

关于内存大家都知道,但什么是内存内计算
电子说
描述
(文章来源:至顶网)
在过去的几十年中,计算性能的提高是通过更快、更精确地处理更大数量的数据来实现的。内存和存储空间现在是以千兆字节和兆字节来衡量的,而不是以千字节和兆字节。处理器操作64位而不是8位数据块。然而,半导体行业创造和收集高质量数据的能力比分析数据的能力增长得更快。
随着人工智能的不断发展,逐渐衍生出了一个新兴技术,那就是“内存内计算”。而近来,内存内计算也一度成了热门的关键词。早些时候,IBM就发布了基于相变内存(PCM)的内存内计算,在此之后基于Flash内存内计算的初创公司也获得高额融资;而在中国,初创公司也开始在做内存内计算方面的尝试。然而“内存内计算”倒是什么东西?这种新技术的诞生,还要从冯 · 诺依曼体系和人工智能讲起。
自从计算机诞生的那天开始,冯 · 诺依曼架构的体系就占据着主导的地位。这种运行计算方式是先把数据存入主存储器,再按照顺序从主存储器中取出指令,然后一条一条地执行。我们都知道,如果内存的通讯速度跟不上CPU的性能,就会导致计算能力受到限制,这就是内存墙了。同时在效能方面,冯 · 诺依曼体系也存在明显的缺点,它读写一次内存数据的能量,要比计算一次数据的能量多消耗了足足几百倍。
而在现在人工智能的技术中,随着数据量越来越多,计算量越来越大,原始的冯 · 诺依曼结构正承受着越来越多的挑战。硬件架构不能指望计算量一大,就扩展CPU。因为存储量一变大,就马上采用增大内存来存储的方式是对过去架构的严重依赖,并且这种方式也非常不适合AI。当容量大到一定程度,只能说明某些技术需要革新。从生物角度来讲,大脑存储了大量的知识,并且能够快速访问并提取,而大脑的内存和计算是相容的。未来的计算机不是基于计算的memory,而是基于memory的计算。
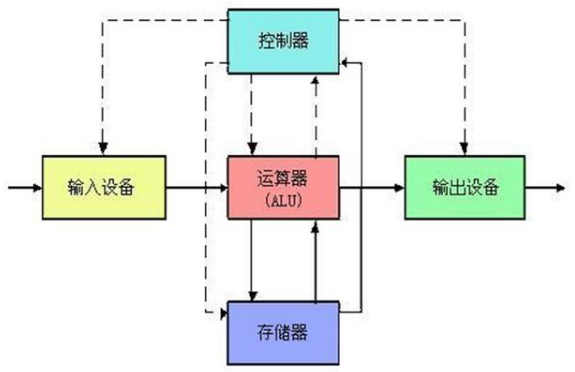
同时,目前最主流的人工智能,也是对计算能力有着极高的要求。如果想让人工智能用在移动端和嵌入式设备中,还有能耗大,发热降频等问题。这样一来,内存和效能就变成了冯 · 诺依曼计算机体系的一个瓶颈。为了解决这一系列的问题,于是就衍生出了传说中的内存内计算。顾名思义就是把计算单元嵌入到内存里面,这样的话内存既是一个存储器,也是一个计算机,它并不需要从内存中读取数据,数据是直接进出CPU的。不但不受内存的性能限制,而且还提高了效能比(能源转换的效率之比)。
人工智能专用的NPU(嵌入式神经网络处理器)SPR2801S就使用了内存内计算,这种技术还搭建了人工智能专用的APIM构架,它的全称是AI Processing In Memory。采用了APIM构架的计算机不需要指令,也不需要总线和DDR(双倍速率同步动态随机存储器),大数据就可以直接进出CPU,极大地提高了效能比。此外,它还把算力提高到了5.6T ops,高效能比高达9.2T ops每瓦。Firefly基于这款SPR2801S则推出了人工智能开源主板AIO-3399EC,以及NCC S1 神经网络计算卡和USB神经网络计算棒,还搭配了模型训练工具PLAI。可以说,这些都加速了人工智能项目的落实。
虽然内存内计算现在还处于探索阶段,但是人们在十余年之前就认识到了“内存墙”的问题,但是为什么内存内计算直到现在才被人们关注呢?小编认为主要有两点,第一个就是基于神经网络的AI的兴起,尤其是人们都希望AI能普及到移动端和嵌入式设备中。而神经网络的其中1个特点就是对于计算精度的误差有着比较高的容忍度,所以内存内计算的中引入的误差一般都可以被神经网络所接受。内存内计算和人工智能,尤其是嵌入式人工智能,可以说是完美的结合。
第二个则是新存储器分发展。对于内存内计算来说,存储器的特性决定了它的效率,所以每当带有新特性的存储器出现时,都会带动内存内计算的发展。此外,从存储器推广的角度,新存储器的诞生也愿意搭上人工智能的风潮,这样一来新存储器的厂商也乐于看到有人做基于自家存储器的内存内计算去加速人工智能,也会帮助一起推广内存内计算。
内存内计算利用存储器的特点,减少了人工智能在计算中的读写和操作,也正是因为内存内计算的精度受到了模拟计算的限制,所以它也是目前为止,最适合追求能效比以及能接受一定精确度损失的嵌入式人工智能的应用。
(责任编辑:fqj)
-
虚拟内存和云计算的关系2024-12-04 1273
-
关于C语言结构体内存对齐2022-04-14 7589
-
物理内存管理内研究的内容有哪些?2021-06-10 2015
-
给大伙科普关于语音芯片运行内存那些事2021-05-27 2832
-
高频率内存有哪些优势?虚拟内存是什么2020-12-06 7274
-
计算内存与非计算内存有什么区别?2020-11-04 2969
-
内存条在电脑中的作用究竟有多大2020-09-03 6603
-
虚拟内存低如何解决2020-06-13 1578
-
内存条坏了会出现什么状况_内存条坏了如何解决2020-06-01 13708
-
怎样计算内存频率2019-07-04 7650
-
需要了解linux的内存管理2019-05-13 804
-
求推荐关于计算机内存条知识的入门书籍2019-01-23 4066
-
关于内存优化知识你知道多少呢?2018-08-31 3506
-
关于环路补偿你都知道些什么2018-03-01 8668
全部0条评论

快来发表一下你的评论吧 !
