

一款工具,借助深度学习模型可以一键抠去漫画中的文字
电子说
描述
漫画抠图是汉化组翻译中必不可少而又工作量很大的一项工作,主要内容是将漫画中的文字抠去,以便替换成另一种语言。现在,这项工作可以自动化地完成了,一位韩国的开发者开源了一款工具,借助深度学习模型可以一键抠去漫画中的文字,连背景图中的文字都可以被抠去,效果十分惊人。
很多人都喜欢看日本漫画,不少作品已经成为很多人心中的童年回忆。但是对于漫画的翻译人员来说,他们需要去除原有漫画的对话框和背景文字,并将其替换为读者使用的语言。由于一本漫画可能有数万个对话框和对话,因此工作量是很大的。
现在,抠图的工作人员可以基本上解放他们的双手了。只要你有 TensorFlow,就可以快速实现一键抠图,将漫画图像中的所有文字一键去除。
SickZil-Machine,一键抠图
SickZil 是韩文中的作者提供了一个视频,用于展示这一工具的效果。
作者同时提供了自动工具抠图的案例。
对话框中的文字可以被完全消除。
有时候会有些文字消除不干净的情况,但基本不影响画面(漫画右上角标题符号)。同时,背景中被去掉文字后,背景画面可以被自动补全,基本不改变画面效果(画面右上角背景文字)。
从视频中可以看出,这一工具非常的方便。只需要选择待处理的漫画,然后运行工具即可。如果有一些画面被误去除,或者有一些去除不干净的情况下,用户可以手动修改需要被去除的文字。
那么,这一工具背后是什么技术呢?
技术
模型架构
据项目作者介绍,这一工具背后使用了两个模型,第一个是 Seg Net,用于检测漫画中的问题。另一个则是 Compl Net,用于处理漫画图像,去除文字并补全缺失的图像部分。
Seg Net 使用的是 U-NET。这是一种编码器-解码器架构。编码器逐渐减少池化层的空间维度,解码器逐步修复物体的细节和空间维度。
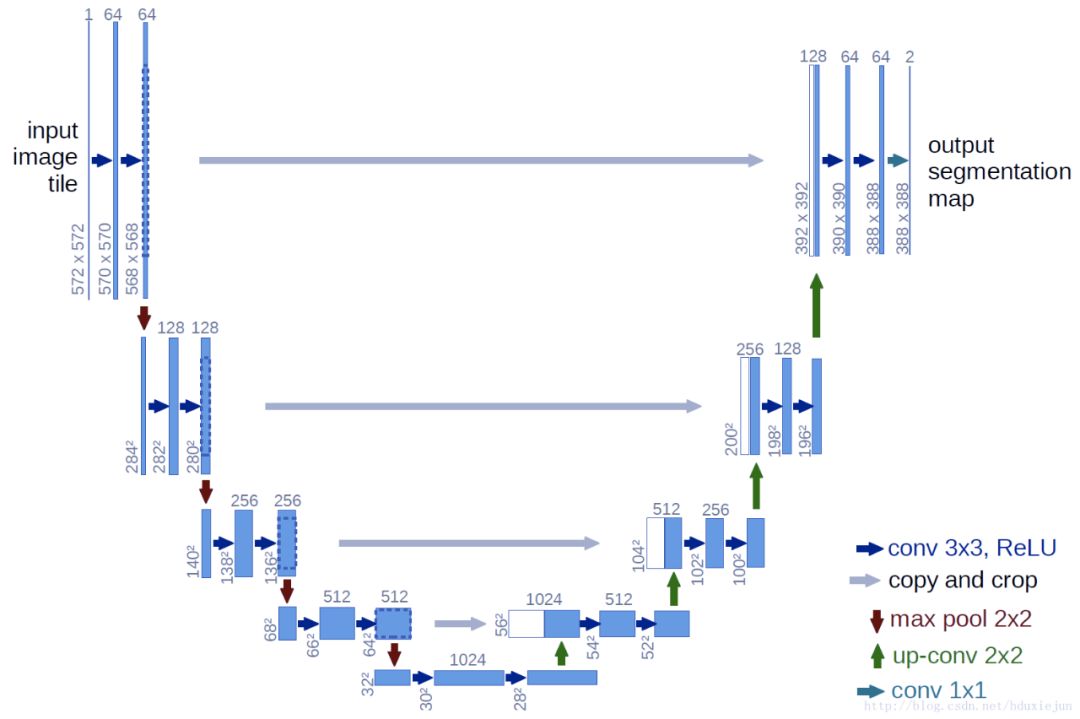
U-Net 的架构,将输入图像逐步池化后进行上采样,从而还原图像细节。
而 Compl Net 使用的是 deepfill v2,这是一个用于对任意被 mask 的图像进行修复的模型,可以适应各种 mask 的方式(块状遮盖或线条遮盖都可以)。deepfill 是 Adobe 等机构提出一系列图像修复工具,机器之心也曾用过 deepfill v1,但是效果似乎没有论文展示的那么好。
目前 deepfill v2 并没有官方开源,但 GitHub 上有其他开发者复现。
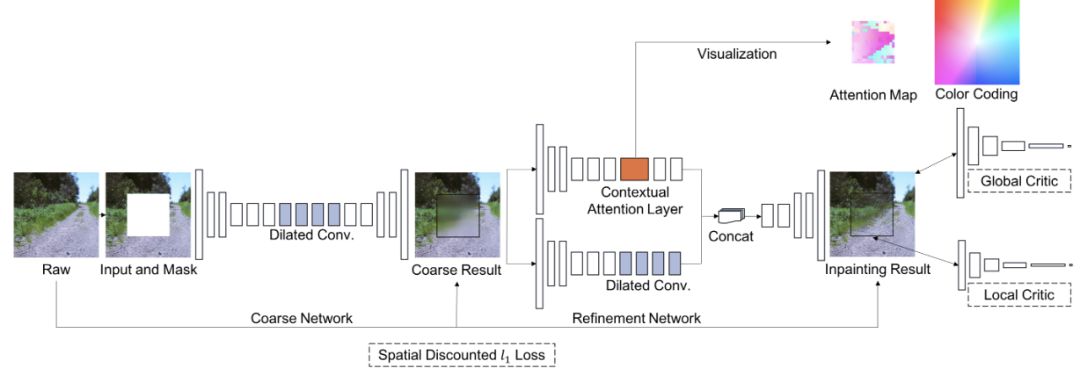
deepfill v2 的模型架构,可以进行图像修复。
有了这两大神器,基本上可以实现漫画文字的检测识别和去除文本后的图像补全。
数据集和训练
有了模型还不够,很多读者想知道,整个系统是怎样训练的。
在 Seg Net 上,作者使用了原始的漫画图像和文本内容遮盖数据,用于覆盖原始漫画中所有的文字部分。在 Compl Net 上,模型的输入为被移除了文字的漫画图像。模型使用了 285 个图像-遮盖对和 31500 张漫画图像,其中有将近 12000 张漫画是有文字的,因此训练的数据比较平衡。
安装和使用
作者没有透露训练模型的相关参数,但是提供了开发者需要准备的硬件配置。 对于开发者而言,运行代码需要准备 NVIDIA 驱动 410.x,CUDA 10.0,CUDNN >= 7.4.1,TensorFlow 需要大于 1.13 版本。
配置代码步骤如下:
首先克隆相关代码:git clone https://github.com/KUR-creative/SickZil-Machine.git; cd SickZil-Machine
下载 zip 文件,地址:https://github.com/KUR-creative/SickZil-Machine/releases。
解压并复制文件:SickZil-Machine-0.1.1-pre0-win64-cpu-eng/resource/cnet 和 SickZil-Machine-0.1.1-pre0-win64-cpu-eng/resource/snet 到文件目录:SickZil-Machine/resource.
进入目录并安装:pip install -r requirements.txt
运行主程序:cd src; python main.py
-
一键还原_一键还原精灵等系统还原软件集合2011-03-12 6122
-
一键还原小工具2012-05-14 2668
-
系统一键还原工具2012-05-27 3975
-
一键还原系统2012-06-18 3094
-
电脑系统一键还原工具2012-07-01 3068
-
一键还原系统工具2.02012-08-05 4953
-
一键还原系统工具2012-08-08 2999
-
小白专用的一键重装系统教程(图文版)2013-08-13 7102
-
电信一键免流量软件电信一键免流软件app2016-07-19 3186
-
老毛桃一键还原2018-05-28 2242
-
DFM一键分析值得使用2021-05-20 6189
-
基于Simulink的STM32工具箱外设一键式代码该如何去生成呢2021-11-18 1513
-
Office 2010 Toolkit一键激活工具2012-09-03 951
-
移动叔叔一键制移动叔叔一键制作MTK智能机IMEI串号工具作MT2015-11-02 4370
-
一键分析2021-07-28 1186
全部0条评论

快来发表一下你的评论吧 !
