

清华大学的存算一体化架构和并行加速方法专利
电子说
描述
清华大学基于多个忆阻器阵列的全硬件完整存算一体系统,能够高效的运行卷积神经网络算法,证明了存算一体架构全硬件实现的可行性,对今后AI算力瓶颈的突破有着极大意义。
集微网消息,近日来,清华大学微电子学研究所、未来芯片技术高精尖创新中心的钱鹤、吴华强教授团队与合作者在《自然》在线发表了题为“Fully hardware-implemented memristor convolutional neural network”的研究论文,报道了基于忆阻器阵列芯片卷积网络的完整硬件实现。该成果所研发的基于多个忆阻器阵列的存算一体系统,在处理卷积神经网络时的能效远高于GPU,大幅提升了计算设备的算力,成功实现了以更小的功耗和更低的硬件成本完成复杂的计算。
随着以人工智能为代表的信息技术革命兴起,基于各种深度神经网络的算法可以实现图像识别与分割、物体探测以及完成对语音和文本的翻译、生成等处理。然而深度神经网络算法是一类以数据为中心的计算,实现该算法的硬件平台需要具有高性能、低功耗的处理能力,这就对集成电路芯片技术提出了的更高要求。目前传统实现该算法的硬件平台是基于存储和计算分离的冯诺依曼架构,这种架构在计算时需要将数据在存储器件和计算器件之间来回搬移,因此在包含大量参数的深度神经网络的计算过程中,该架构的能效较低。为此,开发一种新型计算硬件来运行深度神经网络算法成为当前亟需解决的问题。
基于这种情况,清华大学团队于2019年11月7日提出一项名为“基于忆阻器的神经网络的并行加速方法及处理器、装置”的发明专利(申请号:201911082236.3),申请人为清华大学。此专利针对复杂神经网络的运算,提供了一种基于忆阻器的存算一体化架构和并行加速方法,并在该系统架构上高效运行了卷积神经网络。
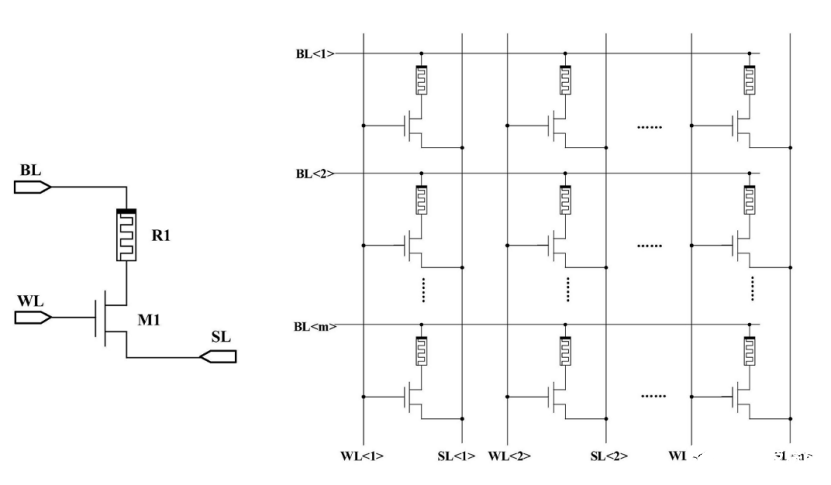
图1 忆阻器单元及阵列示意图
图一展示了忆阻器单元及阵列,是此专利所用的核心硬件结构。忆阻器是一种可以通过施加外部激励,调节其电导状态的非易失型器件。由忆阻器构成的阵列可以并行的完成乘累加计算,并同时进行计算和存储,因此基于这种特性可以对大量数据实现存算一体计算。由于乘累加是运行神经网络需要的核心计算任务。将忆阻器的的电导表示为权重值,可以实现高能效的神经网络运算,图1右侧展示的忆阻器阵列即为一个m行n列的神经网络权重矩阵。
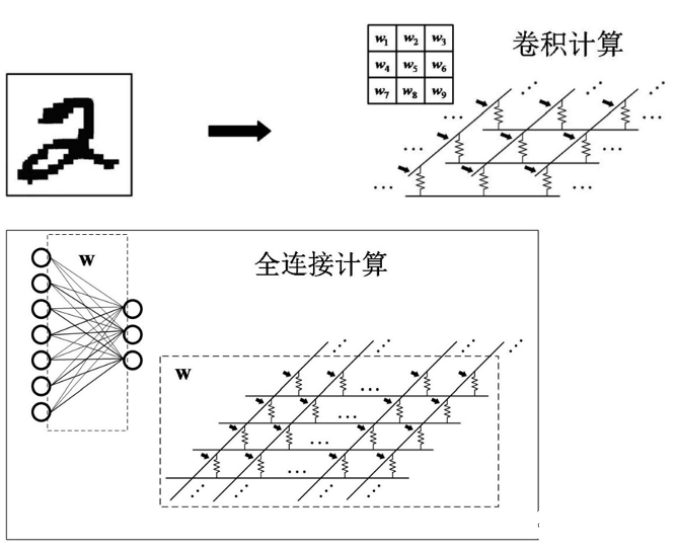
图2 基于忆阻器阵列的卷积神经网络卷积计算与全连接计算示意图
卷积神经网络包括卷积层、下采样层、池化层和全连接层,每一层都需要做模块化的功能处理。在卷积层中,通过卷积核替代标量的权重,加上偏置量,并在每一层添加非线性激活函数,通过多个卷积层来解决较为复杂的问题。图2展示了基于忆阻器阵列的卷积计算和全连接计算示意图,用一个忆阻器阵列来实现一个卷积层的卷积计算,如对输入图像 “ 2”进行卷积处理,同时该卷积层包括多个卷积核,每个卷积核对应忆阻器阵列的一行,且每行的多个忆阻器分别用于表示一个卷积核的各个元素的值。而对于全连接型的计算,该忆阻器阵列的每一列用于接收全连接层的输入,各行用于提供全连接层的输出,每一行的多个忆阻器分别用于表示该行的输出对应的各个权重。
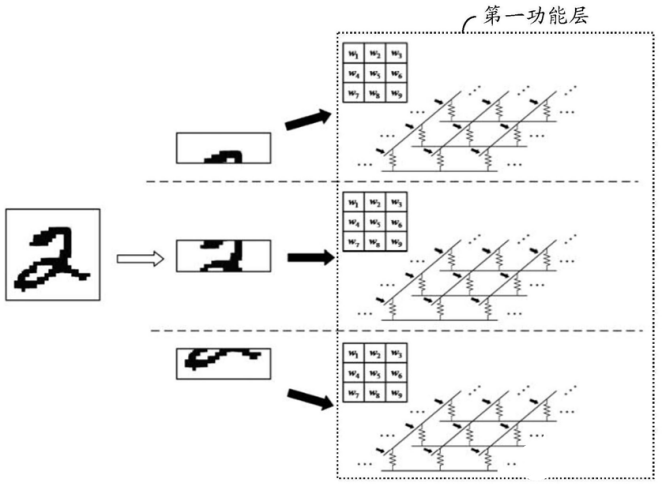
图3 基于忆阻器的神经网络并行加速示意图
基于忆阻器的神经网络并行加速示意图如图3所示,主要将多个第一忆阻器阵列并行地执行卷积层的操作,并将结果输出至第二功能层。通常卷积层需要多个子输入数据,可以按照任意顺序分别提供给多个第一忆阻器阵列,由于各子输入数据由忆阻器阵列进行卷积处理需要耗用的时间基本相同,因此加快卷积层的处理速度,即加快神经网络的处理速度,利用并行处理方式可以大大缩短处理时间。
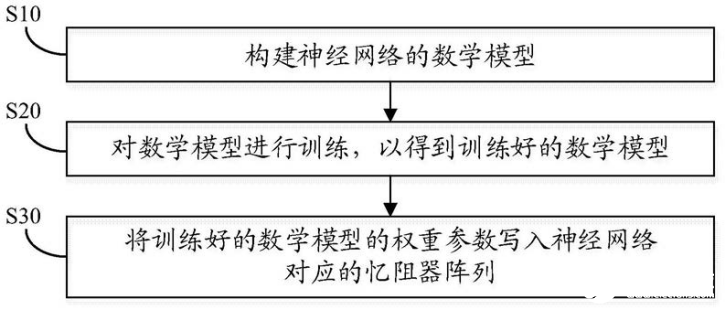
图4 神经网络片外训练方法
图4展示了基于忆阻器阵列的神经网络片外训练方法,首先利用数学软件构建神经网络的数学模型,进而基于处理器和存储器等运行及训练上述数学模型,最后将训练好的数学模型的权重参数写入神经网络对应的忆阻器阵列,此时则可执行并行加速的计算过程,并同时对数据进行存储,实现存算一体加速。
随着计算存储一体化的发展趋势,基于忆阻器在硬件架构方面的革新,将数据存储单元和计算单元融合为一体,能显著减少数据搬运,极大提高计算并行度和能效。清华大学的钱鹤、吴华强教授团队搭建的这一基于多个忆阻器阵列的全硬件完整存算一体系统,并能够高效的运行卷积神经网络算法,并验证了图像识别功能,证明了存算一体架构全硬件实现的可行性,对今后AI算力瓶颈的突破有着极大意义。
-
清华大学携手华为打造业内首个园区网络智能体2025-05-07 1085
-
济南市中区存算一体化智算中心上线DeepSeek2025-02-19 1536
-
存算一体化与边缘计算:重新定义智能计算的未来2024-11-12 1724
-
什么是通感算一体化?通感算一体化的应用场景2024-01-18 16928
-
忆阻器(RRAM)存算一体路线再次被肯定2023-10-26 3552
-
清华大学研发出存储芯片“诊疗一体化”技术2023-10-18 1918
-
我国芯片突破!清华大学全球首枚!2023-10-14 1346
-
清华大学重磅消息:全球首颗!我国芯片领域取得重大突破2023-10-11 1652
-
关于存算一体,我们和ChatGPT聊了聊2023-02-09 2894
-
2023年存算一体是芯片设计的技术趋势2023-01-13 3530
-
比存算一体更进一步,“感存算一体化”前景如何?2022-06-08 7850
-
光机电一体化综合性实验2021-09-01 1060
-
基于RISC-V开放架构的存算一体化芯片解决方案2021-06-23 3682
-
知存科技数模混合存算一体AI芯片专利解析2019-12-24 8363
全部0条评论

快来发表一下你的评论吧 !
