

通过利用FPGA器件和EP1s25F672I7芯片实现LDPC码编码器的设计
FPGA/ASIC技术
描述
引言
低密度奇偶校验(Low Density Parity Check Code,LDPC)码是一类具有稀疏校验矩阵的线性分组码,不仅有逼近Shannon限的良好性能,而且译码复杂度较低, 结构灵活,是近年信道编码领域的研究热点,目前已广泛应用于深空通信、光纤通信、卫星数字视频和音频广播等领域。LDPC码已成为第四代通信系统(4G)强有力的竞争者,而基于LDPC码的编码方案已经被下一代卫星数字视频广播标准DVB-S2采纳。
编码器实现指标分析
作为前向纠错系统的重要部分,设计高速率低复杂度LDPC码编译码器成为提高系统性能的关键。对LDPC码来说,其编码复杂度相对较大,编码器的设计与实现是首要任务,也是译码器设计与实现的前提,有着十分重要的作用。
编码速率与复杂度是评价LDPC编码器好坏的重要指标。考虑高清晰度电视(HDTV)标准在分辨率为1920×1080,帧率为60帧/s,每个像素以24比特量化时,总数据率在2Gb/s的数量级。采用MPEG-2压缩,要求数据率大约在20~40Mb/s。
编码器设计思路
设LDPC码检验矩阵为H、生成矩阵为G 。传统的编码方法是利用生成矩阵G直接进行编码。由于G并不具有稀疏性,直接编码的复杂度与码长N的平方成正比。本文的编码器采用RU编码算法。该算法通过对交换校验矩阵行列的位置,保持矩阵的稀疏性,利用交换行列后的校验矩阵进行编码,有效降低了编码的复杂度。经过行列交换的校验矩阵具有近似下三角形式,如图1所示。
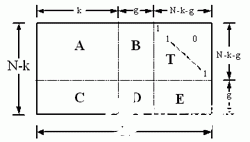
图1 交换校验矩阵
设信息序列为s,码字为C利用图1的矩阵可对信息序列s进行编码。码字分为三部分:C=(s,p1,p2),其中s是信息比特序列,长度为k;p1和p2是校验比特序列,长度分别为g和N-k-g。校验比特序列p1、p2计算公式如下:
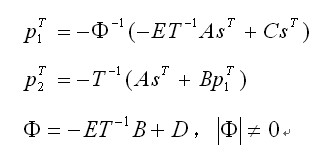
编码流程如图2所示。
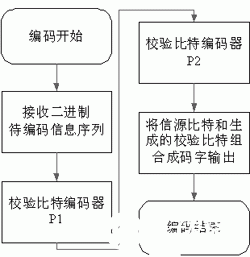
图2 编码流程图
设计LDPC编码器的时候注意:在RU算法中,对校验矩阵进行行列交换,转化为近似下三角形式称为编码预处理过程。给定一个校验矩阵,编码预处理过程和矩阵的计算只需要做一次,所以可先用软件完成。实际的编码计算通过硬件实现。这样做有利于提高编码硬件实现的效率。
LDPC码编码器实现
LDPC码编码器硬件结构
基于RU算法的LDPC编码实现过程主要是计算p1、p2的过程。设计编码器时,为了提高编码速度,将可以同时计算的步骤作并行处理,得到编码器的硬件结构如图3所示。
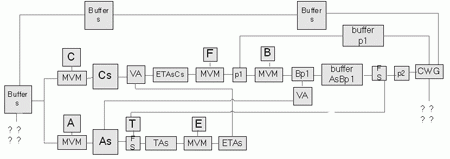
图3 LDPC码编码器结构
图3中A、B、C、E分别代表图1中相应的矩阵,F代表Φ矩阵。从图3可知,LDPC编码器主要由缓冲器(buffer)、矩阵向量乘法器(MVM)、矩阵加法器(VA)、前向迭代运算器(FS)、向量合成器(CWG)等运算单元以及存储各个矩阵相关信息的存储器组成。因为前向迭代运算基本上是矩阵与向量的乘法计算,所以矩阵向量乘法是LDPC编码过程最核心的单元。
分析图3可知,编码过程中,Cs与As的计算是同时进行的,其他的操作都是串行进行的。由于行列交换保持了矩阵的稀疏性,所以与A、B、C、E矩阵的相关运算是稀疏矩阵的运算,存储矩阵所需的空间少同时实现的复杂度低和运算速度快。Φ是g×g的矩阵,由于在编码预处理过程中保证了g尽量小,所以与Φ矩阵相关的运算也是比较快的。
LDPC码编码器复杂度
表1和表2描述了编码器计算校验序列p1、p2的流程及相应的复杂度。

表1 p1的计算

表2 p2的计算
从表1和表2可知RU算法的复杂度与N+g2成正比,g越小,编码复杂度越低。所以对校验矩阵进行行列交换时,使g尽量小是进一步降低编码复杂度的关键。
表1中序号2与表2中序号4的操作涉及到下三角矩阵T。由于T-1也是下三角矩阵,为了降低复杂度,可采用前向迭代进行计算。例如:假设Qx=y,Q为下三角矩阵,求x。计算过程如下:

编码器核心模块——矩阵向量乘法器(MVM)的实现
矩阵与矩阵的乘法运算以及前向迭代运算实质上都是矩阵与向量的乘法。下面举例说明矩阵向量乘法器硬件实现的过程:
假设,对于LDPC编码器,如何有效率地存储各个矩阵的信息是降低复杂度的关键。下面给出一种矩阵存储的方案:矩阵存储器中记录“1”在行中的位置以及对应行行重,如表3所示。例如矩阵X第3行的“1”元素,在行中的位置为“0”,该行的行重为1。由于LDPC编码过程中使用的矩阵大多是稀疏矩阵,所以采用该矩阵存储方案能比较有效地利用存储的空间并有利于矩阵与向量乘法的快速实现。
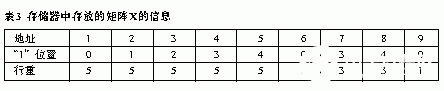
矩阵X每行中“1”的位置可看作选择向量s相应元素的地址索引,将选择的所有元素相加作和,即完成X中某行与向量的运算。由于涉及的运算都是二进制加法,相加作和操作可以作如下简化:根据矩阵每行“1”的位置选择向量s的元素。统计被选择的元素中“1”的个数,若结果为奇数则说明相加的结果为“1”,否则说明相加的结果为“0”。判断结果为奇数或者偶数可由其二进制形式的末位是“1”或者“0”得到。通过设置两个计数器分别计算各行行重和选择的向量s相应位置的元素中“1”的个数,即可实现乘法单元的运算。
矩阵向量乘法器的硬件结构如图4所示。
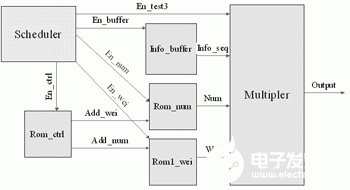
图4 矩阵向量乘法器的硬件结构
从图4可知矩阵向量乘法器包括以下六个部分:调度单元(Scheduler),产生各模块单元的使能信号;缓存单元(Info_buffer),对输入信息序列进行缓存处理;存储器控制单元(Rom_ctrl),产生存储器的地址信号;“1”位置存储器(Rom_num),存储矩阵各行“1”的位置;行重存储器,存储矩阵相应各行行重;乘法单元(Multipler),进行向量乘法运算,最后输出码字。
矩阵向量乘法器仿真结果验证
在Quartus II环境下,实现output=Xs,得到如图5所示时序图。
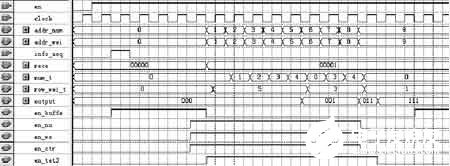
图5 output=“Xs仿真时序图”
图5中“en”是使能信号,“clock”是时钟信号,addr_num、addr_wei分别为两个存储器的地址信号,info_seq是输入信息信号,rece是信息信号经过缓存后的输出信号,num_t是“1”在各行的位置信息,row_wei_t是相应各行的行重,output是矩阵与向量相乘的结果。由图5可知,output=[1 1 1],信号输出有一个时钟周期的延时,仿真结果正确。
编码器方案验证与优缺点分析
本文利用FPGA实现了基于RU算法的编码器设计实现。在Quartus II软件环境下对LDPC编码器进行仿真,使用Stratix系列EP1s25F672I7芯片,对码长为504的码字进行编码。编码器占用约9%的逻辑单元,约5%的存储单元,综合后时钟频率达到120MHz,数据吞吐率达到33Mb/s,基本符合编码器设计的要求。该编码器结构是一种通用的设计方案,可以应用于各种不同的LDPC编码中,但由于其采用通用的编码算法,实现的复杂度高于某些特殊结构的LDPC码编码器,比如准循环LDPC码。另外通过优化时序和编码结构,可以进一步提高本文的编码器的编码速度。
责任编辑:gt
-
基于EP2S60型FPGA芯片的LDPC码快速编码的实现设计2020-09-21 2052
-
关于LDPC编码的全面了解2020-11-02 51847
-
800Mbps准循环LDPC码编码器的FPGA实现2012-08-11 2841
-
采用FPGA增量式编码器实现接口设计2019-06-10 2634
-
基于RU算法的编码器是如何设计并实现的?2021-04-30 1619
-
基于FPGA 的(3,6)LDPC 码并行译码器设计与实现2009-06-06 719
-
基于IEEE802.16e的LDPC编码器设计与实现2010-07-06 785
-
利用FPGA实现基于RU算法编码器(LDPC编码器)的设计2007-08-15 2233
-
一种输出格式可控的多码率LDPC编码器实现2009-11-25 1918
-
基于IEEE802.16e标准的LDPC编码器设计与实现2011-12-07 1168
-
LDPC码编码器的FPGA实现2016-05-09 953
-
基于FPGA 的LDPC 码编译码器联合设计2017-11-22 5333
-
基于卷积LDPC码编码凿孔算法2018-01-16 1049
-
S7-300可通过PROFINET读取增量编码器脉冲数2021-03-11 2997
-
如何使用FPGA实现结构化LDPC码的高速编译码器2021-03-26 1280
全部0条评论

快来发表一下你的评论吧 !
