

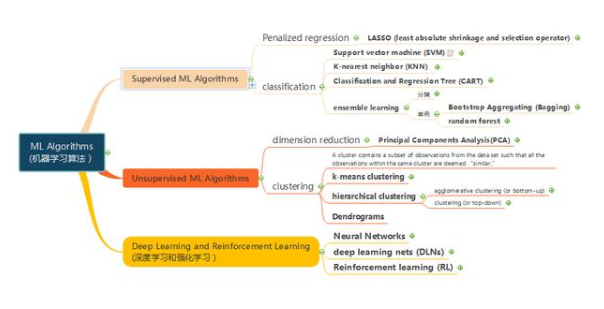
CFA二级思维导图分享:机器学习
人工智能
描述
Reading7主要了解机器学习的一些常见概念,主要分类、了解常用算法的原理及其用途。
机器学习(Machine Learning)专门研究计算机怎样模拟或实现人类的学习行为,以获取新的知识或技能,重新组织已有的知识结构使之不断改善自身的性能。从实践的意义上来说,机器学习是一种通过利用数据,训练出模型,然后使用模型预测的一种方法。
相比于传统统计学方法(回归分析)依赖于假设和先验性的限制性条件,机器学习可以没有假设的情况下训练模型,机器学习的一个计算原理是“find the pattern, apply the pattern”。
根据数据类型的不同,机器学习通用的分类为:监督学习(Supervised Learning)、非监督学习(Unsuperviese Learning)、深度学习和强化学习(Deep Learning & Reinforcement Learning)。
样本分类
在机器学习中,训练模型的算法数据集包括:训练样本(Trainning Sample),检验样本(validation sample)、验证样本(Testing Sample)。训练样本用于训练得出模型,检验样本用于修正模型,验证样本用于检验模型的有效性。
监督学习和非监督学习的主要区别在于训练样本是否已经标定了结果,。打个简单的类比来说,监督学习就是给你一堆习题,这些习题是有标准答案的,学习(算法)完之后给一张考卷,测验考试成绩。而非监督学习,就是给你 一堆数据,自己去发现规律,然后将规律应用到新的数据中,类似于给一堆乐高积木,自己去发现规律, 考试就给另外一堆乐高积木,看能否应用之前发现的规律。
监督学习算法
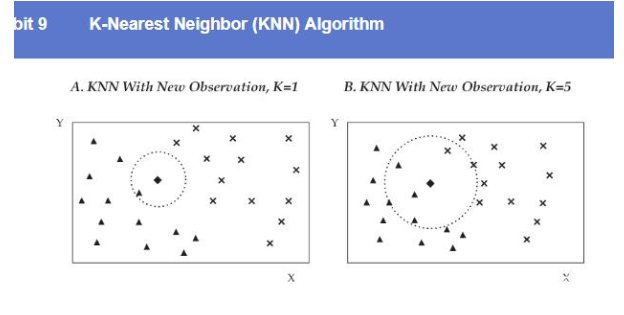
监督学习可应用于回归和分类问题,回归和分类的区别在于输出的结果是连续变量还是分类变量。常见的回归算法有惩罚性回归算法,LASSO。常用的分类算法有支持向量机(Support vector machine (SVM))、近邻算法(K-nearest neighbor (KNN) 、分类回归树(Classification and Regression Tree (CART)),以及集成算法,集成算法为将多种不同的算法或模型集成到一起,将各个不同模型的结果放到一起,按模型结果的最大值作为整个算法的结果,如Bootstrap Aggregating (Bagging)、随机森林(random forest)

非监督学习算法
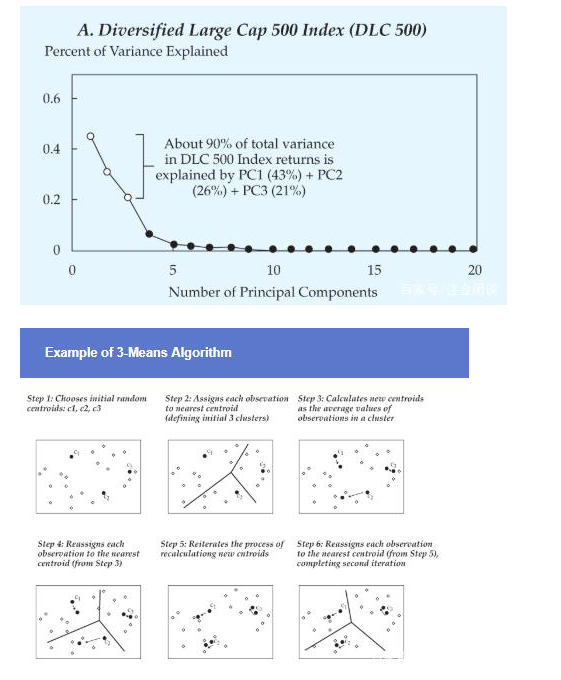
非监督学习用于解决降维和聚类问题,降维是一种减少特征数量的方法,选出对结果影响最大的特征。聚类问题就是把含相似特征的数据放到一起。
降维主要的算法是主成分分析(PCA)算法,聚类问题的算法包括k-means clustering、分层聚类hierarchical clustering、树状图Dendrograms。
深度学习
第三类深度学习,既可能是监督学习,也可能是非监督学习。包括神经网络(Neural Networks,NN/ANN)、深度学习(deep learning nets ,DLNs)和强化学习(Reinforcement learning ,RL)
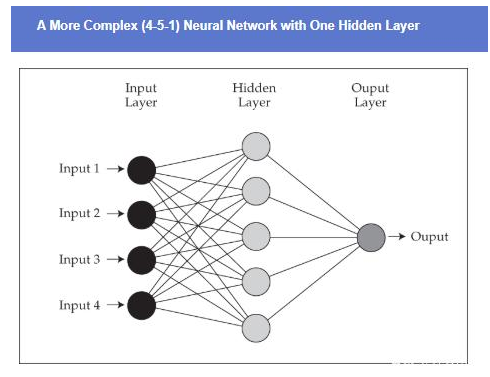
神经网络由输入层(Input layer)、隐藏层(hidden layers)和输出层(Output layer)构成。深度学习是至少有3个,一般超过20个的隐藏层。
-
思维导图可以做什么?这8大场景少不了2021-04-27 4588
-
思维导图软件深度测评:MindManager VS MindMaster2021-04-25 4015
-
2020最新的Python思维导图合集免费下载2020-12-14 1308
-
收藏!办公学习类思维导图软件终极评测!2020-11-27 2795
-
免费好用的思维导图软件-MindMaster2020-11-23 3015
-
C进阶技巧:二级指针问题2020-09-08 2786
-
思维导图有哪些元素?如何在线绘制思维导图?2018-11-12 2245
-
二级防雷专用柔性防雷铜导索2018-11-07 1376
-
思维导图如何使用,快速帮你解决2018-06-05 643
-
C语言二级2016-08-20 3190
-
全国计算机等级考试教程(二级公共基础知识)2015-10-30 764
-
第二级采样和保持电路图2009-07-09 865
-
全国计算机二级试题全集2008-12-30 1155
全部0条评论

快来发表一下你的评论吧 !
