

机器学习中样本比例不平衡应该怎样去应付
人工智能
描述
在机器学习中,常常会遇到样本比例不平衡的问题,如对于一个二分类问题,正负样本的比例是 10:1。
这种现象往往是由于本身数据来源决定的,如信用卡的征信问题中往往就是正样本居多。样本比例不平衡往往会带来不少问题,但是实际获取的数据又往往是不平衡的,因此本文主要讨论面对样本不平衡时的解决方法。
样本不平衡往往会导致模型对样本数较多的分类造成过拟合,即总是将样本分到了样本数较多的分类中;除此之外,一个典型的问题就是 Accuracy Paradox,这个问题指的是模型的对样本预测的准确率很高,但是模型的泛化能力差。
其原因是模型将大多数的样本都归类为样本数较多的那一类,如下所示
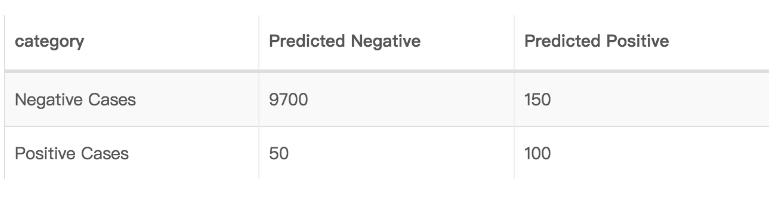
准确率为
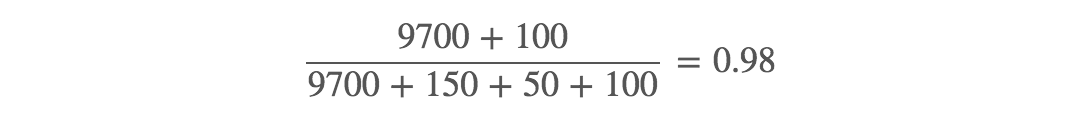
而假如将所有的样本都归为预测为负样本,准确率会进一步上升,但是这样的模型显然是不好的,实际上,模型已经对这个不平衡的样本过拟合了。
针对样本的不平衡问题,有以下几种常见的解决思路
搜集更多的数据
改变评判指标
对数据进行采样
合成样本
改变样本权重
搜集更多的数据
搜集更多的数据,从而让正负样本的比例平衡,这种方法往往是最被忽视的方法,然而实际上,当搜集数据的代价不大时,这种方法是最有效的。
但是需要注意,当搜集数据的场景本来产生数据的比例就是不平衡时,这种方法并不能解决数据比例不平衡问题。
改变评判指标
改变评判指标,也就是不用准确率来评判和选择模型,原因就是我们上面提到的 Accuracy Paradox 问题。实际上有一些评判指标就是专门解决样本不平衡时的评判问题的,如准确率,召回率,F1值,ROC(AUC),Kappa 等。
根据这篇文章,ROC 曲线具有不随样本比例而改变的良好性质,因此能够在样本比例不平衡的情况下较好地反映出分类器的优劣。
关于评判指标更详细的内容可参考文章: Classification Accuracy is Not Enough: More Performance Measures You Can Use
对数据进行采样
对数据采样可以有针对性地改变数据中样本的比例,采样一般有两种方式:over-sampling和 under-sampling,前者是增加样本数较少的样本,其方式是直接复制原来的样本,而后者是减少样本数较多的样本,其方式是丢弃这些多余的样本。
通常来说,当总样本数目较多的时候考虑 under-sampling,而样本数数目较少的时候考虑 over-sampling。
关于数据采样更详细的内容可参考 Oversampling and undersampling in data analysis
合成样本
合成样本(Synthetic Samples)是为了增加样本数目较少的那一类的样本,合成指的是通过组合已有的样本的各个 feature 从而产生新的样本。
一种最简单的方法就是从各个 feature 中随机选出一个已有值,然后拼接成一个新的样本,这种方法增加了样本数目较少的类别的样本数,作用与上面提到的 over-sampling方法一样,不同点在于上面的方法是单纯的复制样本,而这里则是拼接得到新的样本。
这类方法中的具有代表性的方法是 SMOTE(Synthetic Minority Over-sampling Technique),这个方法通过在相似样本中进行 feature 的随机选择并拼接出新的样本。
关于 SMOTE 更详细的信息可参考论文 SMOTE: Synthetic Minority Over-sampling Technique
改变样本权重
改变样本权重指的是增大样本数较少类别的样本的权重,当这样的样本被误分时,其损失值要乘上相应的权重,从而让分类器更加关注这一类数目较少的样本。
责任编辑:Ct
-
如何理解矢量测量中“平衡”与“不平衡2020-03-29 3845
-
三相不平衡的原因、危害以及解决措施2017-04-22 8567
-
如何更好区分矢量测量中“平衡”与“不平衡”?2019-02-13 3398
-
4294A电桥不平衡2022-06-17 2415
-
基于主动学习不平衡多分类AdaBoost改进算法2017-11-30 1053
-
不平衡类别的机器学习2018-06-27 517
-
手把手教你解决-深度学习训练数据不平衡问题2018-07-24 9165
-
三相电压不平衡产生原因_三相电压不平衡的治理措施2019-10-28 27628
-
基于有效样本的类别不平衡损失2021-08-16 2636
-
电机转子不平衡对电机质量的影响大吗2023-08-30 1891
-
三相不平衡是什么意思?三相电压不平衡怎么处理?2023-09-25 7479
-
I/Q不平衡的来源 IQ信道之间的不平衡会造成什么影响呢?2023-10-31 2412
-
三相电压不平衡对电路的影响2023-12-11 6061
-
三相不平衡最佳解决办法 三相不平衡多少范围内是合理的2024-02-06 7261
-
平衡电阻器可以改为不平衡吗2025-01-30 2404
全部0条评论

快来发表一下你的评论吧 !
