

人工智能之EdgeBoard中CNN架构的剖析
人工智能
描述
(文章来源:粤讯)
人工智能领域边缘侧的应用场景多种多样,在功能、性能、功耗、成本等方面存在差异化的需求,因此一款优秀的人工智能边缘计算平台,应当具备灵活快速适配全场景的能力,能够在安防、医疗、教育、零售等多维度行业应用中实现快速部署。
百度大脑EdgeBoard嵌入式AI解决方案,以其丰富的硬件产品矩阵、自研的多并发高性能通用CNN(Convolution Neural Network)设计架构、灵活多样的软核算力配置,搭配移动端轻量级Paddle Lite高效预测框架,通过百度自定义的MODA (Model Driven Architecture)工具链,依据各应用场景定制化的模型和算法特点,向用户提供高性价比的软硬一体的解决方案,同时和百度大脑模型开发平台(AIStudio、EasyDL)深度打通,实现模型的训练、部署、推理等一站式服务。
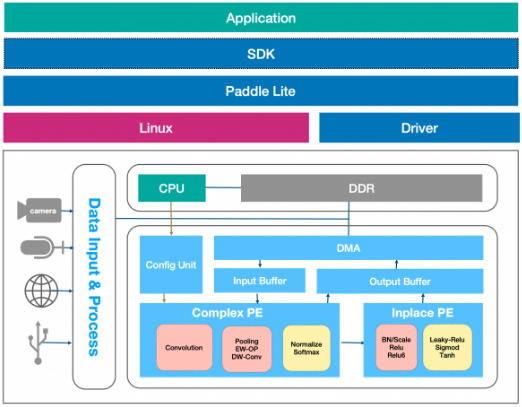
EdgeBoard是基于Xilinx 16nm工艺Zynq UltraScale+ MPSoC的嵌入式AI解决方案,采用Xilinx异构多核平台将四核ARM Cortex-A53处理器和FPGA可编程逻辑集成在一颗芯片上,高性能计算板卡上搭载了丰富的外部接口和设备,具有开发板、边缘计算盒、抓拍机、小型服务器、定制化解决方案等表现形态。
EdgeBoard计算卡产品可以分为FZ9、FZ5、FZ3三个系列,是基于Xilinx XCZU9EG、XAZU5EV、XAZU3EG研发而来,分别具有高性能,视频硬解码,低成本等特点,同时还有不同的DDR容量版本。以上三个版本PS侧同样采用四核Cortex-A53 、双核Cortex-R5、以及GPU Mali-400MP2等处理器配置,PS到PL的接口均为12x32/64/128b AXI Ports,主要的区别在于PL侧拥有的芯片逻辑资源大小不同。
采用上述三种标准产品的硬件板卡或者一致的硬件参考设计,用户可无缝适配运行EdgeBoard公开发布的最新版标准镜像,也可根据自身项目需求定制相关的硬件设计,并进一步根据性能、成本和功耗要求,以及其他功能模块的集成需求,对软核的算力和资源进行个性化配置。
EdgeBoard的CNN加速软核(整体的加速方案称之为软核)提供了一套计算资源和性能优化的AI软件栈,由上至下分别包括应用层软件API、计算加速单元的SDK调度管理、Paddle Lite预测框架基础管理器、Linux操作系统、负责设备管理和内存分配的驱动层和CNN算子的专用硬件加速单元,用来完成卷积神经网络模型的加载、解析、优化和执行等功能。
专用计算加速单元基于FPGA的可编程逻辑资源开发实现,采用ARM CPU和FPGA共享内存的方式,通过高带宽DMA(Direct Memory Access)实现二者数据的高速交互,共享内存也并作为异构计算平台各算子数据在CPU和FPGA协同处理的桥梁,减少了数据在CPU与FPGA之间的重复传输。此外,CNN算子功能模块可直接发起DDR读写操作,充分发挥了FPGA的实时响应特性,减少了CPU中断等待的时间消耗。
作为CNN网络中比重最大、最为核心的卷积计算加速单元,是CNN软核性能加速的关键,也占用了FPGA芯片的大部分算力分配和逻辑资源消耗。下面将针对EdgeBoard卷积计算加速单元的设计思路进行简要介绍,此章节也是理解CNN软核算力弹性配置的技术基础。
每一层网络的卷积运算,有M个输入图片(称之为feature map,对应着一个输入通道),N个输出feature map(N个输出通道),M个输入会分别进行卷积运算然后求和,获得一幅输出map。那么需要的卷积核数量就是M*N。
针对上述计算特点,EdgeBoard的卷积单元采用脉动阵列的数据流动结构,将数据在PE之间通过寄存器进行打拍操作,可以实现在第二个PE计算结果出来的同时完成和前一个PE的求和。这样可以使数据在运算单元的阵列中进行流动,减少访存的次数,并且结构更加规整,布线更加统一,提高系统工作频率,避免了采用加法树等并行结构所造成的高扇出问题。
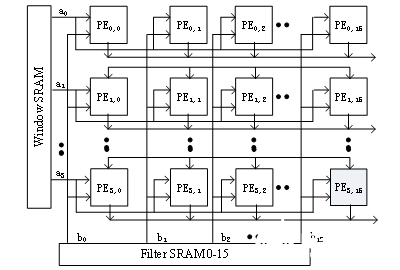
SDK可以将一条滑窗链的Feature Map数据分成B块,并将分块数B和每个块的数据量告诉卷积计算加速单元,那么后者则可以分批依次从DDR读取B次Feature Map数据,每次的数据量是可以存入到Image SRAM内。
SDK可以将Kernel的数量分割成S份,使得分割后的每份Kernel数量可以下发到PL侧的Filter SRAM中,然后SDK分别调度S次卷积算子执行操作,所有的数据返回DDR后,再从通道(Channel)维度做这S次计算结果的数据拼接(Concat)即可。不过要注意的是,我们的Filter SRAM虽然不需存储所有Kernel的数据量,但至少要保证能够存储一个Kernel的数据量。
由此看来,即使EdgeBoard三兄弟中最小的FZ3拥有极其有限的片上存储资源,也是能够很好地完成大多数CNN网络的参数适配。
我们以卷积计算加速单元的核心矩阵乘加运算消耗DSP硬核(Hard core)的个数作为CNN软核核心算力的考察指标。当然,这并不包括卷积前处理、后处理模块,以及其他算子加速单元或者用户自定义功能模块所消耗的DSP数量,因此这并不是整个解决方案在FPGA芯片内部的DSP资源消耗。我们的设计可以支持Window并行度1-8的任意整数,支持Kernel并行度包括4,8,16。
目前,EdgeBoard公开版针对卷积计算加速单元Window维度和Kernel维度的并行度配置,以及核心矩阵乘加运算的DSP硬核消耗。
EdgeBoard的CNN软核以其灵活的算力搭配组合以及算子可定制化的特点,既可以根据具体模型的算子组合和所占比例,将一定成本和资源条件内的芯片性能发挥到极致,还可以在满足场景所要求性能的前提下减少不必要的功耗支出,此外还允许开发者缩减软核尺寸并将芯片资源应用于自定义功能的IP中,极大地增强了EdgeBoard人工智能多场景覆盖的能力。
(责任编辑:fqj)
-
【大家】醍醐灌顶!!人工智能九问九答2015-03-21 4815
-
人工智能是什么?2015-09-16 6455
-
人工智能的前世今生 引爆人工智能大时代2016-03-03 6028
-
百度人工智能大神离职,人工智能的出路在哪?2017-03-23 8098
-
人工智能发展的好与坏2017-06-24 7602
-
人工智能就业前景2018-03-29 8436
-
人工智能的影响超乎你想象2018-06-22 4788
-
解读人工智能的未来2018-11-14 4946
-
人工智能医生未来或上线,人工智能医疗市场规模持续增长2019-02-24 5912
-
人工智能:超越炒作2019-05-29 5049
-
人工智能芯片是人工智能发展的2021-07-27 6723
-
人工智能基本概念机器学习算法2021-09-06 2791
-
物联网人工智能是什么?2021-09-09 5358
-
《移动终端人工智能技术与应用开发》人工智能的发展与AI技术的进步2023-02-17 2391
-
人工智能之卷积神经网络2018-06-18 6058
全部0条评论

快来发表一下你的评论吧 !
