

通过并行流水线结构实现直接型FIR滤波器的系统设计方案
调谐/滤波
描述
1 、并行流水结构FIR的原理
在用FPGA或专用集成电路实现数字信号处理算法时,计算速度和芯片面积是两个相互制约的主要问题。实际应用FIR滤波器时,要获得良好的滤波效果,滤波器的阶数可能会显著增加,有时可能会多达几百阶。因此,有必要在性能和实现复杂性之间做出选择,也就是选择不同的滤波器实现结构。这里运用并行流水线结构来实现速度和硬件面积之间的互换和折衷。
在关键路径插入寄存器的流水线结构是提高系统吞吐率的一项强大的实现技术,并且不需要大量重复设置硬件。流水线的类型主要分为两种:算术流水线和指令流水线。对FPGA设计,逻辑功能是面向特定应用的,因此,采用需要较少额外控制逻辑的算术流水结构。 流水线结构就意味着将数字处理算法分割成时间上前后相连的多个处理片段.并且在段与段之间加信号寄存器来缓冲。这些段和段之间的缓冲就构成了流水线。系统原来的运算量被分割成k个部分,分别由流水线的k个段来外理。一旦前面的任务通过了流水线的第一段,新的任务就可以进入流水线。设系统不加流水时的延时是D,则加上流水后,每隔D/k个时间单位就可以启动新的任务。要实现流水线的性能提升应满足3个条件:
①运算量均匀分成延时一致的k个部分;
②输人数据有大量重复的运算;
③重复的运算前后没有相关性。
并行结构就是以重复相同的结构,对同时满足并行运算条件的并行算法在硬件上进行实现的结构。并行结构运用起来的主要难点如下:一,并行结构占用更多的面积。二,相互并行的各计算部分在相互交换数据时,需要额外的控制和互联结构。但是,在芯片工艺尺寸不断减小的今天,并行结构成为设计高速、低延时数据处理系统的首选。控制和互联结构的复杂性取决于算法和对算法的划分方法。FIR滤波器本身就适合并行处理,但是对于占用时间和芯片面积都很大的乘法器来说,用全并行来实现FIR滤波器是不经济的。
FIR滤波器以其设计简单、稳定性好、方便实现、线性相位等优点往往成为首选,甚至是唯一的选择。FIR滤波器用差分方程表示为:
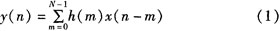
FIR滤波器直接型结构如图1。
2 、实现方法
现场可编程门阵列(FPGA)具有体系结构和逻辑单元配置灵活、集成度高以及设计开发周期短等优点,因此,选用FPGA来验证并实现本滤波器结构。VHDL是一种硬件描述语言,主要用于描述数字系统的结构、行为、功能和接口,与FPGA相结合后,表现出更加强大与灵活的数字系统设计能力。用VHDL完成数字系统的功能描述,用FPGA来实现是一种实用方便的软、硬件结合方式。从硬件描述语言到FPGA配置数据文件是由综合工具以及布局、布线工具来完成的。数字系统的功能最终能否实现以及性能如何,取决于数字系统的算法结构,也取决于综合工具、布局和布线工具,还有器件性能。但是,如果数字系统的算法设计不好,就会有更多的设计反复。这里对FIR滤波器提出一种处理时间和所用芯片面积可以互换的结构,在最初的设计时,就能对其处理能力有所估计,减少了设计的反复。
对于FIR滤波器,Xilinx提供了两个软核,一个是基于分布式运算的,另一个是基于单路的乘加运算。对于大阶数、高采样率的滤波器,这两种滤波器结构都不太适合。
为了提高FIR滤波器的吞吐量,可用并行加流水线的结构来实现FIR滤波器,如图2所示。流水结构用于提高吞吐量率,并行结构可以减小处理延时。利用流水和并行结构调整滤波器性能使其满足实际应用要求。这里实现三级流水和二路并行的FIR滤波器。三级流水分别对应取数、乘法和累加。主要由双口RAM、乘法器、累加器、控制逻辑和流水线间的寄存器组成,还有数据写入模块(图中未画)。
用两块RAM分别存放FIR系数和数据的前N个样值点,这两个RAM要求有一个写数据和一个读数据的双端口RAM。数据写入模块负责把所要滤波的数据轮换地写入两个双口RAM;FIR的系数也按偶数下标和奇数下标分别写入两个系数RAM,实现时是预先配置的。在实现滤波时,如图1所示对数据移位是不现实的。因此,用交联网络结合控制模块实现第一级流水--取数,完成给下一级流水线正确送数的目的。第二级流水是两个并行的乘法器,完成乘法运算。第三级流水是一个累加器;在控制逻辑的控制下,对乘法器输出结果进行正确的累加运算。
完成结构设计后要进行时序设计。数据写入模块的时钟是根据数据源产生数据的速率而定的。而流水线的工作时钟频率要求大于数据产生时钟频率的N/2倍,N是滤滤器阶数,2是并行度。也就是要求流水线在数据产生的一个周期内能完成一次FIR滤波器输出的计算。其中的控制逻辑是流水线正常运行的关键。数据流水线上的各种时序要求都要由其产生,包括读数据地址、读系数的地址、交联网络的控制和流水线结构的输出。其VHDL的端口描述如下:

系数地址由计数器产生,计数器周期是滤波器的阶数除以并行度,由first_data_address的第0位的边沿触发,以重新从0开始计数。数据RAM的地址加上计数器的值。两个RAM地址因当前输入滤波数据的存放位置,可能相同也可能相差1。交联网络的控制信号是计数器的最低位。累加器输出的使能信号是在计数到滤波器的阶数时产生的,而后经过延时给到累加器。累加器清零信号在这里产生要比累加器中用其他方法方便得多。
交联网络也是设计的重点。对于并行处理结构,各单元之间数据的共享和通信是限制并行度的主要原因。在并行度为2的结构中,只要轮流交换系数就可以了。但是对更高的并行度,这一通信网络的延时是相当大的,这也是把它单独列为滤波器的流水线的一级的主要原因。
还要注意的是:有符号数常用补码表示。在对有符号数进行扩展时,要扩展最高位。对乘法器的输出一般要进行扩展,以避免累加器溢出。
对于乘加运算,有一种分布式计算方法,也就是把乘法进一步分解为部分和(二进制系数的每一位和输入数据相与的结果)。当乘加运算的一个乘数是已知常数时,分布式乘加运算会很节省资源。因为系数固定,与运算的结果是在运算前可知的,这样零位与数据相与的结果是不参与加运算的,从而实现无乘法器的滤波器。这里不选用这种方法,原因有二:其一,分布式运算将使滤波器难以重配:其二,基于FPGA的硬件乘法器较综合得来的乘法器性能更佳。
3、 仿真及测试
用VHDL语言描述全部电路模块后,输入系数1、2、3、4、5和数据-l、-2、3、4等进行测试.用Mod-elsim进行仿真,其结果如图3所示。

可以看出,模块能正确进行计算,从数据输入到数据输出约延时2个数据时钟.这主要是前面的数据输入模块的延时。乘加部分采用数据时钟的N/2倍,其延时与滤波器的阶数成比例,但不会超过一个数据时钟周期。
然后,对VHDL描述就Xilinx的Spartan-3进行综合和测试。可以得出表1所示的测试结果,其中第一行为并行流水结构所设计的滤波器,第二行是采用Xilinx提供的软核设计的滤波器。
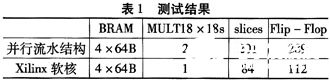
可以看出,除了增加一个乘法器外,逻辑块和触发器都增加了一倍多。用这种结构设计的滤波器面积增加了一倍,速度性能也提高了一倍。以上两种滤波器可以应用在语音信号处理中--让语音信号通过低通滤波器以获取语音的低频分量。相对而言,并行流水结构能实现比Xilinx软核更高阶数的滤波器。在听觉上,经过两种滤波器(相同阶数)的语音信号没有太大差别。
4、 结束语
本文在运算层次上,依据流水和并行运算结构实现直接型FIR滤波器。如果在设计滤波器时,结合级联型和直接型两种滤波器结构,那么也能实现同样的并行和流水的效果。实际上,还可在更低层次的乘法运算时,对部分和也用并行和流水结构来实现。这些结构的选择都依据性能要求和实现的复杂性来具体确定。
作为实现现代高性能处理器的方法,并行和流水结构各有特点。并行是以面积换速度。流水是以延时换速度,采用这两种结构,就能在面积、速度、延时之间灵活互换。
责任编辑:gt
-
在FPGA体系结构能够实现的并行运算2021-12-15 6616
-
怎么利用FPGA实现FIR滤波器?2021-04-29 1934
-
如何设计一个脉动阵列结构的FIR滤波器?2021-04-20 2096
-
如何使用FPGA实现实现高速并行FIR滤波器2021-01-28 1235
-
并行FIR滤波器Verilog设计2020-09-25 2695
-
一种基于分布式算法的低通FIR滤波器2017-11-24 3797
-
基于FPGA的硬件加速器的FIR流水结构滤波器实现、设计及验证2017-11-18 2240
-
串行结构的FIR滤波器设计 (含有代码 文档资料)2017-04-20 2780
-
串行结构的FIR滤波器设计(含文档 代码资料)2017-04-14 3734
-
基于位并行DA结构的高速FIR滤波器2017-01-07 737
-
基于流水线的并行FIR滤波器设计2011-07-18 1052
-
基于MATLAB和Quartus II 的FIR滤波器设计与2009-11-30 891
-
基于FPGA流水线分布式算法的FIR滤波器的实现2009-06-20 1773
-
基于流水线技术的并行高效FIR滤波器设计2009-03-28 1073
全部0条评论

快来发表一下你的评论吧 !
