

深度学习与对象检测之人脸识别
电子说
描述
通过往期的分享,我们了解到人脸识别的大概过程,主要包括:
1、人脸图片的搜集(原始数据)
2、从图片中识别到人脸
3、人脸数据提取
4、人脸数据保存
5、从图片或者视频中检测到人脸
6、人脸数据提取
7、被识别的人脸与数据库中的数据一一对比,识别出人脸
以上人脸识别过程,存在一定的问题,当人脸原始数据比较大时,数据库中必然存在比较多的人脸数据,当进行人脸识别时,被识别的人脸与数据库中的数据对比时,必然会消耗大量的时间,对人脸实时识别的速度有较大的影响。受CNN卷积神经网络的启发,我们使用神经网络来进行人脸数据的训练,标签是人脸的名字,数据是人脸数据,使用神经网络对人脸数据进行训练,这样当数据比较大时,神经网络识别速度与正确率就越高,大大提高人脸识别的速度与正确率,这样人脸识别的过程便成为如下过程:
1、人脸图片的搜集(原始数据)
2、从图片中识别到人脸
3、人脸数据提取与保存
4、人脸数据与人脸标签的神经网络训练,保存训练模型
5、从图片或者视频中检测到人脸
6、识别到的人脸进行神经网络预测,进行人脸识别
本期介绍人脸数据的提取
1、人脸原始图片的搜集
要进行人脸识别,就要搜集用户的人脸图片,我们从网站上搜集了几个明星的照片来进行本期文章的分享。
首先在目录文件下新建一个dataset文件夹,里面放置多个文件夹,每个文件夹便是一个明星的照片,文件夹名称是明星的名字,目录类似如下:
2、设置人脸检测模型与人脸提取嵌入数据模型
人脸检测模型,我们直接使用 ResNet-10和SSD算法在caffe上面训练好的模型
人脸数据提取嵌入模型,使用OpenFace的openface_nn4.small2.v1.t7模型,此模型训练在pytorch上,可以直接使用opencv来进行加载

脸检测模型与人脸提取嵌入数据模型
3、初始化图片地址,初始化人脸数据数组与人脸名称标签数组
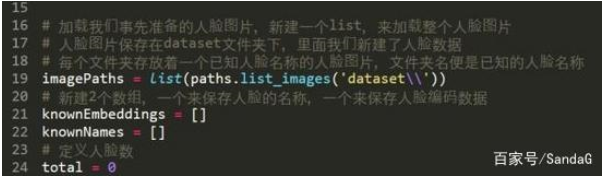
初始化人脸数据
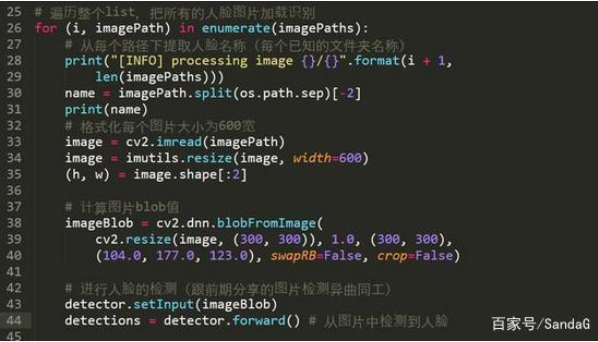
4、遍历整个dataset目录,进行图片处理
30行提取了文件夹的名称,此名称便是后期需要保存的label值
33-35行,进行了图片的读取以及resize处理
38行计算图片的blob值
43-44行,把图片的blob值放入人脸检测神经网络进行人脸的检测
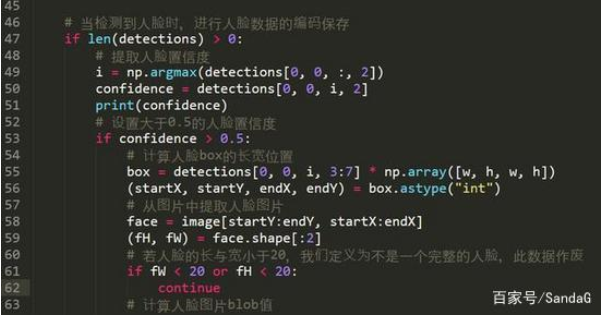
47行,当在图片中检测到 人脸时,其神经网络的len值会大于0
50行,当检测到人脸时,我们提取人脸的置信度
53行设计人脸置信度为0.5
55-59行,计算人脸在图片中的位置,并提取人脸的尺寸
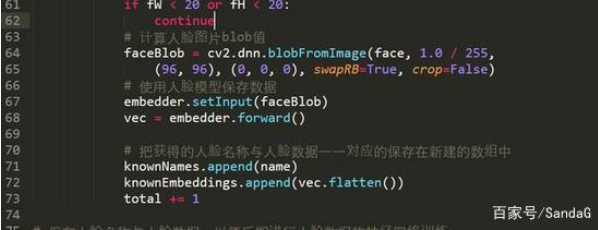
61-62行,当人脸尺寸较小时 ,我们忽略此人脸信息,选择图片中人脸比较大的人脸
64行,当人脸图片尺寸符合要求时,我们计算人脸的blob值
67-68行,把人脸图片的blob值传递人脸嵌入数据神经网络
71-72行,保存人脸的label与人脸数据到数组中
5、保存人脸数据
当遍历完成后,dataset中的所有的人脸数据便保存在了事先建立的数组中
77行,新建一个字典数据,把人脸的label以及人脸数据保存到本地,方便后期进行神经网络的训练

以上5步便完成了整个人脸的数据采集,当然,若想后期人脸识别的精度较高,需要进行大量的人脸数据搜集。
-
深度识别人脸识别在任务中为什么有很强大的建模能力2024-09-10 1628
-
基于Python的深度学习人脸识别方法2024-07-14 2564
-
人脸检测与识别的方法有哪些2024-07-03 2636
-
使用LabVIEW 实现物体识别、图像分割、文字识别、人脸识别等深度视觉2023-08-11 4804
-
人工智能知识讲解之人脸识别技术2023-06-08 3133
-
基于深度学习的快速人脸识别算法及模型2021-05-07 1547
-
基于深度学习的人脸识别算法与其网络结构2021-03-12 4583
-
LabVIEW人脸识别设计2019-04-28 6376
-
三招提高手机人脸识别的安全性2018-08-22 4876
-
人脸识别技术大火,深度学习做支撑2018-07-18 1425
-
人脸识别技术的60年发展史2018-06-20 6558
-
基于深度学习与融入梯度信息的人脸姿态分类检测_苏铁明2017-01-08 883
-
机器视觉技术应用之人脸识别2014-01-14 3322
全部0条评论

快来发表一下你的评论吧 !
