

对机器学习算法公平性的研究
人工智能
描述
机器学习公平性的研究真的走在正确的道路上吗?
随着人工智能的发展,机器学习的技术越来越多地被应用在社会的各个领域,来帮助人们进行决策,其潜在的影响力已经变得越来越大,特别是在具有重要影响力的领域,例如刑事判决、福利评估、资源分配等。
因此可以说,从社会影响层面来讲,考虑一个机器学习系统在做(有高影响力的)决策时,是否会对弱势群体造成更加不利的影响,至关重要。
那么如何评估一个机器学习系统的公平性程度呢?目前普遍的方法就是,拿着待评估的系统在一些静态(特别强调)的数据集上跑,然后看误差指标。事实上,现在有许多测试机器学习公平性的工具包,例如AIF360、Fairlearn、Fairness-Indicators、Fairness-Comparison等。
虽然这些工具包在一些任务中能够起到一定的指导作用,但缺点也很明显:它们所针对的都是静态的、没有反馈、短期影响的场景。这一点从评估方法中能够体现出来,因为数据集是静态的。
然而现实生活中大多数却是动态的、有反馈的场景,机器学习算法运行的背景往往对算法的决策具有长期的关键性影响。
因此针对机器学习算法公平性的研究,从静态公平到动态公平,从单线公平到有反馈的公平,从短期公平到长期公平,是重要且必要的一步。
近日,来自谷歌的数位研究人员针对这一问题,在近期于西班牙举办的ACM FAT 2020会议(关于计算机技术公平性的国际会议)上发表了一篇论文,并基于这篇论文的研究开发了一组模拟组件ML-fairness-gym,可以辅助探索机器学习系统决策对社会潜在的动态长期影响。

论文及代码链接:https://github.com/google/ml-fairness-gym
一、从案例开始
先从一个案例——借贷问题——开始。
这个问题是机器学习公平性的经典案例,是由加州大学伯克利分校的Lydia T. Liu等人在2018年发表的文章《Delayed Impact of Fair Machine Learning》提出的。

他们将借贷过程进行了高度的简化和程式化,从而能够让我们聚焦于单个反馈回路以及其影响。
在这个问题的程式化表示中,个体申请人偿还贷款的概率是其信用评分的函数。
每个申请人都会隶属一个组,每个组具有任意数量的组员。借贷银行会对每个组组员的借贷和还款能力进行观察。
每个组一开始有不同的信用评分分布,银行尝试确定信用评分的阈值,阈值可以跨组应用并对每个组进行调整,从而让银行最好地达到目标。
信用评分高于阈值的申请人可以获得贷款,低于阈值的申请人则被拒绝贷款。当模拟系统选择一个申请人时,他们是否偿还贷款是根据他们所在组的偿还概率随机决定的。
在该案例中,当前申请贷款的个人,可能会在未来申请更多的贷款,所以他们可以通过偿还贷款来提高他们的信用评分以及其所在组的平均信用评分。同样地,如果申请人没有偿还贷款,那么所在组的平均信用得分则会降低。
最有效的阈值设置取决于银行的目标。
如果一家银行追求的是总利润最大化,那么它可能会根据申请人是否会偿还贷款的可能性进行评估,来设置一个能够最大化预期回报的阈值。
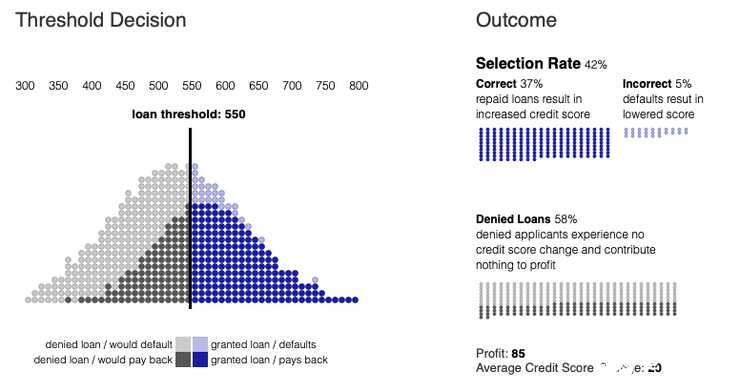
如果不考虑其他因素,银行将试图使其总利润最大化。利润取决于银行从偿还贷款中获得的金额与银行从违约贷款中损失的金额之比。在上图中,这个损益比是1比-4。随着损失相对于收益变得越大,银行将更加保守地发放贷款,并提高贷款门槛。这里把超过这个阈值的部分称为选择率。
而有的银行寻求的可能是能否对所有组做到公平。因此它们会尝试设置一个能够平衡总利润最大化和机会均等的阈值,其中机会均等的目标则是实现平等的 true positive rates(TPR,又称作灵敏度和召回率,衡量的是偿还过贷款的申请人将被给予贷款)。
在这一场景下,银行应用机器学习技术,基于已经发布的贷款和收入情况,来决定最有效的阈值。然而,由于这些技术往往关注的是短期目标,它们对于不同的组,可能会产生意料之外的和不公正的结果。
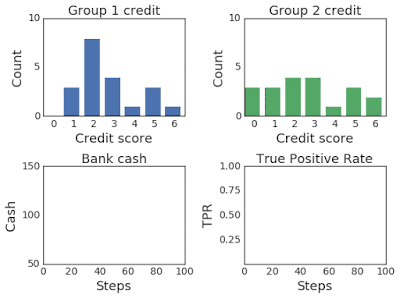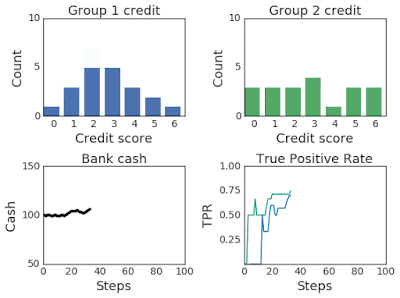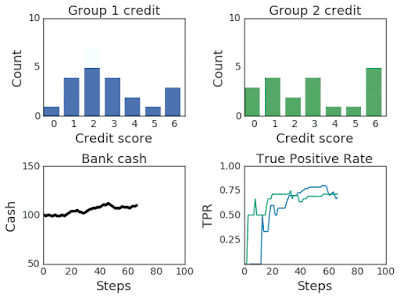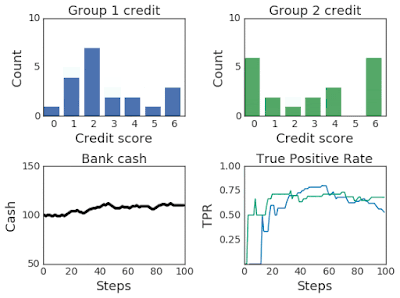
上面两幅图:改变两组超过100个模拟步骤的信用评分分布。第 2 组最初的信用评分较低,因此属于弱势群体。下面两幅图:左图为模拟过程中第一组和第二组的银行现金,右图为模拟过程中第一组和第二组的TPR。
二、静态数据集分析的不足之处
在机器学习领域中,评估借贷等场景的影响的标准方法就是将一部分数据作为“测试集”,并使用这个测试集来计算相关的性能指标。然后,通过观察这些性能指标在显著组之间的差异,来评估公平性。 然而我们很清楚,在有反馈的系统中使用这样的测试集存在两个主要的问题:
第一,如果测试集由现有系统生成,它们可能是不完整的或者会在其他系统中显示出内在的偏差。在借贷案例中,测试集就可能是不完整的,因为它仅仅只涵盖曾经被发放过贷款的申请人是否偿还贷款的信息。因此,数据集可能并没有包括那些此前未被批准贷款或者没有被发放贷款的申请人。
第二,机器学习系统的输出会对其未来的输入产生影响。由机器学习系统决定的阈值用来决定是否发放贷款,申请人是否偿还这个贷款会影响到它们未来的信用评分,之后也会反馈到机器学习系统中。 这些问题都突出了用静态数据集来评估公平性的缺陷,并促使研究者需要在部署了算法的动态系统中,分析算法的公平性。
三、可进行长期分析的模拟工具:ML-fairness-gym
基于上述需求,谷歌研究者开发出了ML-fairness-gym 框架,可以帮助机器学习从业者将基于模拟的分析引入到其机器学习系统中。这个组件已在多个领域被证明,在分析那些难以进行封闭形式分析的动态系统上是有效的。
ML-fairness-gym 使用了 Open AI 的 Gym 框架来模拟序列决策。在该框架中,智能体以循环的方式与模拟环境交互。在每一步,智能体都选择一个能够随后影响到环境状态的动作。然后,该环境会显示出一个观察结果,智能体用它来指导接下来的动作。
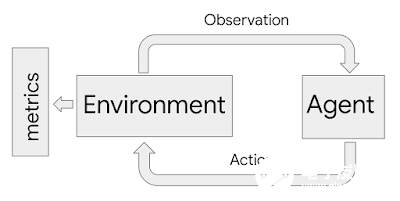
在该框架中,环境对系统和问题的动态性进行建模,而观察结果则作为数据输入给智能体,而其中智能体可以视为机器学习系统。
在借贷案例中,银行充当的角色是智能体。它以从环境中进行观察,从而接收贷款申请人以及他们的信用评分和组成员的信息,并以接受贷款或拒绝贷款的二分决策来执行动作。然后,环境对申请人是否成功偿还贷款进行建模,并且据此来调整申请人的信用评分。ML-fairness-gym 可以通过模拟这些结果,从而来评估银行政策对于所有申请人的公平性的长期影响。
四、公平性并不是静态的:将分析扩展到长期影响
由于Liu 等人对借贷问题提出的原始公式,仅仅考量了银行政策的短期影响结果,包括短期利润最大化策略(即最大化奖励智能体)和受机会均等(EO)约束的策略。而研究者使用 ML-fairness-gym ,则能通过模拟将分析扩展到长期影响。
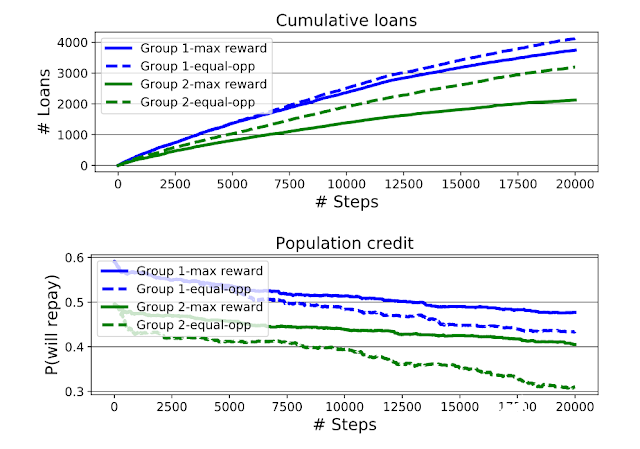
上图:最大化奖励智能体和机会均等智能体的累计放贷额,按申请人所隶属的组划分,蓝色代表第 1 组,绿色代表第2组。下图:模拟过程中的组平均信用评分(由各组有条件的偿还概率量化而得出)。机会均等智能体增加了第2组的贷款通过率,但是加大了第2 组与第1 组合的信用评分差距。
谷歌研究者基于对上述借贷问题的长期分析得到了两个发现:
第一,正如Liu等人所发现的,机会均等智能体(EO 智能体)有时会对弱势群体(第2组,最初的信用评分更低)设置比最大化奖励智能体更低的阈值,从而会给他们发放超出原本应该给他们发放的贷款。 这导致第2组的信用评分比第 1 组下降的更多,最终造成机会均等智能体模拟的两组组之间的信用评分差距比最大化奖励智能体模拟的更大。
同时,他们在分析中还发现,虽然机会均等智能体让第2 组的情况似乎变得更糟,但是从累计贷款图来看,弱势的第2 组从机会均等智能体那里获得了明显更多的贷款。
因此,如果福利指标是收到的贷款总额,显然机会均等智能体对弱势群体(第 2组)会更有利; 然而如果福利指标是信用评分,那么显然机会均等智能体将会让弱势群体的信用变得越来越差。
第二,在模拟过程中,机会均等约束(在每一步都在每组间强制实施均等的 TPR)并不能使TRP在总体上均等。这个可能违反直觉的结果可以看作是辛普森悖论的案例之一。
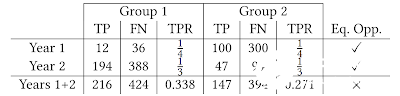
辛普森悖论的案例之一。TP 为真阳性分类,FN 对应假阴性分类,而TPR则是真阳性率。在第1、2年中,借贷者实施能够在两组间实现均等TPR的政策。但两年的TPR总和并没有实现均等TPR。
如上表所示,每两年的均等TPR并不意味着TPR总体均等。这也显示了当潜在人群不断演变时,机会均等指标解释起来会很难,同时也表明非常有必要用更多详细的分析来确保机器学习能产生预期的效果。
上述内容,只讨论了借贷问题,不过据谷歌研究人员表示,ML-fairness-gym 可以用来解决更广泛的公平性问题。在论文中,作者还介绍了其他一些应用场景,感兴趣者可以去阅读论文原文。
ML-fairness-gym 框架在模拟和探索未研究过“公平性”的问题上,也足够灵活。在他们另外的一篇论文《Fair treatment allocations in social networks》(社交网络中的公平待遇分配)中,作者还研究了社交网络中精准疾病控制问题的公平性问题。
-
平衡创新与伦理:AI时代的隐私保护和算法公平2024-07-16 1234
-
Harvard FairSeg:第一个用于医学分割的公平性数据集2024-01-25 1448
-
如何去获取Arm Spinlock的公平性呢2022-08-04 2420
-
机器学习模型在功耗分析攻击中的研究2021-06-03 852
-
人工智能的算法公平性实现2019-11-06 3298
-
亚马逊与科学基金会合作,专注于开发AI和机器学习公平性的系统2019-03-27 2314
-
MIMO OFDM系统公平性资源分配算法2018-03-13 779
-
云环境下公平性优化的资源分配方法2017-12-11 1020
-
基于公平性的D2D时隙调度算法2017-12-05 1093
-
基于最大最小公平性的功率分配算法2017-12-04 1677
-
异构多核下兼顾应用公平性和能耗的调度方法研究2017-11-30 905
-
一种提高IEEE 802.11吞吐量和公平性的自适应优化算法2010-02-10 818
-
基于分层时间有色Petri网的支付协议公平性分析2009-11-17 1021
-
高速TCP变种协议与DCCP协议的公平性研究2009-03-23 525
全部0条评论

快来发表一下你的评论吧 !
