

深度学习下的AI微表情研究
电子说
描述
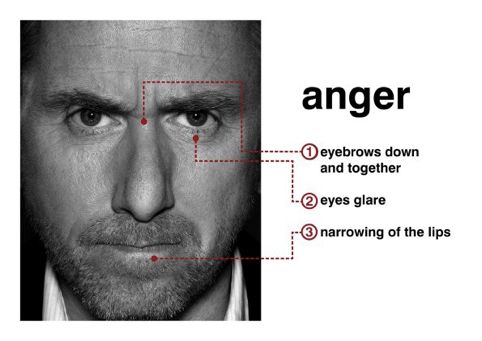
人是善于通过表情伪装情绪的动物,但心理学家却能够通过“微表情”来揭示人们试图隐藏的真实情绪。 所谓微表情,是一种持续时间极短、在人们试图掩饰自己真实情绪时泄露出来的面部动作。 如果看过美剧《Lie to Me》,应该对微表情不会陌生。男主卡尔•莱特曼是一个微表情专家,他不需要借助测谎仪之类的设备,也不需要收集各种证据,甚至不需要对话,只需要观察细微的表情变化便可以判断一个人是否说谎。 之所以能够这样,是因为人们在体验情绪时会有一系列肌肉动作不自觉地表现出来。 例如人们在愤怒时,眉毛会紧皱下垂,,眼睑和嘴唇紧张:
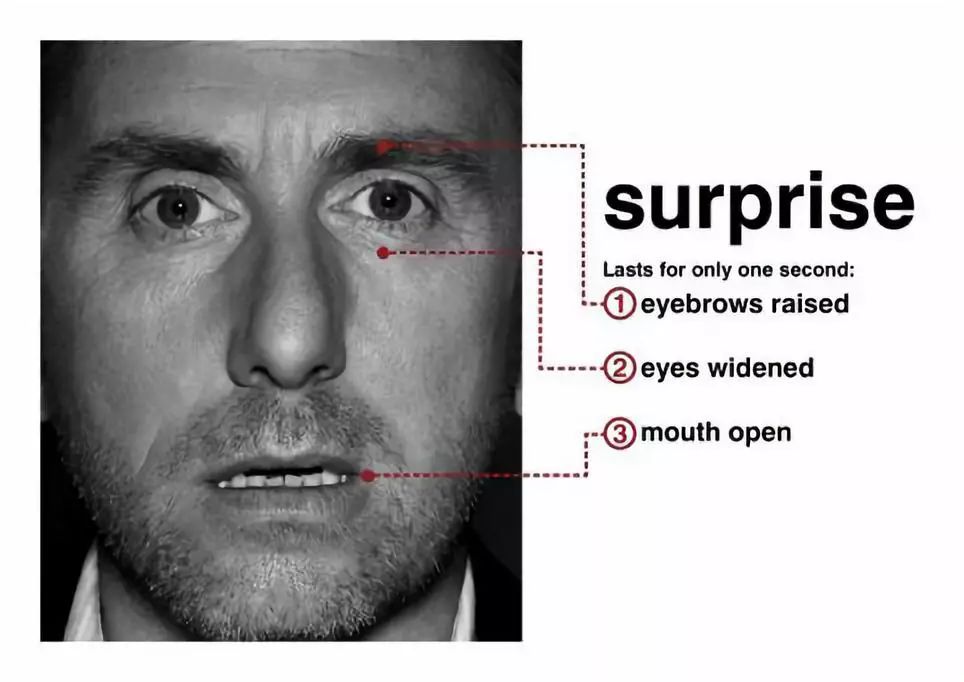
或者一个人在对事物表示惊讶时,下颚会自然下垂,嘴唇和嘴巴放松,眼睛张大,眼睑和眉毛会微微上抬:
当然,我们知道面部表情是可以受主观意识控制,例如一个人可能因其知识、阅历、能力等原因,在内心波涛汹涌的时候做到面不改色。然而,微表情是面部肌肉条件反射地表现出情绪所对应的行为。正是因为如此,微表情往往能够揭示人类试图隐藏的真实情绪。 但正如对微表情的定义,微表情持续时间短暂、变化幅度微弱和动作区域较少,很多时候人们很难注意到其存在。只有那些经过大量训练的专家才能准确地检测,而且不同的专家还往往会判断不一致。靠人工来观察微表情真的是一个耗费人力、耗费时间,而且准确度低的事情! 停! 耗费人力物力、工作机械、需要大量专家……这不正是机器学习所擅长的吗?事实上,目前已有许多学者在用机器学习的方法进行微表情研究了。
一、方法
对微表情的研究,在方法上事实上类似于人脸识别,一般包含检测和识别两个具体问题。 对于人脸识别,一般都是先进行人脸检测,然后对检测到的人脸进行识别。这个过程同样也适用于微表情识别:先从一段长视频中把发生微表情的视频片段检测出来,然后识别该微表情属于哪一类微表情。
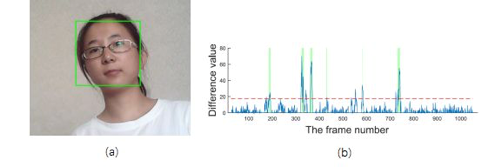
人脸检测和微表情检测 微表情检测,就是指在一段视频流中,检测出是否包含微表情,并标记微表情的起点(onset)、峰值(apex)和终点(offset)。起点(onset) 是指微表情出现的时间;峰值(apex) 是指微表情幅度最大的时间; 终点(offset) 是指微表情消失的时间。 微表情识别是指给定一个已经分割好的微表情片断,通过某种算法,识别该微表情的情绪种类(例如厌恶、悲伤、惊讶、愤怒、恐惧、快乐等)。如同三维动态表情识别一样,其处理的对象是视频片断,而不只是单幅图像。对其处理过程中,不仅要考虑空间上的模式,还要考虑时间上的模式。所以许多微表情识别的算法都考虑了时空模式。 相对于微表情检测来说,微表情识别的难度要小一点。所以对微表情的研究一般从微表情识别开始入手。 不过对微表情的检测和定位往往会更有实用价值。如果能在一段视频中准确地检测和定位到某个时间点有微表情出现,那么就说明这个人在这个时间点上可能会有异常。
二、数据集
事实上对于微表情研究,最难的是如何收集足够多的、质量高的微表情数据集。 目前微表情数据库并不多,已知的有:USF-HD数据库,Polikovsky数据库, SMIC数据库, CASME数据库, CASME II数据库,SAMM数据库,CAS(ME)2数据库。在这八个数据库中,前两个都是非自然诱发的,且非公开的。 另外5个数据集,CASME、CASME II、CAS(ME)2是中国科学院心理研究所傅小兰团队所建立,SMIC是由芬兰奥鲁大学赵国英团队建立。各个数据集的细节如下表所示:
五个公开发表的微表情数据库 需要强调的是,这些数据库的样本量都非常小,到目前为止,公开发表的微表情样本只有不到800个。是典型的小样本问题。这就造成当前基于深度学习的方法在微表情问题上无法完全发挥出它应有的威力。 事实上,微表情数据库的建立非常困难。一个原因是微表情的诱发很难,研究者往往要求被试观看情绪视频,激发他们的情绪同时要求他们伪装自己的表情。有些被试可能并没有出现微表情或者出现得很少。 另一方面,微表情的编码也十分费时费力。微表情的编码依赖于肉眼,需要观察者慢速观看视频,并且选择脸部运动的起始、高峰、结束并计算他们的时长。而且对于微表情的情绪标定,目前没有统一的标准。 微表情数据库面临的另外的问题。因为微表情的运动幅度非常小,并且相对于常规表情常常是局部的运动,导致在情绪分类上并不是很明确,所以不同数据库的情绪标定标准不一样,所以相似的运动被作为不同类的微表情而不同的运动被视作为同类的表情。这一特点导致使用各种数据库进行微表情识别算法训练得出的结果并不一致。 此外,由于微表情持续时间短、强度低且经常是局部运动,现在的许多微表情数据库视频质量并不能满足微表情识别分析的需要,这需要具有更高的时间和空间分辨率的视频片段才能进一步改进目前的识别算法。 一句话:微表情建库,重要性非常高,问题非常多,困难非常大。
三、现状
近几年来,微表情受到越来越多学者们的关注。
2009-2016年计算机科学领域中微表情论文发文量的统计(数据来自Scopus) 上图对2009-2016年计算机科学领域中微表情论文发文量进行了统计。可以看出,近三年来,有关微表情论文的发文量在急剧增长。2009-2016年一共发文81篇,其中2016年就发文30篇,占总数37%。特别是2013年两个微表情数据库(CASME和SMIC)公开发布以后,微表情相关的论文发文量逐年递增。 目前,国外做的较好的以芬兰奥鲁大学赵国英团队为主,他们为微表情识别提出了一个系统的框架,并且公开以布了一个微表情数据库SMIC。其他包括马来西亚Multimedia大学的John See团队、英国曼彻斯特都会大学的Moi Hoon Yap团队、美国南佛罗里达大学的Shreve、日本筑波大学的Polikovsky和日本早稻田大学Yao等。 而国内做微表情检测和识别的科研机构主要有中国科学院心理研究所傅小兰团队,前面提到的三个数据库都是他们建立的。其次还有东南大学郑文明团队、山东大学贲晛烨团队、复旦大学张军平团队、清华大学刘永进团队、中山大学的郑伟诗团队等。可以看出,国内在这方面有相对较多的研究队伍。 从微表情论文发文数量可以看出,微表情检测和识别的研究属于一个小众的研究。其限制的主要原因在于大规模、高质量、公开的数据资源的稀缺。所以,用机器学习方法做微表情研究,面临的一个重要的问题便是:如何建立大规模、高质量的数据库资源。这面临着从硬件,到软件,到标准的一系列严峻挑战。
-
AI大模型与深度学习的关系2024-10-23 4402
-
深度解析深度学习下的语义SLAM2024-04-23 2410
-
微表情识别-深度学习探索情感2023-08-14 4342
-
什么是深度学习?使用FPGA进行深度学习的好处?2023-02-17 2198
-
AI在汽车中的应用:实用深度学习2022-11-01 731
-
射频系统的深度学习【回映分享】2022-01-05 6566
-
深度学习模型是如何创建的?2021-10-27 2415
-
基于深度学习的异常检测的研究方法2021-07-12 1787
-
基于信息增量特征选择的微表情识别2021-06-28 804
-
人工智能AI-卷积神经网络LabVIEW之Yolov3+tensorflow深度学习有用吗?2020-11-27 4472
-
【瑞芯微RK1808计算棒试用申请】基于机器学习的视觉机械臂研究与设计2019-09-23 1595
-
【技术杂谈】用AI读懂人心?情感科学专家:靠表情识别情绪不靠谱2019-07-30 2472
-
AI为表情包生成搞笑文字说明2018-07-31 9479
-
善用“微表情”打动面试官2013-01-02 2283
全部0条评论

快来发表一下你的评论吧 !
