

如何更加高效的提升存储系统性能?
描述
随着智慧化转型的不断加速
数据被越来越多的应用于营销、决策和分析
快速响应能力已经成为企业的决胜因素
数据存储性能是业务加速的关键核心
如何更加高效的提升存储系统性能?
浪潮存储在新一代G5存储平台上,打造【iTurbo智能引擎】硬核技术,构建起一套如汽车自动变速引擎的黑科技,让存储系统可以根据前端应用自适应和调配不同数据处理策略,实现智能的IO感知、路径选择、组织和调度,为存储带来创新的加速方案。
今天就让我们一起探秘
【iTurbo智能引擎】的核心技术之一
智能IO感知技术
智能缓存预读
实现“热”升“冷”降的数据电梯
介绍缓存预读之前,我们首先要搞清楚关于缓存的两个基本问题:
一:为什么要用缓存?
二:缓存是如何工作的?
为什么要用缓存?
大家知道,CPU 的运行速度比磁盘的速度快很多倍,这样会导致 CPU 需等待磁盘完成处理后才能继续下一道指令, 缓存的处理速度能够跟得上 CPU,它作为CPU与磁盘之间的过渡,很好的解决了这一问题。当CPU处理完数据后,将数据直接发送给缓存,然后立即向应用返回确认,缓存中数据达到一定水位定期写入磁盘,从而提升效率。
缓存是如何工作的?
在程序运行过程中,缓存会有一个局部性原理,即程序会频繁访问局部缓存。如果缓存地址变换频繁,那么缓存中存放的数据就会频繁改变;如果程序频繁访问局部数据,那么缓存中的数据改变就不会很大。因而命中率就会提高,CPU的运行效率也会提升。
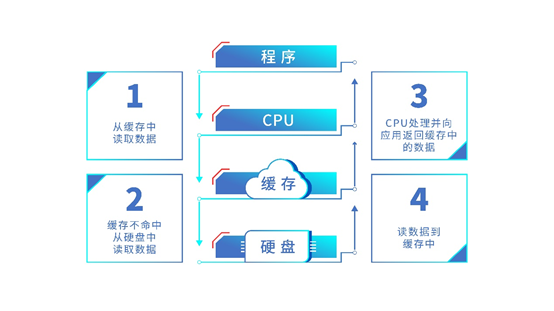
浪潮存储的缓存工作原理
由此可知,衡量缓存管理的优劣有两个指标:
一:缓存命中率,命中率高,性能就高,否则反之。
二:有效缓存的比率,有效缓存是指真正会被访问到的缓存项,如果有效缓存的比率偏低,则相当部分磁盘带宽会被浪费到读取无用缓存上,而且无用缓存会间接导致系统缓存紧张,最后可能会严重影响性能。 现在我们清楚了缓存的工作原理及性能指标。
那么为了充分发挥缓存的作用,仅仅依靠“暂存刚刚访问过的数据”是远远不够的,还要通过使用数据预读算法——尽可能把将要使用的数据预先从内存中取到缓存里。
那么关键问题来了:如何精准判断哪些数据是应用程序将要使用的数据?当缓存写满时,如何判断哪些数据被淘汰?
这就是浪潮存储缓存预读算法的精髓所在,我们来深入剖析浪潮存储缓存预读的工作原理。
一方面,浪潮存储基于缓存预读 可精准判断数据热度浪潮存储的缓存预读算法,可以根据历史数据的I/O模式,通过智能分析、预判将要访问的数据,提前将这些数据预读到缓存中,提升缓存命中率,降低I/O访问时延。这里主要有两个关键技术要点:
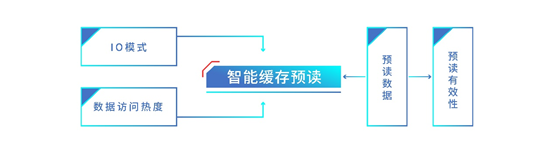
浪潮存储的智能缓存预读算法
一:自适应缓存预读策略读I/O分为随机读和顺序读两大类,为了保证预读命中率,针对不同的I/O模式采用不同的预读算法。对于顺序读根据区域地址进行顺序预读,对于随机读根据区域热度进行预读。根据不同的读I/O模式两种预读策略动态调整,不仅可以保证很高的预读命中率,同时有效率/覆盖率也很好。
因为顺序读是最简单而普遍的,而随机读在内核来说也确实是难以预测的。内核通过验证如下两个条件来判定是否顺序读:该区域内容被第一次读,并且读的是首部;当前的读请求与前一个读请求在区域内的位置是连续的;如果不满足上述顺序性条件,就判定为随机读。预读策略根据读I/O模式不同动态调整。
二:预读粒度动态调整当确定了要进行顺序预读时,就需要决定合适的预读粒度。预读粒度太小的话,达不到应有的性能提升效果;预读太多,又有可能载入太多程序不需要的内容,造成资源浪费。为此,浪潮存储可根据实际的需求动态调整预读数据内容的粒度,从而提高缓存的有效率。如果缓存命中率提高,后续的预读粒度将逐次倍增,直到系统的最佳预读大小;随着缓存命中率降低,后续预读粒度将逐渐减小,直到系统的最佳预读大小。
另一方面,浪潮存储基于缓存替换算法 实现低访问数据下移
当缓存满了怎么办?不得覆盖掉一个,覆盖掉哪一个?这就是替换算法要解决的。
浪潮存储的缓存替换算法是基于预读数据的命中率,结合数据的访问热度,淘汰最近最少用的那一块,从而提升预读数据的有效性,保证预读持续、高效的正向性能提升。 我们的设计思路是,如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小。也就是说,当限定的空间已存满数据时,应当把最久没有被访问到的数据淘汰。具体实现算法如下:
硬件缓存每一行都有一个计数器,用来记录被使用次数。
计数器变化规则: 每组4行时,计数器有两位,计数值越小则说明越被常用命中时被访问行的计数置0,比其低的计数器加1,其余不变未命中且该组未满时,新行计数器置为0,其余全加1未命中且该组已满时,计数值为3的那一行中的主存块被淘汰,新行计数器置为0,其余全加1
说到这里,估计大家还是没有看懂为了更加直观的展示算法原理,我们举个例子:
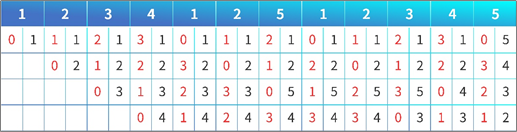
智能缓存替换算法原理
现在有四个格子,但是有 5 个不一样的块要进来,缓存替换过程如下:1 来,没有命中,1 进入缓存,计数器为 02 来,没有命中,2 进入缓存,2 计数器 0,1计数器为 1(对应第三条)3 来同上4 来同上1 又来,命中,1 的计数器变为 0,其余加 12 又来,命中,2 的计数器变为 0,其余加 15 来了,但是现在 Cache 满了,去掉哪一个呢?计数器最大的那个!…
特征数据识别
基于“逐字节”比对实现去重
根据用户的数据特征建立数据特征表单,当新的数据请求与表单中的特征匹配时,说明该部分数据已经落盘,这部分数据可以避免重复写入。
特征匹配采用近似匹配的策略,存在两份不同数据的特征一致的情况,为了确保用户的数据安全,每份不同的数据都能一字不落的存放起来,浪潮存储还对特征匹配的数据需要进行“逐字节”比较,为了降低逐字节比较时的访盘时延,系统会智能感知特征数据的访问热度,将频繁访问的热点特征数据提取到内存中,保证系统时延最低。
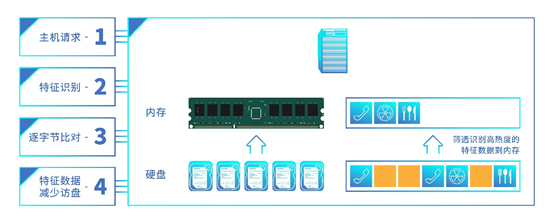
浪潮存储的特征数据识别算法
黑科技总结时间
浪潮存储【iTurbo智能引擎】的核心技术之一智能IO感知技术,通过自适应缓存预读算法对历史数据I/O模式进行分析、判断识别,对其提前读取到缓存,从而达到缓存最高命中率。当缓存写满时,通过独特的替换算法将使用最少数据的淘汰,将缓存发挥出其最大的价值,从而提升存储整体I/O性能;通过特征数据识别和逐字节的比较,在确保数据安全的前提下减少数据落盘,从而提高存储的性能及空间使用率。
-
影响存储系统性能的因素2024-11-18 1438
-
兆芯携手智云创新推出高性能NVMe企业级存储系统2024-04-12 1330
-
存储系统的层次结构2021-07-29 2086
-
感知系统性能评估分析解决方案 精选资料分享2021-07-27 1827
-
Ceph分布式存储系统性能优化研究综述2021-04-13 1068
-
中科曙光基于区块链存储应用的智能高效的专属存储系统—区块链存储系统ChainStor2020-12-31 14634
-
为什么存储系统的性能涉及到无数的IO环节?2020-08-29 3066
-
一种面向高性能计算的分布式对象存储系统2018-01-29 990
-
公有云存储系统性能评测方法研究2017-12-03 1023
-
一种SSD友好的键值对存储系统2017-11-28 984
-
最新可用隔离元件的性能提升如何帮助替代架构在不影响安全性的前提下提升系统性能2017-10-13 8443
-
多核处理器片上存储系统研究2011-07-27 749
-
网络存储系统可生存性量化评估2010-04-24 2232
-
基于ARM的实验数据海量存储系统的设计2010-01-06 645
全部0条评论

快来发表一下你的评论吧 !
