

什么是支持向量机 什么是支持向量
人工智能
描述
支持向量机,英文为Support Vector Machine,简称SV机(论文中一般简称SVM)。它是一 种监督式学习的方法,它广泛的应用于统计分类以及回归分析中。
支持向量机(Support Vector Machine)是一种十分常见的分类器,曾经火爆十余年,分类能力强于NN,整体实力比肩LR与RF。核心思路是通过构造分割面将数据进行分离。
支持向量机属于一般化线性分类器,他们也可以认为是提克洛夫规范化(Tikhonov Regularization)方法的一个特例。这族分类器的特点是:他们能够同时最小化经验误差与最大化几何边缘区,因此支持向量机也被称为最大边缘区分类器。在统计计算中,最大期望(EM) 算法是在概率(probabilistic)模型中寻找参数最大似然估计的算法,其中概率模型依赖于无 法观测的隐藏变量(Latent Variabl)。最大期望经常用在机器学习和计算机视觉的数据集聚 (Data Clustering)领域。
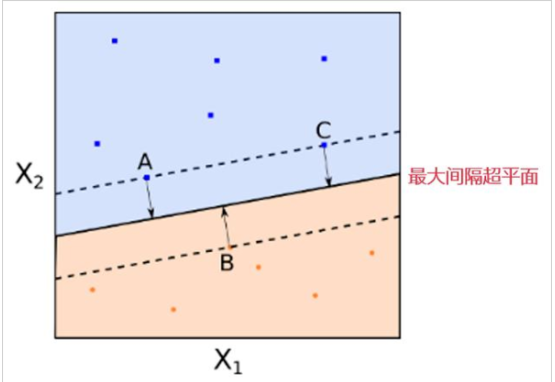
在支持向量机中,距离超平面最近的且满足一定条件的几个训练样本点被称为支持向量。
图中有红色和蓝色两类样本点。黑色的实线就是最大间隔超平面。在这个例子中,A,B,C 三个点到该超平面的距离相等。
注意,这些点非常特别,这是因为超平面的参数完全由这三个点确定。该超平面和任何其他的点无关。如果改变其他点的位置,只要其他点不落入虚线上或者虚线内,那么超平面的参数都不会改变。A,B,C 这三个点被称为支持向量(support vectors)。
一、应用
SVM在各领域的模式识别问题中有广泛应用,包括人像识别(face recognition) 、文本分类(text categorization) 、笔迹识别(handwriting recognition) 、生物信息学 等。
二、SVM 的优点
1、高维度:SVM 可以高效的处理高维度特征空间的分类问题。这在实际应用中意义深远。比如,在文章分类问题中,单词或是词组组成了特征空间,特征空间的维度高达 10 的 6 次方以上。
2、节省内存:尽管训练样本点可能有很多,但 SVM 做决策时,仅仅依赖有限个样本(即支持向量),因此计算机内存仅仅需要储存这些支持向量。这大大降低了内存占用率。
3、应用广泛:实际应用中的分类问题往往需要非线性的决策边界。通过灵活运用核函数,SVM 可以容易的生成不同的非线性决策边界,这保证它在不同问题上都可以有出色的表现(当然,对于不同的问题,如何选择最适合的核函数是一个需要使用者解决的问题)。
-
支持向量机——机器学习中的杀手级武器!2018-08-24 3952
-
基于支持向量机的预测函数控制2009-03-17 837
-
特征加权支持向量机2009-11-21 656
-
基于改进支持向量机的货币识别研究2009-12-14 631
-
基于支持向量机(SVM)的工业过程辨识2012-03-30 1056
-
大数据中边界向量调节熵函数支持向量机研究2017-01-07 910
-
基于标准支持向量机的阵列波束优化及实现2017-11-10 1028
-
多分类孪生支持向量机研究进展2017-12-19 1013
-
基于支持向量机的测深激光信号处理2017-12-21 1080
-
支持向量机的故障预测模型2017-12-29 1276
-
关于支持向量机(SVMs)2018-04-02 4861
-
介绍支持向量机的基础概念2023-04-28 1949
-
支持向量机(核函数的定义)2023-05-20 2133
-
支持向量机(原问题和对偶问题)2023-05-25 2767
-
支持向量机(兵王问题描述)2023-06-09 3635
全部0条评论

快来发表一下你的评论吧 !
