疗和放射治疗等医疗实践中常见的治疗手段,在一定程度上能杀死病变癌细胞,但是同时也会杀死大量正常的细胞,带来严重的副作用。这些治疗手段费用昂贵且预后效果不佳,迫切需要开发新的定向清除癌细胞,治疗癌症的有效方法。
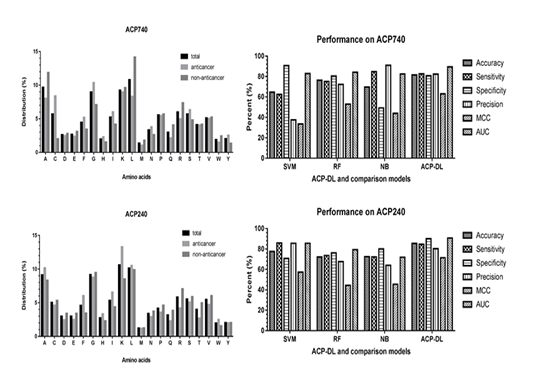
图:抗癌多肽数据集中各氨基酸组分及预测模型性能表现
抗癌多肽(anticancer peptides,ACP),一种长度通常小于50氨基酸的阳离子型多肽的发现为癌症治疗开辟了新前景。ACP多发现自抗菌多肽(antimicrobial peptides, AMP)中,具有很多优良的特性,包括高特异性、广谱性、安全性、易于合成和定制、成本低廉等。抗癌多肽可以特异性地结合癌细胞的阴离子细胞膜分子,而对正常细胞没有影响。因此,它们可以选择性地杀死癌细胞,而不带来副作用。多年来,ACP疗法在临床的不同阶段被广泛探索和应用,但是只有少数被最终用于临床治疗。ACP的鉴定高度受限于实验室,昂贵且周期漫长。计算预测的方法在帮助筛选、发现和预测抗癌多肽中的作用越来越迫切和明显。
中国科学院新疆理化技术研究所研究人员首次开发和提出了基于序列信息来预测潜在的抗癌多肽的深度学习方法。首先,研究人员基于现有的研究,整理构建了用于机器学习的抗癌多肽数据集,其中,正样本为实验验证的ACP,负样本为不具有抗癌活性的AMP。然后,保留氨基酸残基组分和位置信息的高效多肽序列特征提取技术被提出,将生物序列信息转化为数字特征。最后,基于长短时记忆模型的深度学习模型被构建和训练以预测新型ACP。严格的实验结果表明,所开发的方法具有高准确性、鲁棒性,可以作为相关生物医学研究的有效工具。
该工作以ACP-DL: A Deep Learning Long Short-Term Memory Model to Predict Anticancer Peptides Using High-Efficiency Feature Representation 为题,于近日发表于Molecular Therapy-Nucleic Acids,第一作者为新疆理化所研究生易海成,指导老师为研究员尤著宏。该工作得到国家自然科学基金优秀青年科学基金和中科院项目的支持。
-
【「时间序列与机器学习」阅读体验】时间序列的信息提取2024-08-17 958
-
【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取2024-08-14 1091
-
【《时间序列与机器学习》阅读体验】+ 了解时间序列2024-08-11 1008
-
深度学习中的无监督学习方法综述2024-07-09 3265
-
基于深度学习方法进行时序预测的调优方案2023-06-16 3475
-
使用深度学习方法对音乐流派进行分类2023-02-08 999
-
自回归滞后模型进行多变量时间序列预测案例分享2022-11-30 2898
-
做时间序列预测是否有必要用深度学习2022-03-24 2721
-
深度学习在预测和健康管理中的应用2021-07-12 1981
-
面向异质信息的网络表示学习方法综述2021-06-09 966
-
基于分层注意力的社交网络信息级联预测2021-05-29 1485
-
基于深度学习的信息级联预测方法研究综述2021-05-18 1316
-
模型驱动深度学习的标准流程与学习方法解析2018-01-24 5634
-
多示例多标记学习方法2018-01-05 831
全部0条评论

快来发表一下你的评论吧 !
