

一个学习何时做分类决策的强化学习模型:Jumper
电子说
描述
文本理解是自然语言处理领域的一个核心目标,最近取得了一系列的进展,包括机器翻译、问答等。不过之前的工作大多数是关心最终的效果,而人们对于模型何时做出决定(或做决定的原因)却知之甚少,这是一个对于理论研究和实际应用都非常重要的课题。深度好奇(DeeplyCurious.AI) 最近在IJCAI-2018上展示了一个学习何时做分类决策的强化学习模型:Jumper, 该论文将文本分类问题建模成离散的决策过程,并通过强化学习来优化,符号化表征模型的决策过程具有很好的可解释性,同时分类效果也达到最高水平。
本文提供了一种新的框架,将文本理解建模为一个离散的决策过程。通常在阅读过程中,人们寻找线索、进行推理,并从文本中获取信息;受到人类认知过程的启发,我们通过将句子逐个地递送到神经网络来模仿这个过程。在每个句子中,网络基于输入做出决策(也称为动作),并且在该过程结束时,该决策序列可以视为是对文本有了一些“理解”。
特别一提的是,我们专注于几个预定义子任务的文本分类问题。当我们的神经网络读取一个段落时,每个子任务在开始时具有默认值“无”(None)。 在每个决策步骤中,段落的句子按顺序被递送到神经网络;之后,网络来决定是否有足够的信心“跳转”到非默认值作为特定时间的预测。我们施加约束,即每次跳转都是最终决定,它不可以在后面的阅读中被更改。如图1所示,给定一段话,有多个预先定义好的问题等待回答;模型按句子阅读,在阅读过程中,问题的答案陆续被找到。模型从默认决策到非默认决策都是一个“跳转”的过程,正因此我们称模型为Jumper。在人类阅读的过程中,人们通常会获得一致的阅读理解的结果,但是阅读理解过程中的很多环节却经常是微妙和难以捉摸的。同样,我们也假设我们的训练标签仅包含最终结果,并且没有给出关于模型应该做出决定的步骤的监督信号。也就是说,我们通过强化学习在弱监督信号情况下训练Jumper模型。
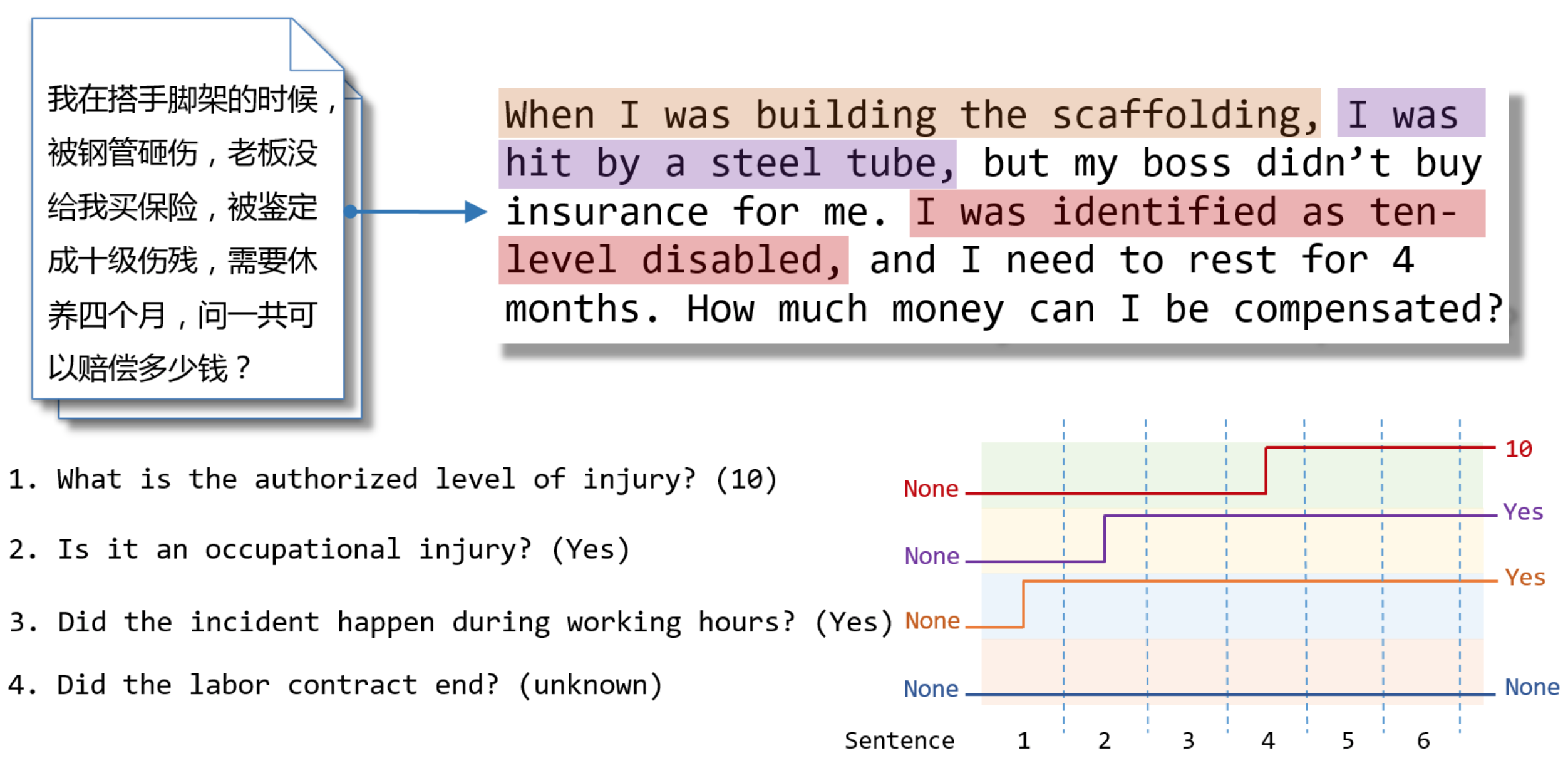
图1 Jumper模型在阅读段落的决策过程
Jumper模型主要由编码层、控制器、符号输出层构成。编码层将句子编码成定长的向量,控制器根据历史和当前输入产生当前的决定,符号输出层使模型的输出满足跳转约束,即每个决策过程最多只能有一次跳转。

图2 Jumper模型的基本框架
跳转约束的作用在于使模型更加慎重地决定何时跳转。因此,Jumper模型的优化目标有两个,第一个是尽可能早地“跳转”,第二个是尽可能预测准。假设t* 是最佳的跳转时间,那么如果模型在t* 时刻之前跳转,则模型还没有看到真正的pattern,那么得到的答案等同于随机猜;如果模型在t* 时刻之后跳转,而t* +1句话可能不存在,因此没有机会跳转从而预测错误。
通过上述建模,论文把文本分类问题转化为离散的决策过程,训练好的Jumper输出的离散决策过程就可以表达模型对文本的理解过程;而决策过程本身并没有标签,因此我们用policy gradient强化学习算法来训练,如果最终的决定和分类标签一致,就奖励整个决策动作,如果不一致,则惩罚。
我们对三个任务评估了Jumper,包括两个基准数据集和一个实际工业应用。我们首先分析了Jumper的分类准确性,并与几个基线进行了比较。表1显示Jumper在所有这些任务上实现了相当或更好的性能,这表明将文本分类建模为顺序决策过程不仅不会损害、甚至提高了分类准确性。

表1 在电影评论数据集(MR)、新闻数据集(AG)和工伤数据集(OI)的测试集上的准确率
我们想指出,“准确性”并不是我们关注的唯一表现。更重要的是,提出的模型能够减少阅读过程,或者找到文本分类的关键支撑句。只要在阅读过程中基于“跳转约束”限制而看到足够的证据,Jumper就能做出决定,并且在预测之后不需要再阅读之后的句子。在表2中可以看到,我们的模型与强基线相比达到了相似或更高的性能,与此同时,它还将文本读取的长度缩减了30-40%,从而加速了推断预测。

表2
除了准确率高和推断速度快以外,我们更好奇Jumper是否能够在信息提取式任务(例如工伤级别分类任务)中找到正确的位置做出决策。我们在400个数据点中标注关键支撑句(即最佳跳转位置)作为测试基础。需要注意的是,在这个实验中我们仍然没有跳转位置的训练标签。我们将Jumper与使用相同神经网络的层级CNN-GRU模型进行比较,但在训练方法方面有所不同;层级CNN-GRU在训练时,用段落末尾的交叉熵作为损失函数。在测试期间,我们将预测器应用于每个步骤并找到它做出预测的第一个位置。我们还列出了一个经典CNN的结果作为基线模型,并使用了最大池化操作(max-pooling)选择的单词最多的那些句子来作为测试数据。我们使用了跳转动作的准确率来评测Jumper。通过表3可知,Jumper准确地找到了测试集中所有关键支撑句的位置,说明我们的单跳约束迫使模型更仔细地思考何时做出决策,也验证了强化学习是学习决策正确位置的有效方法。

表3 各模型在工伤等级分类任务(OI-Level)上寻找关键支撑句的效果统计。该任务的关键支撑句在文本中通常聚集于一处,不存在歧义,便于衡量各模型效果。CA:分类准确率,JA:跳跃准确率,OA:在分类准确条件下的跳跃准确率
图3则显示了Jumper在阅读时做出决策的过程。其中,Jumper在前六个句子中保持默认决策(不做跳转),而在到达关键支撑句时突然跳转,这体现了Jumper可以识别关键支撑句,从而找到最佳跳跃位置。因此,在这类关键支撑语句集中出现时,Jumper可以在完成分类任务的同时找到关键支撑句,因此具有较强的可解释性。
图3 Jumper决策序列展示
总结
我们提出了一种新的模型Jumper,它在阅读段落时将文本分类建模为逐个句子的顺序决策过程。我们通过强化学习训练带有跳转约束的Jumper,实验表明:1) Jumper的性能与基线相当或更高;2) 它在很大程度上减少了文本阅读量;3) 如果所需信息在文中的分布是局域性的,它可以找到关键的支撑句子,具有很好的可解释性。
-
深度强化学习实战2021-01-10 2952
-
将深度学习和强化学习相结合的深度强化学习DRL2018-06-29 28850
-
强化学习的风储合作决策2018-01-27 976
-
人工智能机器学习之强化学习2018-05-30 1862
-
深度强化学习你知道是什么吗2019-12-10 1808
-
一文详谈机器学习的强化学习2020-11-06 2313
-
机器学习中的无模型强化学习算法及研究综述2021-04-08 1417
-
模型化深度强化学习应用研究综述2021-04-12 1331
-
基于深度强化学习仿真集成的压边力控制模型2021-05-27 1111
-
强化学习与智能驾驶决策规划2023-02-08 3255
-
彻底改变算法交易:强化学习的力量2023-06-09 1102
-
什么是强化学习2023-10-30 5910
-
如何使用 PyTorch 进行强化学习2024-11-05 1928
-
自动驾驶中常提的“强化学习”是个啥?2025-10-23 1089
-
强化学习会让自动驾驶模型学习更快吗?2026-01-31 986
全部0条评论

快来发表一下你的评论吧 !
