

基于代码的机器学习是什么,它的原理如何
电子说
描述
(文章来源:CDA数据分析师)
随着IT组织的发展,其代码库的大小以及开发人员工具链的复杂性也在不断增长。工程负责人对其代码库,软件开发过程和团队状态了解的非常有限。通过将现代数据科学和机器学习技术应用于软件开发,大型企业有机会显著提高其软件交付性能和工程效率。
在过去的几年中,许多大型公司,例如Google,Microsoft,Facebook以及类似Jetbrains等较小的公司已经与学术研究人员合作,为基于代码的机器学习奠定了基础。
基于代码的机器学习?代码机器学习(MLonCode)是一个新的跨学科研究领域,涉及自然语言处理,编程语言结构以及社会和历史分析,例如贡献图形和提交时间序列。MLonCode旨在从大规模的源代码数据集中学习,从而能自动执行软件工程任务,例如辅助代码审查,代码重复数据删除,软件专业知识评估等。
为什么MLonCode很难?某些MLonCode问题要求零错误率,例如与代码生成有关的错误率。自动程序修复是一个特定的示例。一个微小的单一错误预测可能会导致整个程序的编译失败。
在其他一些情况下,错误率必须足够低。理想的模型应犯的错误应尽可能少,所以用户(软件开发人员)的信噪比仍是可承受且值得信赖的。因此,可以使用与传统静态代码分析工具相同的方式来使用该模型。最佳实践挖掘就是一个很好的例子。
最后,绝大多数MLonCode问题是无监督的,或至多是弱监督的。手动标记数据集可能会非常昂贵,因此研究人员通常必须开发相关的启发式方法。例如,有许多相似性分组任务,例如向相似的开发人员展示或根据专业领域帮助团队。我们在本主题中的经验在于挖掘代码格式化规则,并将其应用于修复错误,这与短绒一样,但完全不受监督。有一个相关的学术竞赛来预测格式问题,称为CodRep。
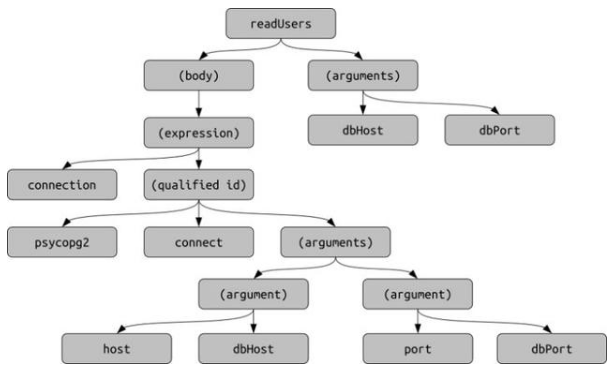
MLonCode问题包括各种数据挖掘任务,这些任务从理论上讲可能是微不足道的,但由于规模或对细节的关注,在技术上仍然具有挑战性。示例包括代码克隆检测和类似的开发人员聚类。此类问题的解决方案在年度学术会议“ 采矿软件存储库”中进行了介绍。
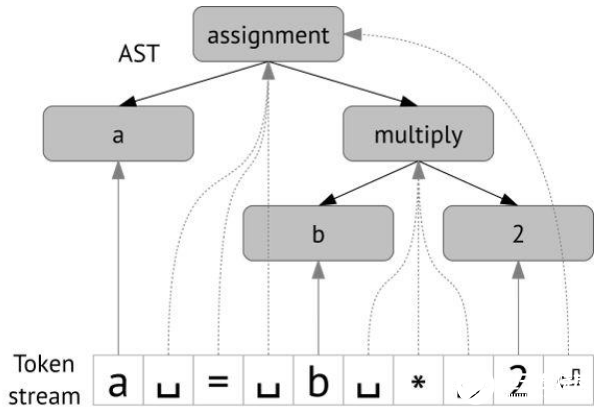
采矿软件存储库会议徽标。解决MLonCode问题时,通常用以下方式之一表示源代码:频率字典(加权词袋,BOW)。示例:函数内的标志符;文件中的graphlet;存储库的依赖性;可以通过TF-IDF加权频率等。这些表示是最简单,可伸缩性最高的。顺序令牌流(TS),对应于源代码解析序列。该流通常通过指向相应抽象语法树节点的链接来增强。此表示形式对常规自然语言处理算法(包括序列到序列深度学习模型)很友好。
一棵树,它自然地来自抽象语法树。在进行不可逆的简化或标志符后,我们执行各种转换。这是最强大的表示形式,也是最难使用的表示形式。以下是相关的ML模型包括各种图嵌入和门控图神经网络。
解决MLonCode问题的许多方法都基于所谓的自然假说(Hindle等):“从理论上讲,编程语言是复杂,灵活且功能强大的,但很多人实际上编写的程序大多是简单且相当重复的,因此它们具有有用的可预测统计属性,可以在统计语言模型中捕获并用于软件工程、任务。”
该声明证明了大代码的有用性:分析的源代码越多,强调的统计属性越强,并且训练有素的机器学习模型所获得的指标越好。底层关系与当前最新的自然语言处理模型相同:如XLNet,ULMFiT等。类似地,通用MLonCode模型可以在下游任务中进行训练和利用。
(责任编辑:fqj)
-
什么是机器学习?它的重要性体现在哪2024-01-05 3103
-
机器学习和深度学习的区别2023-08-17 5884
-
什么是机器学习? 机器学习基础入门2022-06-21 3070
-
机器学习的基础内容汇总2022-02-28 1686
-
机器学习的基础内容介绍2022-01-12 1503
-
机器学习必学的Python代码示例集2021-06-21 1838
-
基于机器学习的恶意代码检测分类2021-06-10 1252
-
结合动态行为和机器学习的恶意代码检测方法2021-03-23 1249
-
机器学习实战的源代码资料合集2021-03-01 1322
-
机器学习的一些代码示例合集2020-04-29 1391
-
使用 Python 开始机器学习2018-12-11 3324
-
机器学习matlab源代码的详细资料免费下载2018-11-23 1620
-
九张机器学习和深度学习代码速查表分享_初学者必备2018-06-30 4957
全部0条评论

快来发表一下你的评论吧 !
