

如何基于FPGA来构造高性能的图像处理解决方案
描述
FPGA与CPU相比进一步强化了算力,尤其适合各类并行化计算;而与GPU相比,其更细粒度及灵活的并行化及流水线控制天然的对复杂算法有更强的适应性,能够充分发挥出算力优势,从而带来计算效率的提升。针对数据中心算力不断增强,算法不断细分、复杂化的大背景下,FPGA具有更好的发展前景。
大家好,我是深维科技创始人/CEO 樊平,非常高兴有这个机会跟大家分享和交流一下,如何基于FPGA来构造高性能的图像处理解决方案。
1.解决方案提出的背景

随着需求的快速增长,目前数据中心需要处理的图像越来越多,处理内容包括图像转码,像素级的操作、缩略图处理以及各种图像的智能分析,这些处理需求带给数据中心的负担日益加重。
2. FPGA图像处理加速的潜力
2.1 深维科技在图像方案上的性能数据

上图是深维科技目前在图像方案上已经做到的性能数据,第一是图像的吞吐(每秒可以处理图片的数量),目前CPU是根据E5的2650双U服务器的性能去比较,加一张FPGA优良版的加速卡就可以做到20倍的吞吐。在业务流程里对延时相对都很敏感,深维可以在提升吞吐的同时降低延迟达5倍,数据中心的成本因为服务器成本和所有功耗成本的降低,使得整体的TCO的降低可以达到5倍以上,也就是降低到原来的20%以下。同时可以改善功耗,提高10倍能效比。这些性能都是通过深维科技一款名叫ThunderImage的产品为大家提供的。
2.2 ThunderImage介绍
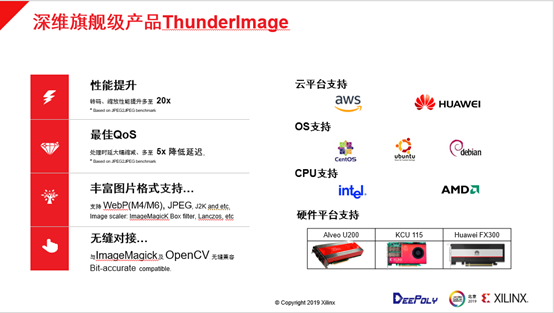
除了刚才提到的性能,深维科技对丰富的图片的格式进行了支持,例如JPEG图片编解码的处理。随着目前高清图片内容越来越多,大家需要对图片的尺寸/压缩率做进一步提升,这其中比较流行的一种格式是Google从VP8编码提取出来的一套标准WebP。深维科技目前很好支持了WebP的M4和M6两种模式,另外深维科技也支持其他图片格式和一些图片的缩放算法,像Lanczos这类比较复杂的滤波算法都可以支持。
用户在数据中心进行方案集成过程中,传统数据中心的设计环境是软件,把FPGA导入到数据中心之后,对方案的可用性有非常高的要求。深维科技把整个方案做了很好的封装,以ImageMagick和OpenCV标准开源框架为接口进行替换,用户只需要改动几行代码之后就可以对接口完成替换。这样的使用模式完全类似于软件的形态,并且可以做到无缝兼容,包括一些像VIPS这类型的新框架深维科技都在逐步支持。
在业务部署的过程当中,深维科技从客户得到很多关于细节的反馈,其中一个常见的问题是图片在业务流程里部署时,客户发现硬件的编解码往往和参考软件的结果存在不一致的现象,这是由于硬件做加速过程当中,为了适应加速的效果会对算法进行改动。
现在这款ThunderImage方案可以做到硬件编解码和参考软件结果完全一致的,每个比特的结果和CPU的流程跑出来的结果都可以做到严格一致,对实际业务的评估部署阻力会降低很多。ThunderImage方案可以做到每个像素都一样,因此满足了实际业务的场景需求。
深维科技的整个产品都可以部署在两种平台上,一种是云平台,例如AWS和华为云,其他云平台也会陆续发布出来。另一种是线下部署,深维科技在线下的本地部署支持了Linux的不同版本,可以比较方便匹配客户不同的生产环境配置,服务器也可以支持英特尔和AMD两款CPU的型号。目前硬件平台可以支持Alveo U200、Huawei FX300以及一些早期的型号,根据客户的场景可以比较快地适配到相应的板卡。
3.常见的业务场景
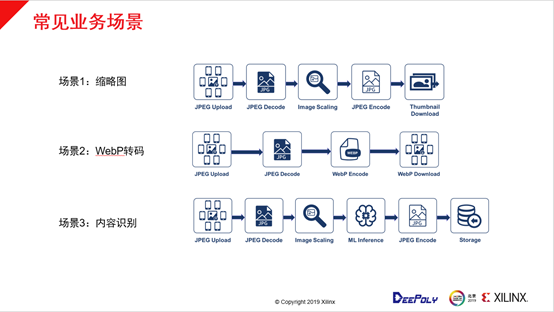
涉及图片部分的产品有几个典型的应用场景,第一是缩略图的场景,整个流程包括图片的上传、JPEG解码、缩放、JPEG编码和推送客户端,很好的适配了以下几种典型场景:第一是手机的云相册,客户上传大量的图片到云端,在不同的终端上浏览上传的图片,在浏览时不需要把原图转成各种尺寸的图像推送到客户端,只需要在线算出不同的尺寸推送到客户端,在电商平台和社交网络上都大量涉及到这样的应用场景。
第二个场景是WebP转码,把JPEG格式转成WebP格式,达到节省30%以上的带宽或者存储的目标。另外深维也支持配合类似AI Inference的任务,在AI Inference Engine上输入图像尺寸大部分都是小图,小图通常是CPU端去配合生成(预处理),在Inference之后还要有一些存档和编码的需求。目前方案很好地适配了预处理和后处理的场景,可以实现整个AI Inference的全流程加速。
4.生产环境集成
4.1 与OBS进行集成
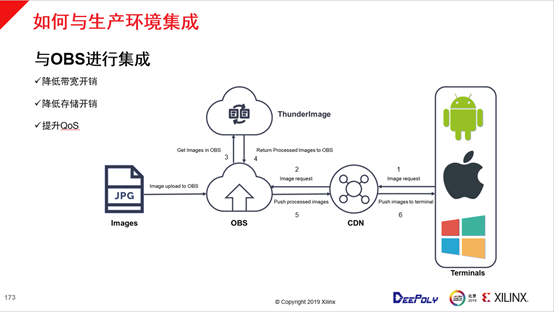
关于如何与生产环境集成,深维科技与OBS有一个比较完整的方案,首先上图是一个典型的场景,需要有大量的JPEG图像上传到OBS,上传完之后的OBS包含了大量用户图片。第二个阶段是用户会从安卓、苹果、Windows等不同的终端去发起一个访问,这个访问会发向CDN,由于大部分情况下本地各种终端之间存在差异,访问的命中率会比较低,CDN会检查并返回给OBS进一步请求图片。请求之后OBS会调用ThunderImage以最高的性能反馈给OBS相应尺寸的图片,最后推送到客户端,与OBS这种常见生长环境集成的模式还是比较清晰的。
4.2 核心性能指标分析
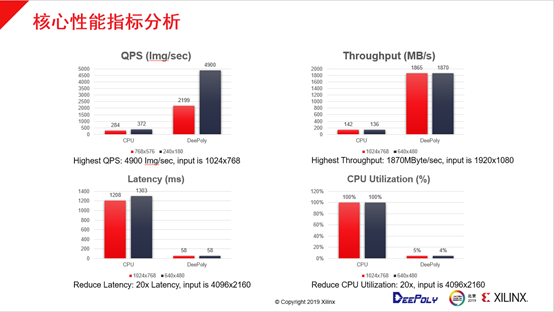
如图是性能指标的分析,第一个是QPS(每秒可以处理图片的张数),这个核心指标是在1K图片缩放到240×180的时候可以达到4900张的峰值,4900是目前深维科技在同类产品里所能看到的最好效果。另一个数字是吞吐(每秒按照能处理输入图像流量的大小),吞吐可以达到1.8GB,相应此时CPU的流量是136MB,大概有15倍左右的加速。另外在延迟方面,在4K转640×480图片尺寸的时候,ThunderImage可以做到58毫秒,此时CPU延迟已经达到1303毫秒,之间存在20倍左右的差距。在FPGA进行加速时,也就是将FPGA插到一个服务器里,服务器可以在性能有20倍的提升的同时做到CPU的利用率只有4%,纯CPU版本是100%,因此整体加速效果是一致的,ThunderImage在各方面都有接近20倍的性能提升,有些方面性能提升还要更高一些。
4.3 通用计算方案

FPGA加速效果在图片处理方案上是非常明显的,在FPGA计算加速方向上已经有各类方案,包括GPU、CPU、FPGA和ASIC。方案的比较在整体上有两个重要的约束:效率(追求性能)和灵活性。FPGA相对于GPU的底层有更细粒度的并行化和流水线的控制,能够做比特级、任意数据不对齐的操作,所有这些灵活性和底层更细粒度控制带来了更好的计算效率,相对于整体就会带来低延时、更高的能效和性能,所以深维非常看好FPGA将会成为下一代数据中心非常重要的通用的计算加速载体。
FPGA相对ASIC有一个很明显的好处,ASIC在整个设计生产环节需要18个到24个月流片周期,而且对量也有一定的要求。FPGA有这些好处的同时也存在编程比较困难的致命问题,因此FPGA的设计开发有着很大的挑战,开发周期也会比较长。数据中心主要的用户以软件开发为主,软件开发目前追求敏捷和快速迭代,这种长周期的开发形态非常制约业务部署。
4.4 软、硬件开发方法区别
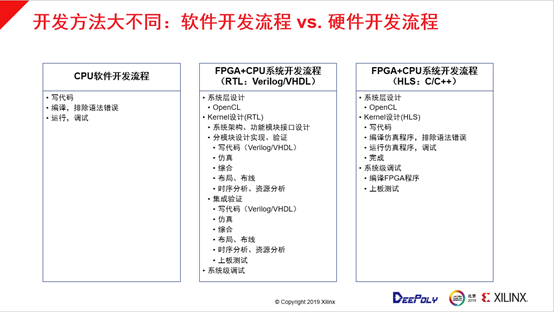
深维科技针对以上问题也提出了解决方案,如上图所示,最左边的是CPU的软件开发流程:写代码、编译,排除语法错误、运行,根据实际运行时的错误进行调试。
FPGA+CPU的开发流程传统是基于硬件设计语言去做的,Verilog/VHDL设计流程涉及到的环节也需要写代码,对等同样复杂度算法要增加10倍以上的代码量,因此整个设计流程非常复杂。对比两个系统开发流程就不难理解为什么基于硬件设计语言的FPGA开发过程往往需要半年到一年的周期,而不是软件开发的周期只要数周到几个月的时间。
赛灵思也注意到了设计流程的复杂度,于是在2012年收购了AutoESL公司,这家公司提供HLS高层次的设计方法,这个方法很好的支持了C和C++语言来编程FPGA,这种方式放到最右边的框图对流程进行相应的简化,首先是系统层设计OpenCL,Kemel设计是使用是C和C++语言来写代码,但需要加一些标注。在软件形式下去编译仿真程序,排除语法错误、运行仿真程序,迭代多次后完成。在仿真环境上调好以后才需要上板生成FPGA程序,编译成FPGA最后做一次,然后再上板去调。这个流程显然已经简化很多,而且不需要频繁在硬件层面去调试,大部分工作都是在软件环节去做。
5. 深维科技的核心能力:快速开发,全栈优化
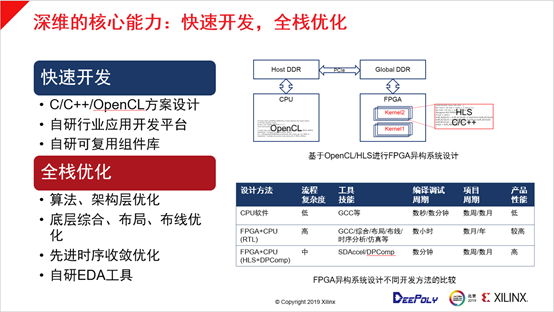
很多客户都已经试过了HLS这套开发方法,并对开发迅速这一特点有所体会,但是对于最后能不能达到预期的性能提升还存在一些问题。因为中间也经过很多年的尝试和成熟收敛,HLS已经取得了比较好的效果,普遍的认识是HLS与RTL相比,后者在细节优化上要更好一些。深维科技目前做了一些尝试,之前提到能够做到20倍以上的性能加速,应该是超过了一些RTL的产品性能。
深维科技在实现性能加速的过程中做了一些特殊的工作,关于OpenCL和HLS系统设计的范围,首先在CPU有一个Opencl描述的调度,数据是通过主机的DDL和板上FPGA加速卡的DDL进行交换。FPGA有一些相应的kernel,kernel目前是用HLS和C++来描述的。这样的任务有几个需要解决的问题,第一个问题是如何做到快速开发,如上文所述,使用C++和HLS就可以加快推出方案的速度。第二个问题是深维科技有面向行业的应用开发平台,这样可以简化面向图像处理应用领域时有通用的开发平台,可以对很多类似的任务进行共享,例如调度、适配、框架这些事情。另外还有组件库,深维科技把Codec和各种处理算法已经变成了一个标准的组件,可以在平台上对其进行非常方便的组合。
另外针对开发速度变快之后性能如何提升的问题,深维科技提出了全栈优化的技术。全栈优化是从算法层、架构层到底层的优化技术,这也是由于HLS往往会遮蔽底层实现过程,当性能达不到要求时,深维科技把综合布局、布线优化方面,在底层展开进行进一步优化,这主要依托于深维科技在EDA和FPGA芯片的设计经验,为了提升效率,深维科技也有相应的EDA的工具。综上,我们比较了一下整体研发的效果,在FPGA加速里有三类设计方法,第一类是CPU软件设计方法,它的特点是流程复杂度低,但是产品性能也低,项目周期很短。第二类是FPGA+CPU用传统RTL的设计方法,它的特点是流程复杂度非常高,性能比较高,但是项目周期非常长。第三类是深维科技目前在实践的方法FPGA+CPU(HLS+DPComp),这其中涉及到深维科技自己的工具和方法,设计方法的流程复杂度中等且内部可控。整个项目周期能够达到与软件开发类似的周期(15周到数月),并且可以达到非常高的产品性能。
-
FPGA构建高性能DSP2011-02-17 3310
-
高性能的可编程电源管理解决方案2012-08-20 2726
-
Altera低压FPGA的高性能开关模式电源解决方案2019-08-09 2214
-
如何利用FPGA开发高性能网络安全处理平台?2019-08-12 3912
-
如何实现高性能的射频测试解决方案2021-05-06 1512
-
基于DSP的高性能静态图像压缩2008-12-10 1048
-
Altera的视频和图像处理解决方案2010-06-08 961
-
高性能信号处理解决方案供应商ADI2019-08-01 3224
-
ADI公司:全球领先的高性能信号处理解决方案供应商2019-08-21 4168
-
深维科技携手浪潮打造FPGA高性能图像处理AI方案2020-06-04 1106
-
设计解决方案43-Altera低压FPGA的高性能开关模式电源解决方案2021-04-30 1033
-
如何利用HLS功能创建图像处理解决方案2022-05-13 5226
-
LM98725高性能16位81 MSPS信号处理解决方案2024-07-26 692
-
ADI高性能电源管理解决方案2024-11-15 6515
-
高性能信号处理解决方案:ADIS1622x评估工具入门指南2026-05-23 568
全部0条评论

快来发表一下你的评论吧 !
