

如何在统计软件R中进行方差分析测试
电子说
描述
步骤1:入门:
如果您的计算机上尚未存在R,则可以从官方网站免费下载位于:
http://cran.r-project.org/bin/windows/base/(Windows)
http://cran.r-project.org/bin/macosx/(Mac)
http://cran.r-project.org/(Linux)
选择该版本的(32bit/64bit)版本操作系统的自然基础。
打开R:
您将看到基本命令建议已打开。这是已执行命令的日志和输出。但是,无法对其进行编辑,使其难以使用,而是使用以下命令打开脚本窗口:
文件》》
新脚本
此窗口充当基本的文字处理器(靠近记事本),可以通过右键单击一行或所选内容并运行它来编写,编辑和执行命令。或者,快捷键Control + r也将执行一行或选择。
注意:
您可以通过在注释的开头加上井号(#)来在R中编写注释。步骤3中显示了一个示例。
步骤2:读取数据:
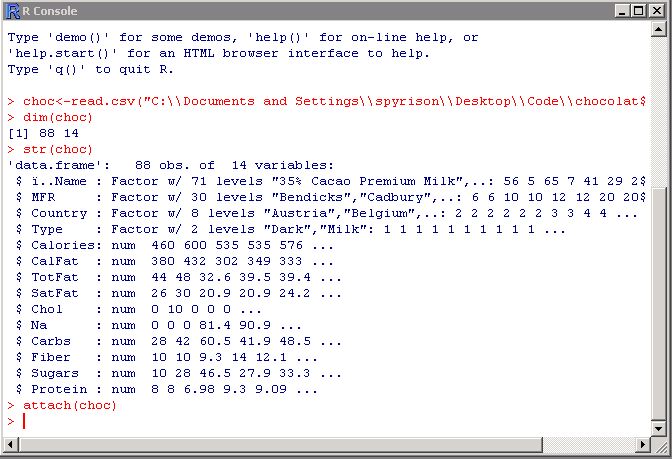
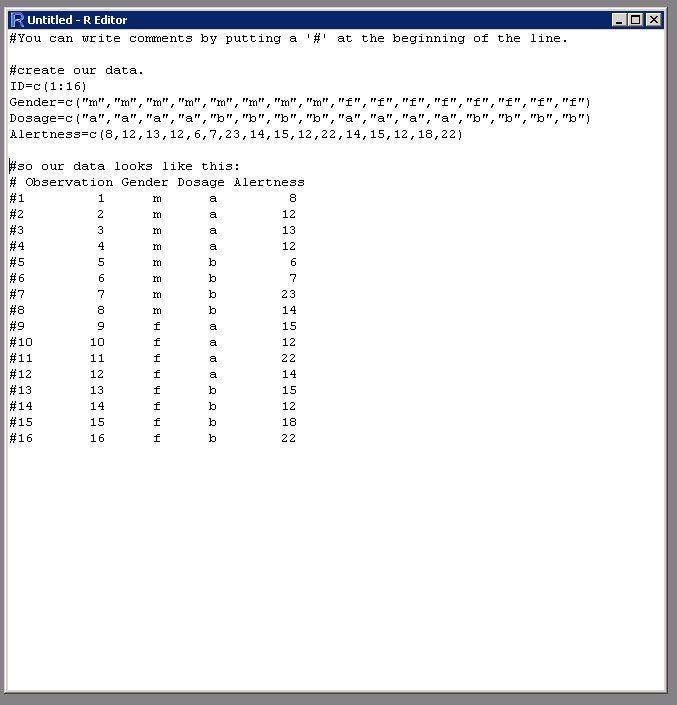
.csv也许是最流行的文件处理数据文件时键入。 .csv文件可以从excel轻松制作。或者,您可以通过命名和指向变量将数据直接输入R中(请参见辅助映像)。如果您有.csv文件,那就太好了!使用以下命令之一读取它:
数据名称= read.csv(“适当的网页或文件目录”)
数据名称= read.csv(file.choose( ))
完成此操作之后,请使用以下命令浏览数据:
dim(数据名称)
str(数据名称)
头(数据名称)
附加(数据名称)
注意:
您将需要运行附加,否则需要R不会知道您要指的是什么数据集。
第3步:运行ANOVA测试:


您做的很棒!您已经接近完成一个独立变量ANOVA测试。
使用以下R命令运行方差分析:
name = aov(y variable〜x variable)#运行ANOVA测试。 》 ls(name)#列出测试存储的项目。
summary(name)#给出基本的方差分析输出。
图像中的示例将卡路里作为因变量y与一个自变量进行比较(在此示例中为糖)。
注意:
如果R找不到指定的变量,请确保标点符号匹配并且您已经执行了‘attach(data)’命令。
步骤4:然后是一个自变量
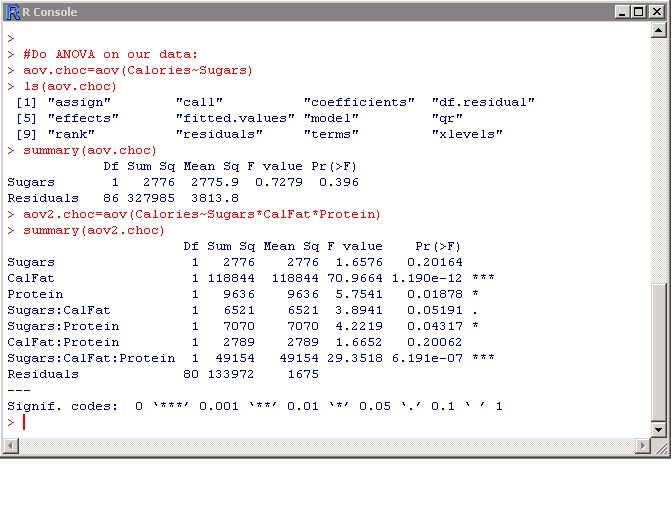
具有多个自变量x1,x2到xn的情况是一个简单的变化。 br》修改代码,使自变量成为在它们之间带有星号(*)的乘积:
name = aov(y〜x1 * x2 * xn)
步骤5:解释数据:
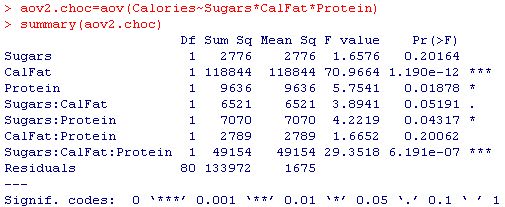
让我们从中获取多元模型第4步。在这里,我们尝试用糖,卡路里,脂肪,蛋白质以及它们彼此之间的相互作用(糖* CalFat,糖*蛋白质,CalFat *蛋白质和糖* CalFat *蛋白质)来描述卡路里。
焦点在列上:F大于上一列列出的值的概率。这通常称为 p值。在大多数情况下,您将重要性置于alpha = .05级别,或者我们要求P值小于.05 才被视为具有统计意义。
立即我们可以看到,术语Sugars ,Sugars * CalFat和CalFat * Protein在.05级别上不显着。或者,我们看到CalFat和Sugars * CalFat * Protein分别是最佳术语,P值远小于.05。
由此我们可以得出结论,如果您的目标是描述卡路里,则只需对CalFat进行回归或潜在的糖* CalFat *蛋白质。如果您打算采集更多样本,而您只关心它的预测或描述卡路里,那么您现在只需要从Fat中收集卡路里,而不必收集所有其他变量。
责任编辑:wv
- 相关推荐
- 热点推荐
- 软件
-
LABVIEW 怎么实现Allan方差分析?2025-09-03 5710
-
方差分析原理和术语2019-09-03 1423
-
如何对无线信号进行测试?2021-06-01 1809
-
统计函数中的标准偏差,均方根和方差的计算2021-08-11 1855
-
讲解统计函数中的标准偏差,均方根和方差的计算2021-08-17 1740
-
如何在主机端进行嵌入式软件测试呢2021-12-24 1331
-
如何在STM32CubeMX中进行串口通信的配置?2022-02-18 1591
-
如何在android中进行驱动呢2022-03-02 979
-
方差分析2010-10-02 902
-
算法大全_方差分析2016-01-14 720
-
在NI VeriStand环境中进行FPGA相关配置2017-11-18 5681
-
捷联惯导系统中Allan方差的使用要点 分析2018-10-30 2753
-
如何在LTspice中进行蒙特卡罗分析?2023-05-05 5384
-
Allan 方差理论及测量方法2024-06-07 4545
-
Minitab常用功能介绍 如何在 Minitab 中进行回归分析2024-12-02 5744
全部0条评论

快来发表一下你的评论吧 !
