

区块链主流共识算法你了不了解
区块链
描述
据库,密码学相关理论,共识机制和P2P网络。本文将详细探讨目前主流的区块链共识算法。
共识算法与CAP理论
要探讨共识算法,首先就需要了解计算机中的CAP理论。CAP是由Eric Brewer在2000年PODC会议上,提出分布式系统不能同时完全满足三个要求的假设,其中包括以下三个方面:
· Consistency:一致性,是指在分布式系统中的所有数据备份,在同一时刻是否具有同样的值。
· Avaliability:可用性,是指在集群中一部分节点故障后,集群群体是否还能响应客户端的读写请求。
· Partition tolerance:分区容错性,以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择。
和所有的分布式系统一样,区块链共识算法设计也是在权衡上面的三个因素。假设区块链中的节点能够立即确认交易数据,这就满足了CAP理论中的AP,可⻛险是失去了数据的强一致性,因为其他节点可能丢弃这个区块,因为区块所在的区块链分叉在竞争性的选举中失败了;如果是为了获得强一致性,即满足CP的话,那么客户端应该等待区块链中的大多数节点都接受了这笔交易后才能真正的接收它,这说明了这笔交易所在的分叉已经选举胜利,获得了大部分的共识,获得了强一致性。但是代价却是失去了可用性。
那么为什么没有CA这种情况呢?首先在分布式环境下,网络分区是一个自然的事实。因为分区是必然的,所以如果舍弃P,意味着要舍弃分布式系统,那这也就没有必要再讨论CAP理论了。所以在上述中,我们以系统在满足P的前提下,探讨了CP和AP两种情况下的得与失。
主流的共识算法概述
目前业界主流的区块链共识算法有工作量证明POW,权益证明POS,授权股权证明DPOS,用于Hyperledger的拜占庭算法PBFT等。下面将对这几种共识的典型代表进行讲解。
工作量证明POW
工作量证明POW(Proof-of-work)在区块链中最早被提及的是,2008年中本聪的比特币白皮书论文《A peer to peer electronic cash system》,并随后在2009年应用到比特币(Bitcoin)中。该共识算法的设 计理念是整个分布式系统的节点中,每个节点为整个系统提供计算能力(简称算力),通过一个竞争机制, 让计算工作完成最出色的节点获得系统的奖励,从而完成新生成货币的分配。
POW工作量证明需要满足三个要素,分别是:
· 工作量证明函数
在比特币中使用的是SHA256函数,是密码哈希函数家族中输出值为256位的哈希算法。
· 区块
在区块中会利用到merkle算法,将交易以树的形式进行组合,然后两两进行哈希运算,当为奇数的时候则多算上最后一个交易进行补充。依次进行以叶子节点向根节点的运算,并最终得到根节点的hash值。包含在区块头中。
· 难度值
难度值默认是每2016个区块调节一次(大概2周)。
难度系数 = 期望2016个区块生成所有的时间 / 实际所用的分钟数 = 20160 / 实际所用的分钟数
如果矿工可以比预期更快的构建区块,比如9分钟出一个块,套用公式:
难度系数 = (2016 * 10) / (2016 * 9) = 1.11
每个节点使用这个数值来计算下一个阶段2016区块的难度值:
Difficulty * 1.11 = new Difficulty
如果系数大于1(即区块出块速度大于预期),难度值将提高;
如果系数小于1(即区块出块速度小于预期),难度值降低。
POW工作量证明的流程如下:
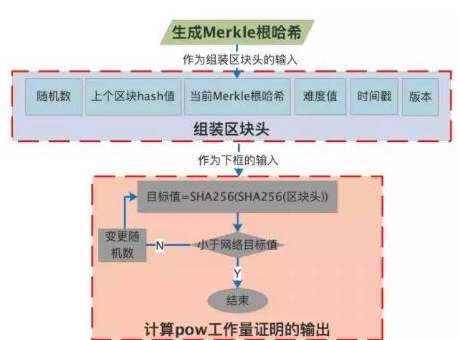
从流程图中可以看出,POW工作量证明的流程主要经历三步:
· 生成Merkle根哈希
· 组装区块头
· 计算出工作量证明的输出
在这里,我们以伪代码的形式去理解工作量证明的输出:
i. 工作量证明的输出 = SHA256(SHA256(区块头 + 变更的随机数))
ii. if (工作量证明的输出 >= 目标值),变更随机数,递归i的逻辑,继续与目标值比对。
iii. if (工作量证明的输出 >= 目标值),变更随机数,递归i的逻辑,继续与目标值比对。
最后,生成的符合难度的区块,将通过P2P传递到比特币的全网络节点并接收,添加到原有区块链的尾部。
由此,我们可以看到POW主要是通过CPU的算力来保证全网的共识安全。
权益证明POS
POS(Proof of Stake)即权益证明机制,最早出现在点点币的白皮书中,其核心思想是将货币持有人的数 目和持有的时间累计作为被选为共识节点的资本。
POS权益证明的运作主要包含两部分:
验证
在整个区块链网络中,参与者会把他们的代币投给他们认为有效的区块,如果他们跟网络中的大部分参与者达成一致,就可以获得和他们代币成正比的奖励;而试图作弊则要冒着失去保证金的⻛险,例如同时给两个不同的区块投票。
在POS中,金钱即力量;POS要求参与者将他们的网络代币作为安全保证金,使其与网络利益达成一致, 而不是通过消耗电能来加固网络安全。
下图为验证的过程:
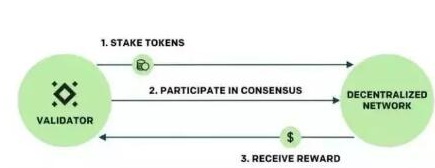
节点之间会通过接收、签名、发送消息来达成区块的共识。这种权益和节点基础设施的组合通常被称作验证者。通过这种方式注册的权益数量决定了相关验证者在共识过程中的影响力、以及验证者因工作而获得的奖励。
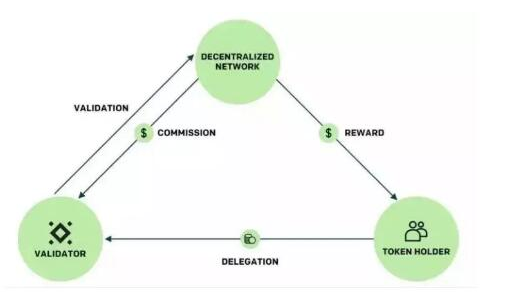
委托
将自己的代币拖尾给验证者,以换取获得奖励的份额。通常委托人会将代币存放在智能合约之中,指定他们想要委托的验证者。这样当该验证者获得验证奖励的时候,委托人也能获得与其委托代币数量成正 比的奖励。整个过程如下:
授权股权证明DPOS
授权股权证明机制(Delegated Proof of Stake)最早由Daniel Larimer提出,BitShares是第一个提出并采用DPOS的分布式账本。简单来说,DPOS的工作原理类似于董事会投票,给持币者一把可以开启他们所持股份对应的表决权钥匙,而不是给他们一把能够挖矿的铲子。
DPOS引入了⻅证人的概念,⻅证人可以生成区块,每个持股人都可以投票选举⻅证人。得到总票数前N(通常为101)的候选者,可以当选⻅证人。⻅证人的候选者名单每个维护周期(通常为1天)更新一次。
在BitShares的设计中,利益相关者可以选举一定数量的⻅证人来生成区块。每个账户允许对⻅证人投一票,这个投票过程被称为"批准投票"。选择出来的N个⻅证人被认为是对至少50%的投票利益相关者的代表。每次⻅证人产生一个区块,⻅证人将得到一定的出块奖励,如果⻅证人因为违规来没有生成区块,将不能得到奖励,并且会加入到"黑名单",从而再次成为⻅证人的机会会大大降低。
每组被选举出来的⻅证人的活跃状态在每一个周期将会被更新,随后这组⻅证人将会被解散。每个⻅证人给一个2秒的流转机会用来出块,当所有的⻅证人都流转完成后,该组⻅证人也会被解散。如果一个⻅证人在它的时间周期内没有产生区块,它的时间机会将会被错过,下一个⻅证人将产生下一个区块。任何节点都可以通过观察证人的参与率来监控网络的健康状况。历史上BitShares曾经维持了99%的⻅证参与。
所有的⻅证人会成为特权账户的共同签署者,该账户有权提出对网络参数的更改。这个账户被称为起源账户。这些参数包括从交易费用到块大小,⻅证支付和出块间隔等。在大多数的⻅证人批准了一项拟议的变更后,利益相关者将获得2周的审查期间,在此期间,他们可以对代表进行投票,并根据建议变更或者取消。选择这种设计是为了确保代表在技术上不具有直接的权利,所有对网络参数的更改最终都得 到利益相关者的批准。在DPOS中,我们可以说,行政的权利是由用户掌握,而不是代表或者证人。
拜占庭共识机制PBFT
PBFT(Practical Byzantine Fault Tolerance),意为实用拜占庭容错算法,是目前最常用的BFT算法之一。最早由Miguel Castro和Barbara Liskov在1999年提出,解决了原始拜占庭容错算法效率不高的问题,将算法复杂度由指数级降低到多项式级。
PBFT算法中主要有以下一些参数的定义:
client: 客户端,发出调用请求的实体
view:视图,内容为连续的编号
replica:网络节点
primary:主节点,负责生成消息序列号
backup:支撑节点,辅助整体共识过程
state:节点状态
PBFT算法要求整个系统流程要在同一个视图(view)下完成,所有节点采取一致的行动。一个客户端会发送请求
v是当前的view序号
t是对应请求的时间戳
i是replica节点的编号
r是执行结果
每一个replica会与每一个处于active状态的client共享一份密钥。密钥所占据空间较少,加上会限制active client的数量,所以不必担心以后出现的扩展性问题。
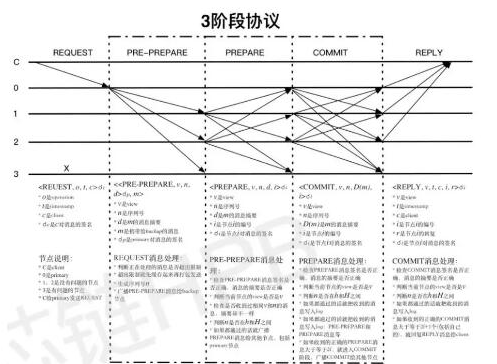
PBFT采用三阶段提交协议来广播请求给replicas,分别是pre-parpare、prepare,commit。pre- prepare阶段和prepare阶段用来把在同一个view里发送的请求排序,然后让各个replicas节点都认可这 个序列,照序执行prepare阶段和commit阶段用来确保那些已经达到commit状态的请求,即使在发生视图改变后,在新的view里依然保持原有的序列不变,比如一开始在view 0中有req 0,req 1,req 2三个请求依次进入了commit阶段,假设没有恶意阶段,那么这四个replicas即将要依次执行者三条请求并返回给client。但这时主节点问题导致view change的发生,view 0变成view 1,在新的view里,原本的req 0,req 1,req 2三条请求的序列将被保留。但是处于pre-prepare和prepare阶段的请求在view change发生后,在新的view里都将被遗弃。
下图是三阶段提交协议的时序图:
小结
本篇中主要讲解了区块链的主流共识算法,下篇中我们将讲解与区块链相关的密码学理论。敬请期待~
责任编辑:ct
-
区块链系统共识算法对比研究综述2021-06-17 1139
-
CCD与CMOS技术,这些是你所不了解的2021-06-01 1621
-
区块链共识算法的效能优化研究及总结2021-04-25 1199
-
你到底了不了解物联网2020-01-20 2161
-
主流区块链共识算法介绍2019-11-23 7425
-
区块链的共识算法是什么共有哪些类型2019-03-12 6378
-
区块链共识算法简要介绍2019-02-14 1817
-
区块链不止是炒币2018-12-04 3691
-
区块链热度不止,参考架构9个部分解密2018-09-06 3047
-
以DENC区块链为例讲解共识机制2018-08-30 4073
-
区块链技术有哪些共识算法?它们各有什么好处和坏处?2018-08-13 4819
-
区块链行业发展,金融领域应用方向?2018-08-06 3537
-
SHA在区块链中的应用2018-03-30 3139
-
什么是区块链 区块链有什么用2018-03-26 10856
全部0条评论

快来发表一下你的评论吧 !
