

浪潮发布全球首个完整方案的FPGA高效AI计算框架
可编程逻辑
描述
(文章来源:消费日报网)
在北京举行的2019人工智能计算大会(AICC2019)上,浪潮宣布开源发布基于FPGA的高效AI计算框架TF2,这一框架的推理引擎采用全球首创的DNN移位计算技术,结合多项最新优化技术,可实现通用深度学习模型基于FPGA芯片的高性能低延迟部署,这也是全球首个包含从模型裁剪、压缩、量化到通用模型实现等优化算法的完整方案的FPGA上AI开源框架,项目开源网址为https://github.com/TF2-Engine/TF2。
据悉目前已有快手、上海大学、华大智造、远鉴科技、睿视智觉、华展汇元等多家公司或研究机构加入TF2开源社区,社区将共同推动基于可定制芯片FPGA的AI技术的开源开放合作发展,降低高性能AI计算技术门槛,帮助AI用户和开发者缩短开发周期。
当前,可定制、低延迟、高性能功耗比的FPGA技术成为很多AI用户部署推理应用的选择,但FPGA开发难度大、周期长,难以适应快速迭代的深度学习算法应用需求。TF2可快速实现基于主流AI训练软件和深度神经网络模型DNN的FPGA线上推理,帮助用户最大限度的发挥FPGA计算能力,实现FPGA的高性能、低延迟部署。同时TF2计算架构也可以快速实现AI芯片级设计和性能验证。
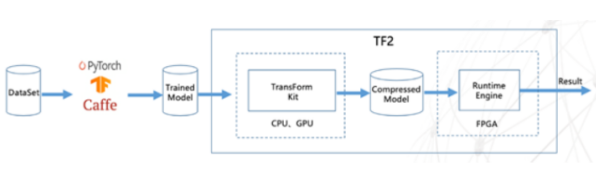
TF2由两部分组成。第一部分是模型优化转换工具TF2 Transform Kit,可将经过PyTorch、TensorFlow、Caffe等框架训练得到的网络模型数据进行压缩、裁剪、8位量化等操作,减少模型计算量。如对于ResNet50模型,通过压缩32位浮点模型为4位整数模型、通道裁剪,可将模型文件裁剪掉93.75%,几乎无精度损失并保持原始模型的基本计算架构。
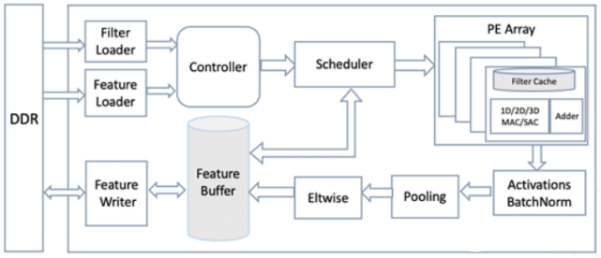
第二部分是FPGA智能运行引擎TF2 Runtime Engine,可将已优化转换的模型文件自动转化为FPGA目标运行文件,通过创新的DNN移位计算技术大幅提升FPGA做推理计算的性能,并有效降低其实际运行功耗。TF2已完成在ResNet50、FaceNet、GoogLeNet、SqueezeNet等主流DNN模型上的测试验证。在浪潮F10A FPGA卡上采用FaceNet模型对TF2进行的测试(BatchSize=1)表明,运行TF2后单张图片的计算耗时为0.612ms,提速12.8倍。
同时,浪潮开源的项目中还包括TF2的软件定义的可重构芯片设计架构。此架构完整支持当前CNN网络模型的开发,并可快速移植使其支持Transformer、LSTM等网络模型开发。以此架构为基础,可进一步实现ASIC芯片开发原型设计。
(责任编辑:fqj)
-
ITU-T正式发布首个云计算框架性标准2013-07-31 1969
-
Firefly支持AI引擎Tengine,性能提升,轻松搭建AI计算框架2018-08-13 4650
-
全球首个AI合成主播上岗新华社,可24小时不间断工作2018-11-17 2244
-
搜狗与新华社联合发布全球首个站立式AI合成主播2019-02-25 4109
-
当AI遇上FPGA会产生怎样的反应2021-09-17 3806
-
阿里平头哥发布首个 RISC-V AI 软硬全栈平台2023-08-26 853
-
浪潮在美国发布深度学习计算框架Caffe2018-05-18 1856
-
浪潮与科大讯飞联合发布AI Booster_AI计算加速比提升18%2018-05-06 5908
-
华为发布的AI计算框架可保护用户隐私2019-08-23 3872
-
浪潮发布全球首个FPGA高效计算框架2019-09-09 1510
-
浪潮全球首发完整方案的FPGA高效计算框架2019-09-23 2544
-
浪潮正式发布全球首款AI开放加速计算系统MX12020-04-10 2819
-
浪潮发力助推TF2 FPGA高效AI计算开源框架2020-06-04 1412
-
华为云发布全生命周期知识计算解决方案,实现AI与行业知识高效结合2020-09-24 2946
-
华为AI计算框架MindSpore 1.2正式发布2021-04-30 3054
全部0条评论

快来发表一下你的评论吧 !
