

TensorFolw人工智能影像诊断平台的工作原理
电子说
描述
使用人工智能来辅助病理医生对样本进行诊断,不仅能够大幅度提高医师的诊断效率,而且可以减少漏诊,提高诊断准确率。
数字化的病理影像能够观察到组织细胞形态,在最高数字扫描时,文件尺寸达到GB量级,需要利用人工智能和系统工程学的技术去突破这些困难。
在这篇文章当中,我将会从人工智能系统的构建方法角度来入手,举例消化道病理影响辅助系统研发过程中的技术细节。
当然,这是相对陌生的医疗科技领域知识,为了读者能更快的理解和吸收,全篇也会围绕产品经理的角度去解。
一、什么是病理?
病理就是通过分析病人的组织,细胞和体液样本来诊断疾病。
那么,病理对于临床医生提供进一步治疗策略的金指标。
这里有个容易混淆的是AI医学影像,并不是所有都是从CT、X光、B超等分析得出。就拿胃癌筛查来说,它的病理影像通过扫描仪扫描组织放大形成大概1.4GB影像来进行分析判断的。

不同病种的病理来源
病理影像都是与众不同的,这也是技术上的挑战。
那么在进行病理判断之前,我们需要建立一套训练模型,通过医生标注的图像进行增强训练以及数据处理。
二、TENSORFOLW工作原理
我们讲解TensorFolw训练模型时,我们要了解整个的深度学习的流程。

简易工作流程
数据源一般来自医院的PACS、RIS系统等,形成数据队列后进行数据增强图像方向的鲁棒性。
另外,我们要注意扫描仪的倍数,会造成在不同样的倍数情况下图像的鲁棒性。
然后利用TensorBoard来进行模型监控,TensorBoard是一个可视化工具,能够有效地展示Tensorflow在运行过程中的计算图、各种指标随着时间的变化趋势以及训练中使用到的数据信息。
再通过TensorFolw导出(病理)模型交给生产环境推理框架(TensorFolw Serving)进行自动处理。
那tensorfolw serving是怎么工作的呢?

Tensorserving工作流程
tensorfolw serving把病理切片分成坐标标记的小块切分之后把节点让一个map每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。
map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。
这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。
然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
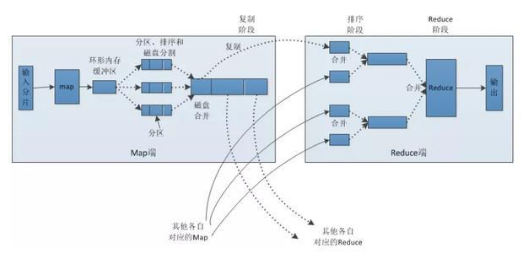
MAP与reduce机制再将分区中的数据拷贝给相对应的reduce任务。Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。
如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。
其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。
最后返回数据到后端。
同样的流程可以迁移学习,病理图像有很多相似的地方,腺、息肉、囊肿等等都可以同理应用。
-
人工智能是什么?2015-09-16 0
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 0
-
人工智能已经进入医疗领域2017-05-24 0
-
全国医疗器械采购网分享:行业论坛临近 医疗人工智能加速落地2017-09-15 0
-
数据对人工智能发展的重要性2017-10-09 0
-
人工智能就业前景2018-03-29 0
-
基于人工智能的创新教学云平台建设2018-04-16 0
-
电销机器人成为2018人工智能最热产业之一2018-05-21 0
-
人工智能机器学习程序可分析患者肺癌肿瘤影像2018-11-08 0
-
解读人工智能的未来2018-11-14 0
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 0
-
如何构建人工智能的未来?2021-03-03 0
-
人工智能芯片是人工智能发展的2021-07-27 0
-
人工智能+医学影像是将目前最先进的人工智能技术2020-09-29 3425
-
人工智能的工作原理和特点2024-07-01 2413
全部0条评论

快来发表一下你的评论吧 !
