

你真的懂CPU的大端和小端模式吗?
电子说
描述
通信协议中的数据传输、数组的存储方式、数据的强制转换等这些都会牵涉到大小端问题。 CPU的大端和小端模式很多地方都会用到,但还是有许多朋友不知道,今天暂且普及一下。 一、为什么会有大小端模式之分呢?
因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。
但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的int型。另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
例如一个16bit的short型x,在内存中的地址为0x0010,x的值为0x1122,那么0x11为高字节,0x22为低字节。
对于大端模式,就将0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,刚好相反。
二、什么是大端和小端? 大端模式:是指数据的高字节保存在内存的低地址中,而数据的低字节保存在内存的高地址中。
小端模式:是指数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
假如32位宽(uint32_t)的数据0x12345678,从地址0x08004000开始存放:
| 地址 | 小端存放内容 | 大端存放内容 |
|---|---|---|
| 0x08004003 | 0x12 | 0x78 |
| 0x08004002 | 0x34 | 0x56 |
| 0x08004001 | 0x56 | 0x34 |
| 0x08004000 | 0x78 | 0x12 |
再结合一张图进行理解:
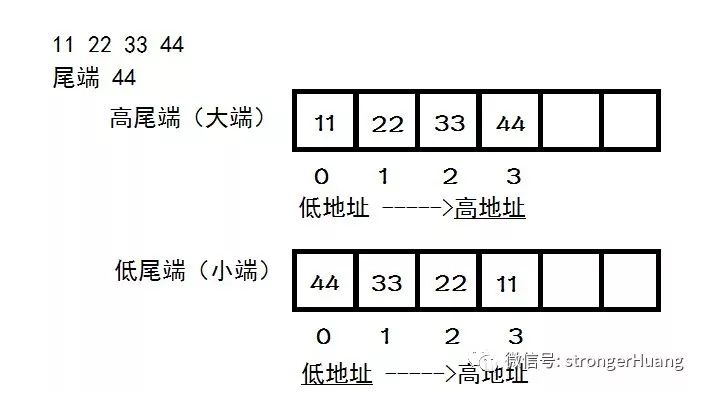
从上面表格、图可以看得出来,大小端的差异在于存放顺序不同。 在维基百科中还有有一段关于“端的起源”:

三、数组在大端小端情况下的存储 以unsigned int value = 0x12345678为例,分别看看在两种字节序下其存储情况,我们可以用unsigned char buf[4]来表示value。 1.大端模式下
| 地址 | 数组 | 值 | 位置 |
|---|---|---|---|
| 高地址 | buf[3] | 0x78 | 低位 |
| - | buf[2] | 0x56 | - |
| - | buf[1] | 0x34 | - |
| 低地址 | buf[0] | 0x12 | 高位 |
2.小端模式下
| 地址 | 数组 | 值 | 位置 |
|---|---|---|---|
| 高地址 | buf[3] | 0x12 | 低位 |
| - | buf[2] | 0x34 | - |
| - | buf[1] | 0x56 | - |
| 低地址 | buf[0] | 0x78 | 高位 |
不知道大家对数组进行强制转换成整型数据没有? 如果你要进行强制转换,肯定要考虑大小端问题。 四、大小端谁更好?
小端模式:强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式:符号位的判定固定为第一个字节,容易判断正负。
总结:大端小端没有谁优谁劣,各自优势便是对方劣势。
五、常见字节序
常见的操作系统是小端,通讯协议是大端。
1.常见CPU的字节序
大端模式:PowerPC、IBM、Sun
小端模式:x86、DEC
ARM既可以工作在大端模式,也可以工作在小端模式。
(内容来自网络)
2.STM32属于小端模式
测试一款MCU属于大端,还是小端方法很多种,通过打印数据,通过在线调试查看数据:
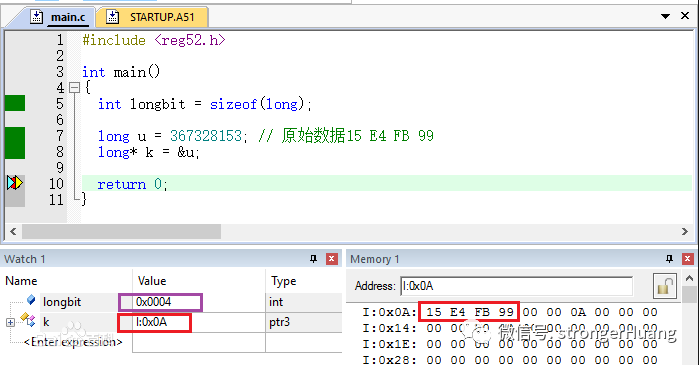
当然,在MCU的手册中也有相关说明。
六、大小端转换
开篇说了,实际应用中,大小端应用的地方很多通信协议、数据存储等。如果字节序不一致,就需要转换。
只要你理解其中原理(高低顺序),转换的方法很多,下面简单列列两个。
1.对于16位字数据
#define BigtoLittle16(A) (( ((uint16)(A) & 0xff00) >> 8) | (( (uint16)(A) & 0x00ff) << 8))
2.对于32位字数据
#define BigtoLittle32(A) ((( (uint32)(A) & 0xff000000) >> 24) | (( (uint32)(A) & 0x00ff0000) >> 8) | (( (uint32)(A) & 0x0000ff00) << 8) | (( (uint32)(A) & 0x000000ff) << 24))
方法很多种,感兴趣的朋友可自行研究。本文就写到这里,希望对你有帮助。
-
大端序与小端序2017-12-13 5204
-
如何知道你的MCU是大端模式还是小端模式呢2021-12-08 1367
-
大端模式与小端模式分析2021-12-16 690
-
你真的懂Word吗2022-01-12 1663
-
ARM芯片是小端还是大端2022-06-30 5567
-
keil怎么设置大端和小端模式?2023-09-21 1259
-
iar编译器是大端模式还是小端模式的?2023-09-25 574
-
STM32中的FLASH数据是大端模式还是小端模式?2023-10-13 765
-
请问如何配置STM32的FSMC的大端模式小端模式?2023-11-07 1104
-
cpu的大端模式小端模式优劣对比2017-11-08 13335
-
关于大端模式与小端模式的介绍2018-07-22 7630
-
存储器的大端模式和小端模式2018-10-27 6283
-
嵌入式开发中CPU大端和小端模式的详细资料和程序分析讲解2019-05-06 1394
-
你真的懂CPU大小端模式吗?2020-02-27 3900
-
测试MCU是大端模式还是小端模式2021-11-25 1081
全部0条评论

快来发表一下你的评论吧 !
