

什么是拜占庭容错技术
区块链
描述
共识算法是区块链技术的核心要素,也是近年来分布式系统研究的热点。
一、前言
众所周知,区块链架构是一种分布式的架构。其部署模式有公共链、联盟链、私有链三种,对应的是去中心化分布式系统、部分去中心化分布式系统和弱中心分布式系统。
分布式系统中,多个主机通过异步通信方式组成网络集群。在这样的一个异步系统中,需要主机之间进行状态复制,以保证每个主机达成一致的状态共识。然而,异步系统中,可能出现无法通信的故障主机,而主机的性能可能下降,网络可能拥塞,这些可能导致错误信息在系统内传播。因此需要在默认不可靠的异步网络中定义容错协议,以确保各主机达成安全可靠的状态共识。
共识理解起来很简单,就是大家都达成一致的意思。在现实生活中,有很多达成共识的场景。比如我们开会讨论,需要得出一个结果;双方或多方签订一份合作协议时;又或者是哈士奇……呃,不好意思,跑远了。
而在区块链系统中,每个节点必须要做的事情就是让自己的账本跟其他节点的账本保持一致。如果是在传统的软件结构中,这根本不算事儿,因为有一个中心服务器,就像是一个公司老板发布一个通知,员工就照着做一样。可是区块链是一个分布式的对等网络结构,在这个结构中没有哪个节点是“老大”,什么事儿都得一起商量。
所以在区块链系统中,如何让每个节点通过一个规则将各自的数据保持一致是一个很关键的问题,这个问题的解决方案就是制定一套共识算法,实现不同账本节点上的账本数据的一致性和正确性。这就需要借鉴已有的在分布式系统中实现状态共识的算法,确定网络中选择记账节点的机制,以及如何保障账本数据在全网中形成正确、一致的共识。
在20世纪80年代出现的分布式系统共识算法,是区块链共识算法的基础。下面我们就从基本的拜占庭容错技术入手,往后逐步介绍适合于私有链/联盟链和公共链的共识算法。
二、拜占庭容错技术
拜占庭容错技术(Byzantine Fault Tolerance, BFT)是一类分布式计算领域的容错技术。拜占庭假设是对现实世界的模型化,由于硬件错误、网络拥塞或中断以及遭到恶意攻击等原因,计算机和网络可能出现不可预料的行为。拜占庭容错技术被设计用来处理这些异常行为,并满足所要解决的问题的规范要求。
1、拜占庭将军问题
拜占庭容错技术来源于拜占庭将军问题(点此了解:https://ethfans.org/tinyxiong/articles/874)。拜占庭将军问题(Byzantine Generals Problem),是由莱斯利·兰波特在其同名论文中提出的分布式对等网络通信容错问题。
这里我们给出分布式计算机中有关拜占庭缺陷和故障的两个定义:
定义1:拜占庭缺陷(Byzantine Fault):
任何观察者从不同角度看,表现出不同症状的缺陷。
定义2:拜占庭故障(Byzantine Failure):
在需要共识的系统中由于拜占庭缺陷导致丧失系统服务。
不是所有的缺陷或故障都能称作拜占庭缺陷或故障,比如死机、丢消息这样的。在分布式系统中,特别是在区块链网络环境中,也和拜占庭将军的环境类似,有运行正常的服务器(类似忠诚的拜占庭将军),还有破坏者或者中木马的服务器(类似叛变的拜占庭将军)。共识算法的核心是在正常的节点间形成对网络状态的共识。
2、拜占庭容错系统
通常,发生故障节点被称为拜占庭节点,而正常的节点即为非拜占庭节点。
拜占庭容错系统是一个拥有n 台节点的系统,整个系统对于每一个请求,满足以下条件:
1)所有非拜占庭节点使用相同的输入信息,产生同样的结果;
2)如果输入的信息正确,那么所有非拜占庭节点必须接收这个信息,并计算相应的结果。
拜占庭系统普遍采用的假设条件包括:
1)拜占庭节点的行为可以是任意的,拜占庭节点之间可以共谋;
2)节点之间的错误是不相关的;
3)节点之间通过异步网络连接,网络中的消息可能丢失、乱序并延时到达,但大部分协议假设消息在有限的时间里能传达到目的地;
4)服务器之间传递的信息,第三方可以嗅探到,但是不能篡改、伪造信息的内容和验证信息的完整性。
3、实用拜占庭容错系统
实用拜占庭容错系统(Practical Byzantine Fault Tolerance, PBFT),降低了拜占庭协议的运行复杂度,从指数级别降低到多项式级别(Polynomial),使拜占庭协议在分布式系统中应用成为可能。
PBFT是一类状态机拜占庭系统,要求共同维护一个状态,所有节点采取的行动一致。为此,需要运行三类基本协议,包括一致性协议、检查点协议和视图更换协议。我们主要关注支持系统日常运行的一致性协议。
一致性协议至少包含若干个阶段:请求(request)、序号分配(pre-prepare)和响应(reply)。根据协议设计的不同,可能包含相互交互(prepare),序号确认(commit)等阶段。
这个协议把服务器节点分为两类:主节点和从节点,主节点只有一个。
PBFT的一致性协议如下图所示。
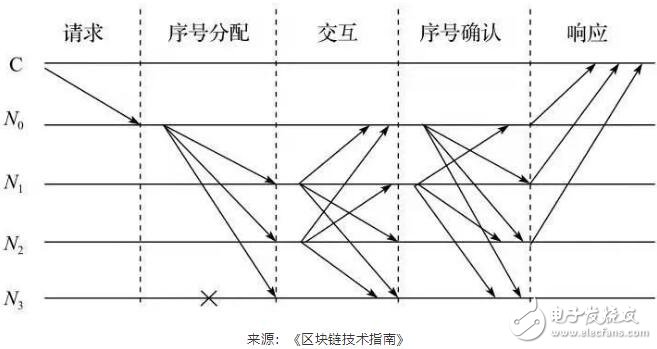
为了描述方便,PBFT系统通常假设故障节点数为m个,而整个服务节点数为3m+1个。每一个客户端的请求需要经过5个阶段,通过采用两次两两交互的方式在服务器达成一致之后再执行客户端的请求。由于客户端不能从服务器端获得任何服务器运行状态的信息,PBFT中主节点是否发生错误只能由服务器监测。如果服务器在一段时间内都不能完成客户端的请求,则会触发视图更换协议。
上图显示了一个简化的PBFT的协议通信模式,其中C为客户端,N0~N3表示服务节点,特别的,N0为主节点,N3为故障节点。整个协议的基本过程如下。
1)客户端发送请求,激活主节点的服务操作。
2)当主节点接收请求后,启动三阶段的协议以向各从节点广播请求。
[2.1]序号分配阶段,主节点给请求赋值一个序列号n,广播序号分配消息和客户端的请求消息m,并将构造PRE-PREPARE消息给各从节点;
[2.2]交互阶段,从节点接收PRE-PREPARE消息,向其他服务节点广播PREPARE消息;
[2.3]序号确认阶段,各节点对视图内的请求和次序进行验证后,广播COMMIT消息,执行收到的客户端的请求并给客户端以响应。
3)客户端等待来自不同节点的响应,若有m+1个响应相同,则该响应即为运算的结果。
PBFT在很多场景都有应用,在区块链场景中,一般适合于对强一致性有要求的私有链和联盟链场景。例如,在IBM主导的区块链超级账本项目中,PBFT是一个可选的共识协议。
来源: pixabay
-
容错技术在电视台播控系统中应用的探讨2009-10-06 2387
-
什么是三模冗余容错技术?2019-10-12 9454
-
容错系统中的自校验技术及实现方法2009-03-28 1151
-
双机容错的容错方式/支持平台2009-12-29 657
-
面向服务计算的拜占庭容错协议2017-12-23 923
-
拜占庭将军问题与区块链?一毛钱关系?2018-09-17 611
-
区块链中的拜占庭容错2018-09-29 1834
-
哈希图一致性算法已被验证为异步拜占庭容错2018-10-23 2146
-
区块链能否解决拜占庭将军的问题2019-02-26 2142
-
区块链领域拜占庭容错的正确理解2019-04-15 2039
-
区块链的解决方案是如何解决拜占庭将军问题的2019-05-29 7184
-
拜占庭容错的基本概念及实现方法解析2019-07-31 9690
-
区块链系统中拜占庭容错PBFT工作的实现原理解析2019-08-08 4178
-
拜占庭将军问题和比特币之间有关系吗2019-10-22 1011
-
一种基于信任度的匹配拜占庭共识算法2021-04-14 1222
全部0条评论

快来发表一下你的评论吧 !
