

如何对IAR单片机编程软件进行编译优化
控制/MCU
描述
单片机编程软件是单片机开发不可缺少的工具之一,目前市场流通的单片机编程软件主要为IAR单片机编程软件和KEIL单片机编程软件。
一、编译优化选项
在iar中可以设置代码的编译优化等级,在工程名上右键选Options.。.,在弹框中选C/C++ Compiler--Optimizations,如下图所示。
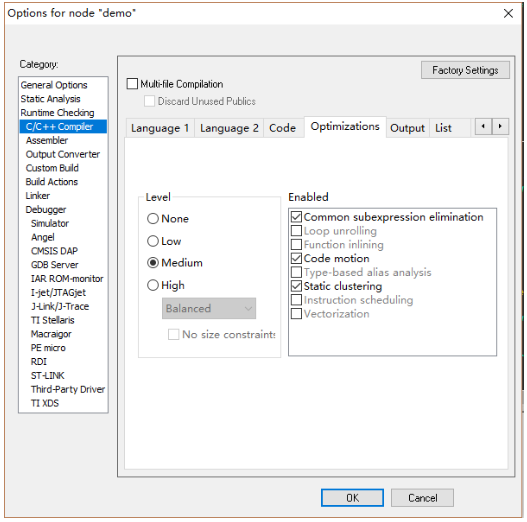
左边的level里面是优化等级,右边的是附加选项。如果不想往下看了又有bug体质,就把这里的level选到None上面,点击OK。
二、优化还是不优化
优化的目的简单来说主要有两个,减少代码量和提高程序运行效率。随之而来的是什么呢?如果编译器误认为你写的延时是“低效率”代码,如果编译器认为某些变量的生命周期可以提前结束了,如果编译器认为某些变量你定义了没有使用就是没用,就会原地爆炸了。
所以还是有必要搞明白,优化到底优化了什么,才能决定要不要优化。
三、IAR优化了什么
1.None
有最好的debug支持,变量的生命周期会贯穿它的整个作用域,也就是说编译器不做任何优化,只要是变量的作用域,这个变量就是有效的。
最直观的的体现就是可以在live watch中查看该变量,如果它被优化了,就查看不了了。
2.Low
仍然是具备调试支持的,优化的是变量的生命周期,如果一个变量没有作用了,后面不会用到它了,就会把它优化掉,不让它贯穿它的整个生命周期。
这有什么好处呢?这个变量不存在了,就意味着寄存器的压力减小了很多,可以腾出更多空间给更有需要的变量。
3.Medium
除了上述优化以外,还加入了很多新的优化。
· Live-dead analysis and optimization
代码是否可用的分析和优化
· Dead code elimination
无用的代码清除。
· Redundant label elimination
冗余标签消除
· Redundant branch elimination
冗余分支清除,所以可能出现由于对变量和分支的共同优化,导致某些条件分支明明成立却始终不会进入,一个大坑。
· Code hoisting
代码提升,很难理解的名字,其实就是它字面意思,就是把某些代码(变量定义)提到作用域的顶部去,可笑的是定义的顺序不变。也就是说,你定义了全局变量a=1,然后在某个函数里输出a,在下面定义局部变量a=2,最后输出的结果是乱码或者0,这取决于局部变量的默认初始化的值。在函数里真正被输出的,不是全局变量的a,而是局部变量的a,但是这个a只做了定义,初始化还在原位置。
· Peephole optimization
窥孔优化,通俗点说是局部优化,编译器对部分编译的代码,结合目标CPU的指令特点,做一些认为可以提高性能的优化。
· Some register content analysis and optimization
寄存器内容分析与优化
· Static clustering
静态聚类。将在同一模块内定义的静态变量和全局变量布置成使得在相同函数中访问的变量彼此紧密地存储。这使得编译器可以为多个访问使用相同的基指针。
· Common subexpression elimination
公共子表达式消去,在编程中会有很多地方使用相似的表达式,比如:
a=b+c+d;
e=b+c+f;
这个时候可以优化成这样:
tem=b+c;
a=tem+d;
e=tem+f;
4.High
最高程度的优化。具备以上所有的优化之外,还有:
· Instruction scheduling
指令调度,编译器根据自己的指令调度器去重新安排指令,使得处理器运行时出现的资源冲突情况更少,从而减少资源冲突引起的卡顿情况。
· Cross jumping
交叉跳跃
· Advanced register content analysis and optimization
高级寄存器内容分析与优化
· Loop unrolling
循环展开。有一些小的循环体,在编译时就能确定其循环次数,编译器会启发式得试探是否将这个循环体复制展开,展开循环体能减少程序的迭代次数,从而加快程序的运行速度,但会增加代码的大小。
编译器会从速度和代码大小之间去找一个平衡点,优化速度和优化代码大小那个配置就会影响这个优化。
· Function inlining
函数内联
如果一个比较小的函数在编译时已经能确定其准确的定义了,编译器会决定将其内联到调用者的内部,这样就会减小函数调用的开销。
· Code motion
代码移动。对循环不变的表达式和公共子表达式进行移动,避免其被再次评估。这个优化会减小程序代码体积,加快执行速度。
· Type-based alias analysis
基于类型的别名分析。多个指针指向同一块内存,可以互相称之为内存的别名,因为这种情况会导致优化变得很困难,因为编译的时候不知道内存是否存在。所以编译器采用假设按照定义的类型分配了内存去编译优化。
说明:上面有些优化,可以在iar中配置是否要使用。
高级别的优化选项回增加代码编译的时间,并且会在调试的时候出现一些困难,比如有时候想在某个位置打断点却发现打不上,因为那里的代码已经被优化掉了,有时候想看某些变量的值,却发现live watch显示这个变量无法查看,也是被优化掉了。
责任编辑;zl
-
单片机编程软件有哪些2022-09-23 18934
-
讲解IAR单片机编程软件的工程调试使用方法2022-01-27 2746
-
IAR单片机编程软件的使用方法2022-01-13 1768
-
VS2019调试查看变量_单片机编程软件一点通,IAR单片机编程软件工程调试方法2021-12-03 1102
-
iar stm32_吃透单片机编程软件,IAR单片机编程软件创建stm32工程2021-11-30 1557
-
STC单片机编程软件安装教程2021-11-13 1802
-
PIC单片机如何进行编程2020-06-29 7123
-
IAR单片机编程软件建立stm32工程的方法解析2020-03-06 3243
-
如何正确的设置IAR单片机编程软件2019-10-31 6317
-
IAR单片机新建软件工程的详细步骤解析2019-09-04 6818
-
STM8单片机如何进行IAR工程的建立2019-05-10 1707
-
PIC系列单片机WINDOWS版反编译软件2010-04-14 563
-
8051系列单片机反编译软件.rar2010-04-13 609
-
8051系列单片机反编译软件(工具)2009-10-12 1890
全部0条评论

快来发表一下你的评论吧 !
