

 对标英伟达胜算几何?这家AI芯片独角兽首次全面揭开神秘面纱……
对标英伟达胜算几何?这家AI芯片独角兽首次全面揭开神秘面纱……
电子说
1.4w人已加入
描述
在AI训练市场,不乏跃跃欲试想挑战英伟达霸主地位的厂商。不过,英伟达GPU仍是当前全球大规模商用部署的头号玩家。其次,Google的TPU通过内部应用及TensorFlow占据第二大生态规模。
要知道,一颗AI芯片从开发定义到落地部署,中间存在着巨大的鸿沟,特别是算法越来越复杂、模型越来越大,AI芯片面临着算力的严峻考验,最终要在数据中心批量部署,能够成功的厂商凤毛麟角。
不过,来自于底层的颠覆性创新正在悄然改变着格局。Graphcore,这家成立于2016年、来自于英国的AI芯片公司,通过创新的IPU处理器技术,已经开始在全球数据中心批量应用,跻身于该市场第三梯队。
5月27日,在Intelligent Health峰会上,微软机器学习科学家Sujeeth Bharadwaj分享了在攻克新冠病毒时的一项研究,在训练CXR(胸部X射线检查)模型时,用Graphcore IPU处理器和英伟达 V100同时运行微软COVID-19影像分析算法SONIC,最终的结果可能令所有人大跌眼镜:IPU在30分钟内完成了V100需5个小时的训练工作量!
这家年轻的公司,由此再次引起了业界的关注。日前,Graphcore面对<电子发烧友>等行业媒体,首次在中国市场全面揭开了其创新背后的核心技术及最新业务进展,以及在中国市场的布局等。
为什么传统的处理器架构需要被颠覆?
Graphcore高级副总裁兼中国区总经理卢涛(Jason Lu)介绍称,AI时代的机器智能代表的是全新的计算负载,不同于传统计算的特点有:它是非常大规模的并行计算;数据结构非常稀疏;相较于传统的科学计算或高性能计算(HPC),AI/机器智能是低精度计算;另外在训练、推理过程中的数据参数复用、静态图结构等,都是AI应用全新计算负载的典型代表。
卢涛 Jason Lu
Graphcore高级副总裁兼中国区总经理
Graphcore高级副总裁兼中国区总经理
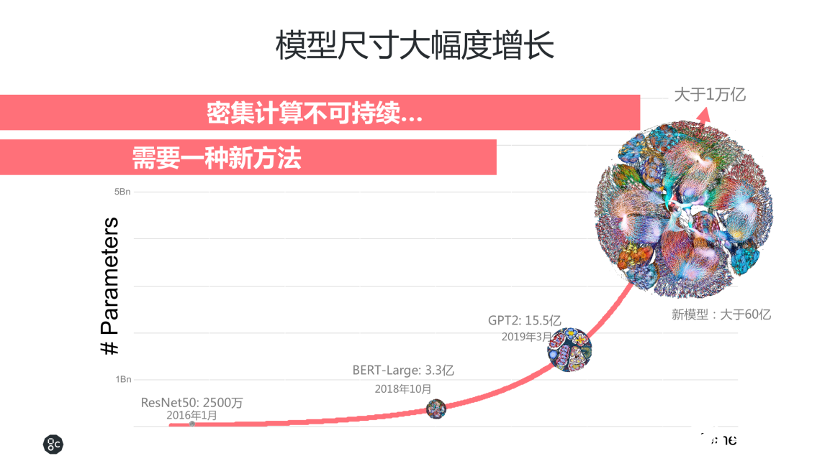
整个AI算法模型的演变,基本上从2016年1月份的ResNet50的2500万个参数,发展到2018年10月份BERT-Large的3.3亿个参数,而到了2019年发展到GPT2的15.5亿个参数,增长幅度非常大。甚至,现在一些领先的科研机构和AI研究者在探索更大的算法模型,能够训练更复杂的算法,来提高精度。密集计算并不是可持续的方法,譬如算法模型参数要从15.5亿规模扩展到一万亿,这种指数级的增长,需要成倍的算力提升。Graphcore认为,传统处理器无法很好地应对这些变化,因此市场需要一种颠覆式的创新架构。
传统的处理器架构,如CPU是针对应用和网络进行设计的标量处理器,GPU是以向量处理为核心的、针对图形和高性能计算的处理器。而AI是全新的应用架构,底层是以计算图作为表征的,且从整个AI发展方向来看,大规模、稀疏化的数据会越来越多,因此,Graphcore针对这些发展趋势设计了一种全新的处理器架构。
全世界最复杂的拥有236亿个晶体管的芯片处理器
目前为止,机器学习的算力来源主要还是传统的处理器,它们的算力提升也非常快。不过,峰值算力和有效算力是两回事,这其中,内存带宽成为掣肘。当处理器算力提高了10倍,内存如何相应提高10倍的性能呢?卢涛介绍,如果用传统的DDR4、DDR5、HBM、HBM1、HBM2、HBM3等内存,基本上每一代能有30%或40%的提升,因此,这对传统架构是一个非常大的挑战。
相较于传统CPU、GPU,IPU采用了大规模并行MIMD(多指令多数据)处理器核,通过紧密耦合的大型本地分布式SRAM,在片内能够做到300MB SRAM。相对CPU的DDR2子系统或GPU的GDDR、HBM来说,IPU能够实现10到320倍的性能提升。这样带来的好处是,能够将模型和数据放在片内处理,从时延的角度来看,与访问外存相比较,时延仅为1%。
通过采用大规模分布式的片上SRAM架构,IPU处理器将所有memory都放在片上,解决了当前机器学习中大量出现的内存带宽所造成的瓶颈。
目前,基于这一创新架构的IPU处理器GC2已量产,采用TSMC 16nm工艺,号称是世界上最复杂的拥有236亿个晶体管的芯片处理器。
GC2片内有1216个IPU-Tiles,每个Tile有独立的IPU核心作为计算以及In-Processor-Memory(处理器之内的内存),总共有7296个线程,能够支持7296个程序并行运行。对整片来说,In-Processor-Memory总共是300MB,PCIe是16个PCIe Gen 4。
而在各个核心之间,Graphcore通过BSP同步协议,能够支持同一个IPU处理器内1216个核心之间的通信,以及跨不同的IPU之间进行通信。另外,在IPU和IPU之间,拥有80个IPU-Links,总共有320GB/s的chip to chip的带宽。正因如此,IPU处理器可以同时支持训练和推理。
从目前所公布的指标来看,在自然语言处理、图像分类、金融模型训练等方面,IPU在现有及下一代的模型上,性能均领先于GPU:在自然语言处理方面的速度能够提升20%到50%;在图像分类方面,能够有6倍的吞吐量且时延更低;在金融模型方面,训练速度能够提高26倍以上。目前,IPU在云上、在一些客户的自建数据中心的服务器上已经投产应用。
而在场景应用方面,IPU采用分组卷积的方式也体现出了独有优势,特别是针对更为稀疏化的数据时。
卢涛分享了众多AI创新者、算法科学家、AI应用开发者日常工作中遇到的一大问题:当算法模型在GPU上运行速度非常慢的时候,通常被认为是算法或软件问题。他指出,如果算法模型不是用稠密的卷积,而是用较为稀疏的卷积比如Fully depthwise做的,那么在GPU上运行得慢的根本原因是GPU架构不符合算法特点,因此采用IPU能够提供更好的支持。
他解释称,Graphcore设计了一个分组卷积内核的micro-benchmark,将组维度(group dimension)分成从1到512来比较,这里512就是应用得较多的“Dense卷积网络”,典型应用如ResNet。此时,IPU GC2性能甚至比英伟达V100要高近一倍。随着稠密程度降低、稀疏化程度增加,在组维度为1或32时,针对EfficientNet或MobileNet,IPU对比GPU展现出巨大优势,做到成倍的性能提升,同时时延大大降低。
创新架构需要软硬协同设计
IPU所采用的片上存储架构,确实是未来计算结构的发展方向之一,但从芯片设计和应用角度而言,这是一大挑战。片上存储通常有两种架构,一是在片上规划单块大规模的存储,这种方式通常会导致良品率极低。另一种架构就是Graphcore这样的分布式片上存储架构。但这又带来了新的挑战:如何把分布式存储架构有效利用起来?这对编译器的要求非常高,可以说是软件、硬件协同设计的过程。要做出能够真正落地的产品,最核心的挑战就是软硬件两方面的专业知识和经验。
为了提升芯片的可用性,以及便于用户和开发者更方便地在系统中进行开发、移植、优化,Graphcore将产品扩展到囊括庞大的部署软件和基础架构套件,通过Poplar SDK给用户提供更好的体验。而这通常是头部厂商如英伟达在推进GPU大规模应用时才有的举动。
Poplar SDK是架构在机器学习上的框架软件(比如TensorFlow、ONNX、PyTorch和PaddlePaddle)和硬件之间的一个基于计算图的整套工具链和库。Poplar SDK支持容器化部署,能够快速启动并运行。在标准生态方面,Poplar SDK支持Docker、Kubernetes、以及微软的Hyper-v等虚拟化技术和安全技术。在操作系统方面,Poplar SDK目前支持最主要的三个Linux发行版:ubuntu、RedHat Enterprise Linux、CentOS。
今年5月,Graphcore还推出了PopVision Graph Analyser分析工具,用户可以通过这个可视化的图形展示工具来分析软件运行情况、调试效率。
目前基于IPU的一些应用已覆盖到机器学习的各个应用领域,包括自然语言处理、图像/视频处理、时序分析、推荐/排名及概率模型。一些应用案例和模型已经在TensorFlow、ONNX和Graphcore的PopART上可用,所有源代码都可以在GitHub处下载。
新冠疫情下“小兵”立大功
当前,全球都希望更高效地攻克新冠疫情中的难题。这时,AI在高清医学影像领域就体现出了重要价值。第一,疫情发展非常快,不断有新的病例、影像和数据产生,这就要求现有的模型要不断根据新的情况来提高精度。
第二,疫情造成全球医疗资源紧缺。放射影片往往需要富有经验的医生进行判断,而在资源紧张的情况下,AI工具可以帮助更多医生获得更专业的判断力。
第三,全球都迫切需要攻克病毒的研究成果,如何提高研究效率至关重要。
Graphcore中国销售总监朱江,就本文开头所提到的微软训练CXR(胸部X光射线检查)的应用案例,详细介绍了IPU与英伟达 V100的对比情况。
朱江
Graphcore中国销售总监
Graphcore中国销售总监
微软专门开发了SONIC CV模型进行训练,IPU和GPU的训练结果对比如下图:左边是训练时间,IPU优势明显。右边红色曲线代表训练时精度上升的情况,蓝色曲线代表测试精度。可以看到测试精度和训练精度较为接近甚至吻合,这也说明SONIC模型在泛化性能上更好,在针对未知的新数据方面,其处理能力比微软传统的EfficientNet模型更好。整体上,SONIC的模型通过30分钟的训练达到94%的训练精度和测试精度,训练速度方面,IPU需要30分钟,而GPU差不多需要5个小时。
通过这一训练,微软认为能够训练到SOTA的精度的模型不一定是大模型,可以用小模型来达到这样的精度要求。另外,IPU的MIMD架构非常适用于以分组卷积为代表的新模型。
据了解,目前微软已采用IPU来进行计算机视觉中分类方面的训练,能达到一个数量级的速度提升。未来,微软期望把IPU在CV领域的应用扩展到更多方面,包括监测、分割以及配准。
创新带给Graphcore的底气
迄今为止,Graphcore获得了AI领域多位重量级人物的背书。英国半导体之父、Arm联合创始人Hermann爵士认为:“在计算机历史上只发生过三次革命,一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。”意指其率先提出了为AI计算而生的IPU。
AI教父Geoff Hinton教授在接受Wired采访时,被问到 “我们应该如何构建功能更像大脑的机器学习系统”时,从钱包中掏出了一个又大又亮的硅片,并回答说:“我们需要转向不同类型的计算机来处理新的机器学习系统。”他认为Graphcore的IPU正在满足这样的系统需求。
迄今为止,Graphcore总融资超过4.5亿美金,其中包括全球知名的金融投资者和战略投资者。
不论是技术本身所带来的创新地位,还是大佬的站台或融资历程,Graphcore的履历都堪称漂亮。
不过,作为一家初创企业,Graphcore直面的都是业界巨擘。强如英伟达,也已经感受了种种威胁,正在加速创新。上个月,英伟达推出了基于Ampere架构的NVIDIA A100,将AI训练和推理性能提高20倍,可以说是英伟达GPU迄今为止最大的性能飞跃。
对于未来的竞争,Graphcore方面信心满满。卢涛表示,虽然目前对比的都是与V100这样的大量部署的旗舰级产品,但即使是第一代IPU产品也不会输于A100,且下一代IPU处理器也将有重磅发布。
未来的推进策略,Graphcore还是会在训练和推理两方面并行,聚焦对高精度、低时延、高吞吐量要求更高的场景。另外还有一个趋势是训练和推理混布的需求,例如视频平台、电商网站等希望通过算法同时进行训练和推理,能够根据用户数据实时更新算法模型;未来的汽车应用也是训练和推理混布的场景,都将有一定的增长。
积极拥抱中国AI生态圈
在中国,Graphcore刚与两大头部客户有了重大进展。一是阿里巴巴新的开放式深度学习API ODLA(Open Deep Learning API)支持Graphcore IPU,某种程度上,这也反映了数据中心对IPU的计算需求正在增长。
二是成为百度飞桨(PaddlePaddle)硬件生态圈共建计划伙伴之一,这一合作使Graphcore进入了中国深度学习开源框架的生态系统中,触及百万以上的AI开发者。
卢涛表示,Graphcore正在积极拥抱中国的AI生态圈,中国市场未来有望占据其全球市场的40%甚至50%。
本文由电子发烧友网原创,未经授权禁止转载。如需转载,请添加微信号elecfans999.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
华裔天才少年Alexandr Wang创办硅谷AI独角兽2021-04-30 5373
-
华捷艾米评为AI领域的独角兽企业代表2020-09-25 3973
-
218家独角兽企业,引领中国新经济发展2020-08-21 3482
-
求职必知独角兽公司排行榜2020-06-18 3966
-
揭开深记忆示波器的神秘面纱2019-09-23 1267
-
估值40亿美金的旷视科技申请IPO AI独角兽上市潮到来2019-08-26 5949
-
这家AI芯片独角兽吊打英伟达,吹捧还是硬实力?2019-07-02 759
-
中国AI芯片独角兽吊打英伟达 吹捧还是硬实力2019-05-12 3194
-
独角兽企业代表了新兴产业的发展方向,地方大力扶持独角兽2018-06-27 4052
-
人工智能独角兽宣布:发布全球首款面向IoT的AI芯片2018-06-07 1233
-
“硬独角兽”的培养困境2018-05-11 1871
-
独角兽企业是什么意思_中国的独角兽公司都分布在哪些行业呢?2018-04-19 196963
-
AI独角兽的IPO猜想2018-04-02 12295
-
胡润研究院首次发布独角兽指数 蚂蚁金服小米名列前茅2017-12-21 1042
全部0条评论

快来发表一下你的评论吧 !
