

Groq发布全球首款每秒1000万亿次运算的AI加速卡
处理器/DSP
899人已加入
描述
2016年底,谷歌TPU团队的十位核心开发者中的八位悄悄离职,创办了一家名为 Groq 的机器学习系统公司,是进军AI加速卡的第100家、是商业化推向市场的第2家,是首家达到每秒1000万亿次运算的公司。如果做对比,那么它是当前NVIDIA最强大显卡性能的四倍。
The Groq Tensor Streaming Processor (TSP) 要求每个内核达到300W,而且他们已经成功做出来了。而且更幸运的是,已将其从劣势转变为TSP的最大优势。
这款TSP是一块巨大的硅处理器,几乎只有矢量和矩阵处理单元以及高速缓存,因此没有任何控制器或后端,编译器具有直接控制权。TSP分为20个超级通道。超级通道按从左到右的顺序构建:矩阵单元(320 MAC),交换单元,存储单元(5.5 MB),矢量单元(16 ALU),存储单元(5.5 MB),交换单元,矩阵单元( 320个MAC)。
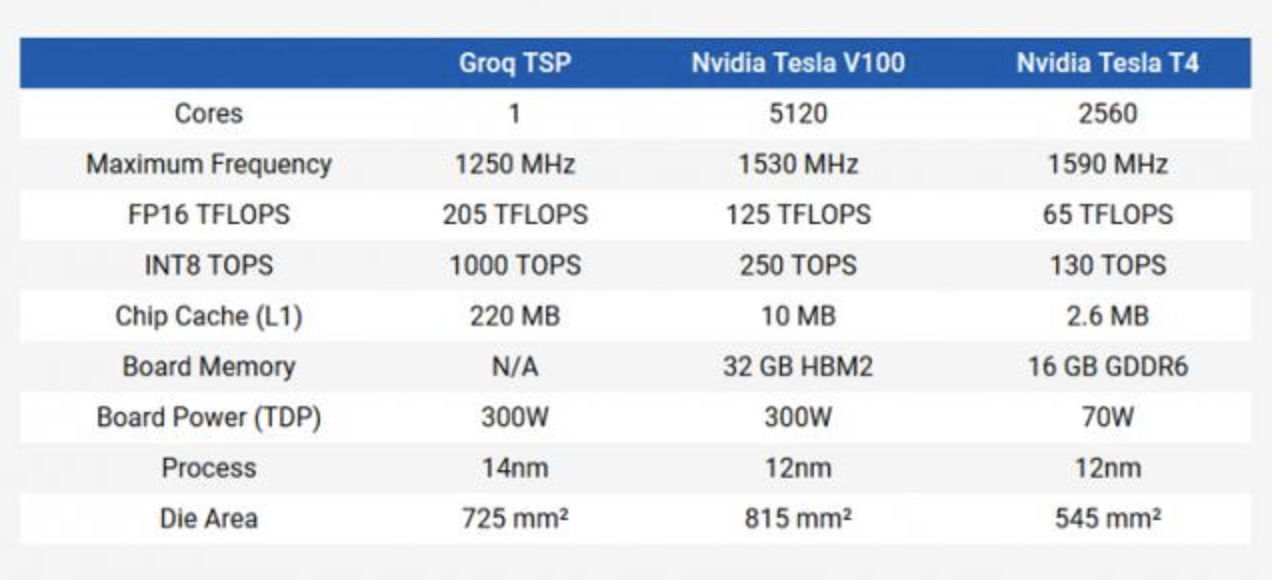
指令流(只有一个)被馈送到超通道0的每个组件中,其中矩阵单元有6条指令,开关单元有14条指令,存储单元有44条指令,向量单元有16条指令。每个时钟周期,单元执行操作,并将数据移到超通道内的下一个位置。每个组件都可以从其相邻邻居发送和接收512B。
超级通道的操作完成后,它将所有内容传递到下一个超级通道,并接收上方的超级通道(或指令控制器)拥有的所有内容。指令始终在超级通道之间垂直向下传递,而数据仅在超级通道内水平传输。
在ResNet-50中,它可以在任何批处理大小下每秒执行20,400个推理(I / S),推理延迟为0.05毫秒。Nvidia的Tesla V100可以以128的批量大小执行7,907 I / S,或者以1的批量大小执行1,156 I / S。

但有了 Groq 的硬件和软件,编译器就可以准确地知道芯片的工作方式以及执行每个计算所需的时间。编译器在正确的时间将数据和指令移动到正确的位置,这样就不会有延迟。到达硬件的指令流是完全编排好的,使得处理速度更快,而且可预测。
开发人员可以在 Groq 芯片上运行相同的模型 100 次,每次得到的结果都完全相同。对于安全和准确性要求都非常高的应用来说(如自动驾驶汽车),这种计算上的准确性至关重要。另外,使用 Groq 硬件设计的系统不会受到长尾延迟的影响,AI 系统可以在特定的功率或延迟预算内进行调整。
这种软件优先的设计(即编译器决定硬件架构)理念帮助 Groq 设计出了一款简单、高性能的架构,可以加速推理流程。该架构既支持传统的机器学习模型,也支持新的计算学习模型,目前在 x86 和非 x86 系统的客户站点上运行。
根据官方发布的新闻稿,该TSP已经作为Nimbix Cloud的加速器面向部分客户开放。
来源:cnBeta
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
- 相关推荐
- 热点推荐
- Groq
-
浪潮联合Xilinx发布全球首款集成HBM2的FPGA AI加速卡F37X2018-10-16 5450
-
基于加速卡的FPGA生态系统布局是怎样的?2021-06-17 2525
-
MLU220-M.2边缘端智能加速卡支持相关资料介绍2022-08-08 6739
-
LCD转VGA视频加速卡2009-09-21 845
-
中国人“芯”痛之后 首款云端AI芯片发布2018-05-12 5829
-
赛灵思推首款SmartNIC平台,集网络、存储和计算加速一体2020-03-05 3591
-
燧原科技发布了首款面向云端的高性能推理卡2020-12-22 3300
-
寒武纪思元290智能芯片及加速卡、玄思1000智能加速器亮相 全面支持AI训练2021-01-21 5562
-
瞬变对AI加速卡供电的影响2023-12-01 1796
-
宁畅参与发布AI加速卡液冷设计白皮书2024-01-09 1962
-
英伟达发布超强AI加速卡,性能大幅提升,可支持1.8万亿参数模的训练2024-03-19 2286
-
英伟达发布最强AI加速卡Blackwell GB2002024-03-20 2734
-
EPSON差分晶振SG3225VEN频点312.5mhz应用于AI加速卡2024-09-10 878
-
边缘AI运算革新 DeepX DX-M1 AI加速卡结合Rockchip RK3588多路物体检测解决方案2025-05-06 1249
-
国内首颗软件定义近存计算AI芯片亮相,14nm成熟制程实现520万亿次算力2026-07-15 100
全部0条评论

快来发表一下你的评论吧 !
