

Tesseract的安装测试使用
描述
OCR开源项目很多,给大家一个链接,这个链接列出了现有的比较出名的OCR开源项目,链接如下:
https://en.wikipedia.org/wiki/Comparison_of_optical_character_recognition_software
从上面的排名可以看到,Tesseract是排在第一名的!所以下面就认真学习一下Tesseract。首先介绍一下Tesseract,然后安装,测试,了解其不足等等。
Tesseract的OCR引擎目前已作为开源项目发布在Google Project,
其项目主页在这里查看https://github.com/tesseract-ocr,
它支持中文OCR,并提供了一个命令行工具。python中对应的包是
pytesseract. 通过这个工具我们可以识别图片上的文字。
一 Tesseract的安装测试使用
首先下载Tesseract在Windows下的安装版。(因为在国外访问不了谷歌,所以别人***下载了下来,这里给大家百度网盘链接)
http://pan.baidu.com/s/1i56Uxlr
根据https://github.com/tesseract-ocr/tesseract/wiki,找到非官方的安装包,好像只看到64位的安装包 http://digi.bib.uni-mannheim.de/tesseract/tesseract-ocr-setup-4.00.00dev.exe,下载后直接安装即可,但是要记得你的安装目录,我们等会配置环境变量要用。
如果不是做英文的图文识别,还需要下载其他语言的识别包https://github.com/tesseract-ocr/tesseract/wiki/Data-Files。
简体字识别包:https://raw.githubusercontent.com/tesseract-ocr/tessdata/4.00/chi_sim.traineddata
繁体字识别包:https://github.com/tesseract-ocr/tessdata/raw/4.0/chi_tra.traineddata
1.3 安装Tesseract
下载Tesseract-OCR引擎,注意要3.0以上才支持中文哦,按照提示安装就行。(此处附上windows 4.0的安装过程)
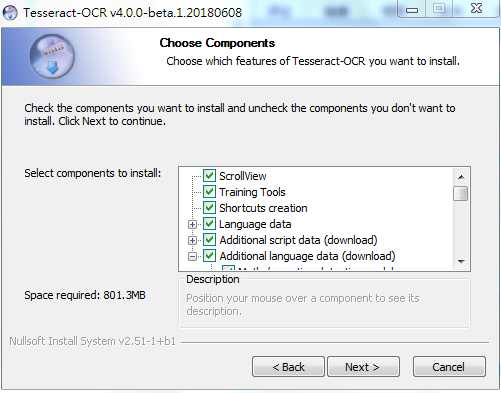
既然是要训练中文,记得勾选 additional language data
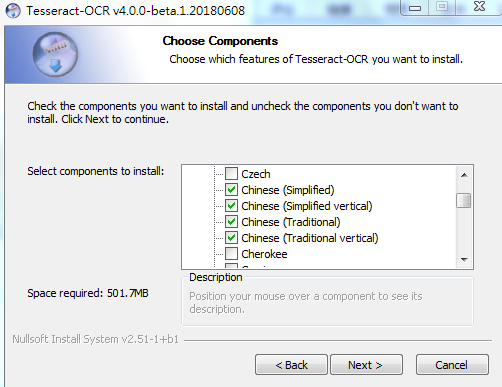
找到中文简体和中文繁体,按需勾选,然后点下一步
可以先不勾选,因为这样直接下载语言的包实在太慢。可以从网页上直接下载语言包,然后等程序安装好后,放入安装目录下tessdata目录下面
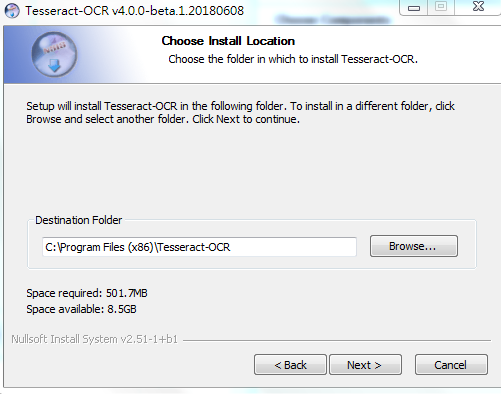
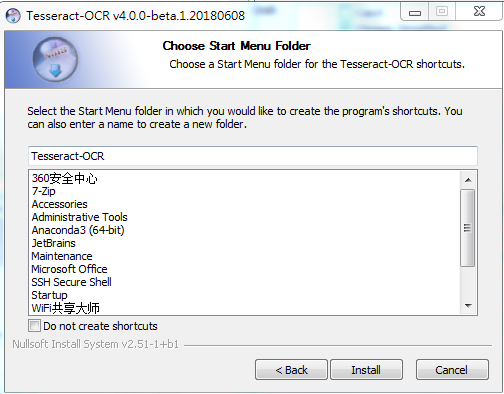
下载下来之后一路Next安装好,然后在开始菜单找到其控制台引导程序,如下图所示
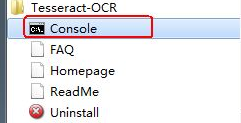
1.4 测试英文字符识别
上面的安装包里自带了已经训练好的英文-拉丁文识别数据~所以我们先来测试一下英文字符的识别吧~识别图像如下:
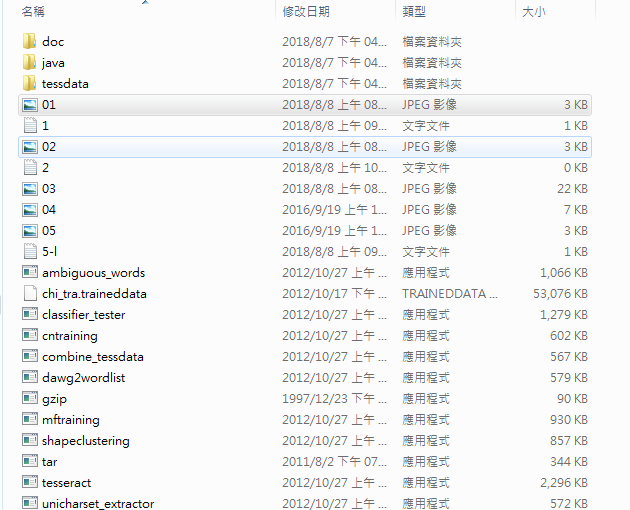
1.4.1 把上面的图片放到Tesseract的安装目录下,如下图所示:
1.4.2 打开上面提到的控制台窗口,如下图所示:
1.4.3 在窗口中输入命令:“tesseract.exe 0.jpg 1”,并回车,如下图所示:
01.jpg代表待识别的源文件,1代表输出文件名,默认输出格式是txt文件格式!
注意,上面的 lang之前是-l 而不是-1!

1.4.4 让我们先查看一下01.jpg照片,如下图:
1.4.5 在安装目录下生成了1.txt文件,识别结果如下图所示:
-
什么是电气安装测试仪?2017-09-30 3239
-
linux的tesseract-ocr安装2019-07-15 2631
-
天馈线安装与测试2011-02-16 1216
-
福禄克拥有“绝缘预测试”功能的安装测试仪粉墨登场2016-08-22 1639
-
基于zed的tesseract移植过程记录2017-02-10 1782
-
sysbench性能测试及安装2017-11-06 1157
-
日本交叉滚柱圆弧导轨的介绍和测试及安装和使用说明2018-12-04 2157
-
OracleRAC集群11g安装后的简单测试及使用2021-08-31 734
-
Tesseract-OCR中如何实现结构化的文档分析2023-01-12 2393
-
JMeter接口的安装、应用和测试案例2023-03-23 1024
-
气密测试仪设备如何安装?是否需要定期维护?2023-07-19 1764
-
Tesseract的进阶用法和最佳实践2023-09-20 2626
-
cnocr和tesseract的使用方法和效果2023-11-02 3127
-
Fluke 1670系列多功能安装测试仪在设备安装检验中的应用2026-02-28 741
全部0条评论

快来发表一下你的评论吧 !
