

可编辑神经网络有什么积极意义
人工智能
描述
深度学习是一个计算繁重的过程。 降低成本一直是 Data curation 的一大挑战。 关于深度学习神经网络大功耗的训练过程,已经有研究人员发表了其碳足迹(温室气体排放集合)的报告。
情况只会越来越复杂,因为我们正迎来一个充斥着大量的机器学习应用程序的未来。但所幸的是,我们也看到一些能够让训练神经网络的过程变得更高效的策略正在被发明出来。
以更改单个输入来更新神经网络的预测可能会降低其他输入的性能。 当前,业内通常使用两种解决方法:
1、在原始数据集上重新训练模型,并补充解决错误的样本;
2、使用手动缓存(例如查找表)来代替对有问题的样本的模型预测;
虽然简单,但是这种方法对于输入中的细微变化并不稳健。 例如,在自然语言处理任务中,它不会概括出同一对象的不同观点或释义。 因此,在ICLR 2020的一篇正在审核的论文中,尚未公开姓名的作者提出了一种称为“可编辑训练”的替代方法。
神经网络的“修补”
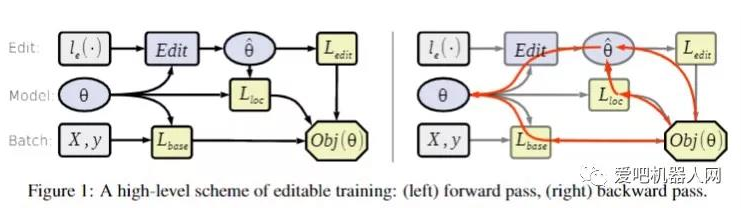
可编辑神经网络也属于元学习范例,因为它们基本上是“学习允许有效修补”。
有效的神经网络修补问题不同于持续学习,因为研究人员认为,可编辑的训练设置本质上不是顺序的。
在这种情况下进行编辑意味着在不影响其他输入的情况下,更改输入对子集的模型预测(与错误分类的对象相对应)。
为此,构想出了编辑器功能,即一种给定约束的参数功能。 换句话说,非正式地,这是一个调整参数以满足给定约束的函数,该约束的作用是强制执行模型行为所需的更改。
对于图像分类实验,使用标准训练/测试分割获取小的CIFAR-10数据集。训练数据集进一步增加了随机裁剪和随机水平翻转。
在此数据集上训练的所有模型都遵循ResNet-18架构,并使用具有默认超参数的Adam优化器。
为深度神经网络实现Edit的自然方法是使用梯度下降。 根据作者的观点,标准的梯度下降编辑器可以用动量(momentum)、自适应学习率(adaptive learning rates)进一步增强。
但是,在许多实际情况下,绝大部分这些编辑都不会发生。 例如,比起“卡车”或“船”,以前被分类为“飞机”的图像更有可能需要编辑为“鸟”。 为了解决这个问题,作者采用了自然对抗样本(NAE)数据集。
该数据集包含7500个自然图像,这些图像很难用神经网络进行分类。 如果不进行编辑,经过预训练的模型可以正确地预测NAE中不到1%的数据,但是正确的答案可能在按预测概率排序的前100个类别中。
总结
可编辑训练与对抗训练有些相似,后者是对抗攻击防御的主要方法。 这里的重要区别在于,可编辑训练旨在学习模型,可以有效地纠正某些样本上的行为。
同时,对抗训练会产生对某些输入扰动具有鲁棒性的模型。 但人们可以使用可编辑训练来针对合成和自然对抗示例有效地覆盖模型漏洞。
在许多深度学习应用程序中,单个模型错误可能导致毁灭性的财务、名誉乃至生命危险。 因此,至关重要的是要尽快纠正出现的模型错误。
可编辑训练,一种与模型无关的训练技术,可鼓励对训练后的模型进行快速编辑,并且这种方法的有效性对于大规模图像分类和机器翻译任务也很有希望。
来源:爱吧机器人网
-
神经网络架构有哪些2024-07-01 2791
-
卷积神经网络模型有哪些?卷积神经网络包括哪几层内容?2023-08-21 3131
-
卷积神经网络模型发展及应用2022-08-02 13373
-
神经网络移植到STM32的方法2022-01-11 3263
-
基于BP神经网络的PID控制2021-09-07 2729
-
如何构建神经网络?2021-07-12 2007
-
如何设计BP神经网络图像压缩算法?2019-08-08 3986
-
人工神经网络实现方法有哪些?2019-08-01 3517
-
【案例分享】ART神经网络与SOM神经网络2019-07-21 3308
-
卷积神经网络如何使用2019-07-17 2877
-
全连接神经网络和卷积神经网络有什么区别2019-06-06 6016
-
labview BP神经网络的实现2017-02-22 14457
-
神经网络教程(李亚非)2012-03-20 58158
-
人工神经网络,人工神经网络是什么意思2010-03-06 3618
全部0条评论

快来发表一下你的评论吧 !
