

AI/ML将FPGA和ASIC结合在了一起
可编程逻辑
描述
(文章来源:EEworld)
随着人工智能、机器学习等应用场景快速发展演进,对芯片的算力、安全性等性能也提出了更高的诉求。据市场调研公司Semico Research数据显示,2018年FPGA市值约为10亿美元,在未来4年内,人工智能应用中FPGA的市场规模将增长3倍,达到52亿美元。要知道,这个增长是非常惊人的,毕竟过去多年,FPGA市场的年均增长率也才8%-9%。目前人工智能、机器学习等应用场景的FPGA市场约为25%,预计两年后将达到72%。如此庞大的市场空间,则需要性能更高、更加灵活的AI 算法解决方案。
关于块浮点数(BFP)已经出现一段时间了,但是现在才开始被看作是执行机器学习操作的一种非常有用的技术。值得指出的是,这与bfloat不是一回事。BFP结合了定点运算的效率,并提供了全浮点运算的动态范围。在研究BFP中使用的方法时,我想起了几个用于简化数学问题的“技巧”。首先想到的是所谓的日本乘法,它使用简单的图形方法来确定产品。另一个,当然,是曾经流行但现在几乎被遗忘的计算尺。
在即将到来的网络研讨会上,Achronix的战略和规划高级总监Mike Fitton解释了关于在人工智能/ML工作负载的FPGA中使用BFP的相关问题,BFP依赖于标准化的不动点随机数,因此计算中使用的“块”数字都具有相同的指数值。在乘法的情况下,只需要对尾数进行定点乘法,对指数进行简单的加法。令人惊讶的是,与传统的浮点运算相比,BFP提供了更快的速度和更低的功耗。当然,整数运算更精确,使用的功耗也更低,但是它们缺乏BFP的动态范围。根据Mike BFP的说法,他为人工智能/ML工作负载提供了一个最佳位置,而网络研讨会将为他的结论提供支持数据。
AI/ML训练和推理的需求与dsp中信号处理通常需要的需求大不相同。它适用于内存访问,也适用于数学单元实现。Mike详细讨论了这一点,并展示他们构建到Speedster7t中的新机器学习处理器(MLP)单元如何对BFP提供本机支持,还支持广泛的完全可配置的整数和浮点精度。实际上,它们的MLP非常适合传统的工作负载,并且在AI/ML方面也很出色,没有任何区域损失。每个MAC块最多有32个倍增器。
Achronix MLP具有紧密耦合的内存,方便了AI/ML工作负载。每个MLP有一个本地72K位块RAM和一个2K位寄存器文件。MLP的数学块可以配置为级联内存和操作数,而无需使用FPGA路由资源。
Achronix公司推出了创新性的、全新的FPGA系列产品——Speedster 7t系列。Achronix称,Speedster 7t系列是基于一种高度优化的全新架构,以其所具有的如同ASIC一样的性能、可简化设计的FPGA灵活性和增强功能,从而远远超越传统的FPGA解决方案。
Speedster7t也非常有趣,因为芯片上的高数据速率网络(NoC)可以用来移动数据之间的MLP和/或其他块或芯片上的数据接口。NoC可以在不消耗宝贵的FPGA资源的情况下移动数据,并且避免了FPGA结构内部的瓶颈。NoC有多个管道,256位宽,2GHz运行,数据速率为512G。它们可以直接将数据从外围设备(如400G以太网)移动到GDDR6内存中,而不需要使用任何FPGA资源。
Achronix将提出一个令人信服的理由,说明为什么在他们的架构中本地实现BFP(包括许多开创性的特性)对于AI/ML和其他更传统的FPGA应用程序(如数据聚合、IO桥接、压缩、加密、网络加速等)来说是非常有吸引力的选择。
对于AI加速来说,相较于我们常见的CPU、GPU等通用型芯片以及可编程的FPGA来说,ASIC芯片的计算能力和计算效率都直接根据特定的算法的需要进行定制的,它可以实现体积小、功耗低、高可靠性、保密性强、计算性能高、计算效率高等优势。所以,在其所针对的特定的应用领域,ASIC芯片的能效表现要远超CPU、GPU等通用型芯片以及可编程的FPGA。
但是,目前AI算法仍然处在一个不断的快速更新迭代的阶段,数值精度的可选择性也越来越多。同时随着AI的应用场景快速发展演进,新的解决方案都要去应对在高性能、灵活和上市时间等方面的不同需求。而AISC是针对特定的算法加速所设计的,这也使得其在灵活性上远不如可通过编程快速适应新的软件算法的FPGA。但是,FPGA在体积、能效、成本上却又不如AISC。那么是否能够有这样一款产品,能够很好的将FPGA和ASIC的优点结合在一起呢?Achronix的Speedster 7t系列或许就是这样一款产品。
Speedster7t FPGA系列产品是专为高带宽应用进行设计,具有一个革命性的全新二维片上网络(2D NoC),以及一个高密度全新机器学习处理器(MLP)模块阵列。Achronix CEO Robert Blake认为Speedster7t是Achronix历史上最令人激动的发布,代表了建立在四个架构代系的硬件和软件开发基础上的创新和积淀,以及与我们领先客户之间的密切合作。
Speedster7t是灵活的FPGA技术与ASIC核心效率的融合,从而提供了一个全新的‘FPGA+’芯片品类,它们可以将高性能技术的极限大大提升。
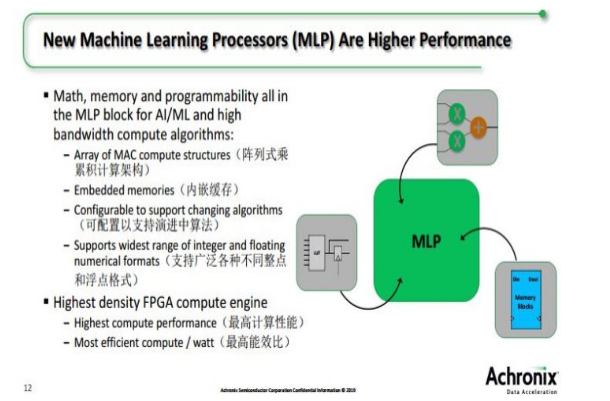
AI、ML需要矢量矩阵乘法,而传统的带DSP模块的FPGA性能有限,需要消耗额外逻辑和Memory资源,而新的MLP是高度可配置的、计算密集型的单元模块,可支持4到24位的整点格式和高效的浮点模式,包括对TensorFlow的16位格式的支持,以及可使每个MLP的计算引擎加倍的增压块浮点格式的直接支持。它可提供业界最高的、基于FPGA的计算密度。
值得一提的是,Speedster7t器件是唯一支持GDDR6存储器的FPGA,该类存储器是具有最高带宽的外部存储器件。每个GDDR6存储控制器都能够支持512 Gbps的带宽,Speedster7t器件中有多达8个GDDR6控制器,可以支持4 Tbps的GDDR6累加带宽,并且以很小的成本就可提供与基于HBM的FPGA等效存储带宽。

除了这种超高的存储带宽,Speedster7t器件还包括业界最高性能的接口端口,以支持极高带宽的数据流。Speedster7t器件拥有多达72个业界最高性能的SerDes,可以达到1到112 Gbps的速度。还有带有前向纠错(FEC)的硬件400G以太网MAC,支持4x 100G和8x 50G的配置,以及每个控制器有8个或16个通道的硬件PCI Express Gen5控制器。
Speedster7t高速I/O和存储器端口的产生的数万兆比特数据很容易淹没传统FPGA面向比特位的可编程互连逻辑阵列的路由容量,而Speedster7t架构包含一个可横跨和垂直跨越FPGA逻辑阵列的创新性的、高带宽的二维片上网络(NOC),它们连接到所有FPGA的高速数据和存储器接口。
它们就像叠加在FPGA互连这个城市街道系统上的空中高速公路网络一样,Speedster7t的NoC支持片上处理引擎之间所需的高带宽通信。NoC中的每一行或每一列都可作为两个256位实现,单向的、行业标准的AXI通道,工作频率为2Ghz,同时可为每个方向提供512 Gbps的数据流量。

通过在Speedster中实现专用二维NoC,极大地简化了高速数据移动,并确保数据流可以轻松地定向到整个FPGA结构中的任何自定义处理引擎。最重要的是,NOC消除了传统FPGA使用可编程路由和逻辑查找表资源在整个FPGA中移动数据流中出现的拥塞和性能瓶颈。这种高性能网络不仅可以提高Speedster7t FPGA的总带宽容量,还可以在降低功耗的同时提高有效LUT容量。
Speedster7t FPGA系列产品在面临第三方攻击的威胁时,可用最先进的比特流安全保护功能应对,它们具有的多层防御能力可保护比特流的保密性和完整性。密钥是基于防篡改物理不可克隆技术(PUF)进行加密,比特流由256位的AES-GCM加密算法进行加密和验证。为了防止来自旁侧信道的攻击,比特流被分段,每个数据段使用单独导出的密钥,且解密硬件采用差分功率分析(DPA)计数器措施。
此外,2048位RSA公钥认证协议被用来激活解密和认证硬件。用户可以确信的是当他们加载其安全比特流时,它是预期的配置,这是因为它已通过RSA公钥、AES-GCM私钥和CRC校验进行了身份验证。
据悉,Achronix是目前唯一一家既提供独立FPGA芯片又提供Speedcore嵌入式FPGA(eFPGA)半导体知识产权( IP)的公司。也就是说,芯片设计厂商可以通过购买授权的形式,将Achronix的Speedcore嵌入式FPGA(eFPGA)的IP整合到自己的芯片设计当中,设计出符合自身需求的芯片。
而Achronix在Speedcore eFPGA IP中采用了与Speedster7t FPGA中使用的同一种技术,可支持从Speedster7t FPGA到ASIC的无缝转换。这也意味着芯片设计厂商通过与Achronix合作,也可以获得最新的Speedster7t FPGA系列的技术,并可将其转换为ASIC。Achronix CEORobert Blake表示,该技术有望帮助客户节省高达50%的功耗并降低90%的成本。
(责任编辑:fqj)
-
怎么把主界面和子VI结合在一起2014-08-24 5018
-
请问ISE和Mircoblaze是如何结合在一起的?2019-02-19 1192
-
labview中模糊控制和pid是怎么结合在一起的2020-03-13 2347
-
labview 中如何把模糊控制和pid结合在一起呢?2020-03-14 1649
-
【高分讨论】如何将labview中的模糊控制器和pid结合一起?2020-03-19 2344
-
USAT和USB BooLoad能结合在一起吗2020-04-24 1831
-
如何将高图形性能和低功耗更好地结合在一起?2021-06-01 1200
-
Teamcenter、TIA Portal、NX MCD是如何结合在一起2021-07-02 1276
-
Teamcenter、TIA Portal和虚拟调试如何才能结合在一起2021-09-29 2922
-
如何将DMA和环形的FIFO队列结合在一起来使用呢2021-12-09 3367
-
微软的合作伙伴Trimble正在尝试将HoloLens与安全帽结合在一起2018-02-02 6947
-
将深度学习和常微分方程结合在一起,提供四大优势2018-06-26 12523
-
Master of Shapes将虚拟现实赛道与现实世界的赛车融合在了一起2018-11-07 1288
-
基于一款将PC和PS4或Xbox结合在一起的强大主机介绍2020-01-08 3660
-
将5G信号链与电平转换结合在一起2024-09-18 392
全部0条评论

快来发表一下你的评论吧 !
